
This article is for software developers, project managers, and technical leads who want to understand the SDLC coding phase to ensure efficient, high-quality software delivery. The SDLC coding phase is the stage in the Software Development Life Cycle (SDLC) where your project transitions from design documents to actual, working software. If you’re searching for information about the SDLC coding phase, this guide confirms the topic and provides a comprehensive overview of what happens during this critical stage, who is involved, and which best practices and tools are essential for success.
The SDLC coding phase is when developers convert software design into code, following best practices such as adhering to coding standards, using version control, conducting code reviews, writing clean and maintainable code, ensuring modularity for scalability, performing unit testing, documenting code, and leveraging CI/CD for automation.
The Software Development Life Cycle (SDLC) consists of seven essential phases: Planning, Requirements Analysis, Design, Coding, Testing, Deployment, and Maintenance. The SDLC is the backbone of modern software development, providing a structured approach for development teams to transform ideas into high quality software products. The SDLC outlines a series of well-defined phases—planning, requirements gathering, design, coding, testing, deployment, and maintenance—that guide the software development process from start to finish. By following the development life cycle SDLC, organizations can manage complexity, align with business objectives, and ensure that the final product meets user expectations.
A disciplined SDLC helps development teams minimize risks, control costs, and deliver reliable software that stands up to real-world demands. Whether you’re building a new SaaS platform or enhancing an existing system, a robust software development life cycle ensures that every stage of the development process is accounted for, resulting in software that is both functional and maintainable throughout its software development life.
With a clear understanding of the SDLC’s structure, let’s explore the different models used to implement these phases.
Selecting the right SDLC model is a critical decision that shapes the entire software development process. There are several popular SDLC models, each designed to address different project needs and team dynamics:
Choosing the right SDLC model depends on factors like project complexity, team size, stakeholder involvement, and the need for adaptability. For example, the agile model is often preferred for complex projects where requirements may evolve, while the Waterfall model can be effective for projects with stable, well-understood requirements. Understanding the strengths and limitations of different sdlc models helps teams select the right SDLC methodology for their unique context.
With an understanding of SDLC models, let's focus on the coding phase and its role in the software development process.
The Coding phase in the Software Development Life Cycle (SDLC) is when engineers and developers start converting the software design into tangible code.
The coding phase transforms design artifacts—architecture diagrams, API contracts, and database schemas—into working software components. This is the development stage where abstract concepts become executable code that users can interact with. At this stage, developers translate the system design into actual code, ensuring that the software functions as intended. The coding phase focuses on transforming key components of the system design into reliable, maintainable, and efficient working software.
Key activities during the SDLC coding phase include adhering to coding standards, utilizing version control, and conducting thorough AI-assisted code reviews to ensure quality.
Before writing code begins, the coding phase depends on validated requirements and approved designs. During the Coding phase, developers use an appropriate programming language to write the code, guided by the Software Design Document (SDD) and coding guidelines. Software developers need clear inputs: system architecture documentation, data flow diagrams, API specifications, and detailed component designs. Without these, teams risk building features that don’t match project requirements.
Once implementation wraps up, the coding phase feeds directly into the testing phase and deployment phase through:
The development phase serves dual purposes. It’s both a production step where software development teams write code and a critical feedback point. During implementation, developers often discover design gaps, requirement ambiguities, or technical constraints that weren’t visible during planning. This makes the coding phase essential for risk assessment and continuous improvement throughout all SDLC phases.
Now that we’ve defined the coding phase and its importance, let’s look at how to prepare for successful implementation.
Strong preparation during late design and early implementation reduces costly rework. For projects kicking off in Q1 2025, getting this foundation right determines whether your team delivers high quality software on schedule.
Before any developer opens their IDE, these artifacts must exist:
Development teams need alignment on how they’ll work together:
Before coding starts, every developer needs:
A team is “ready to code” when any developer can clone the repository, run the build, and execute tests within 30 minutes of setup.
With preparation complete, let’s examine the core activities that define the coding phase.
The coding phase isn’t just writing code—it’s a structured set of activities spanning design refinement to integration. Software engineering practices have evolved significantly, and modern coding involves collaboration, automation, and continuous validation.
Typical development process tasks include:
The organization of these tasks can vary depending on the software development model chosen. Different software development models, such as Waterfall, Agile, or DevOps, influence how the coding phase is structured, managed, and integrated with other SDLC stages.
A typical daily developer workflow looks like this:
How coding is organized depends on your software development methodology:
Large features must be decomposed into manageable pieces. A feature like “User account management” planned for a 2025 release breaks down into:
Each component becomes a user story with acceptance criteria and technical subtasks tracked in project management tools like Jira, Azure Boards, or Linear.
Estimation practices help teams plan sprints effectively:
Project managers use these estimates to balance workload across the team and ensure the project scope remains achievable within the timeline, feeding directly into effective sprint planning and successful sprint reviews in Agile teams.
The tech stack is typically established during the design phase, but concrete framework choices often get finalized during coding. Teams evaluate options based on:
These aren’t exhaustive catalogs—the right choice depends on your project requirements and team capabilities and should align with broader SDLC best practices for software development.
Modern applications follow layered architectures that separate concerns:
When implementing a use case like “customer places an order on 1 July 2025,” developers translate requirements into concrete code:
Throughout this process, it is essential to validate the software's functionality to ensure that the implemented features meet user needs and perform efficiently, supported by practices such as static code analysis for early defect detection.
Design patterns support clean implementation:
This separation of concerns creates loosely coupled architecture where changes in one layer don’t cascade unpredictably through the system.
With the core activities outlined, let’s look at the tools and environments that support efficient coding.
Modern coding relies heavily on tooling for productivity, traceability, and software quality. The right tools can dramatically accelerate the software development process while maintaining code quality.
Reproducible environments matter. Using Docker Compose files, dev containers, or infrastructure-as-code ensures every developer works in conditions matching staging and the production environment, complementing collaborative workflows built around pull requests for code review and integration and AI-augmented remote code review practices.
Git-based workflows are central to the coding phase, enabling development and operations teams to work in parallel without conflicts.
GitFlow Strategy
Trunk-Based Development
A typical feature branch workflow:
Best practices include small, focused commits with clear messages, frequent integration to avoid merge conflicts, and branch protection rules preventing direct pushes to main.
CI servers automatically build and test code whenever developers push changes. Popular platforms include GitHub Actions, GitLab CI, Jenkins, and Azure DevOps, all of which are covered in depth in guides to the best CI/CD tools for 2024.
A typical CI pipeline executes these steps:
The benefit is earlier detection of integration issues. Teams catch broken builds, failing tests, and security vulnerabilities before code reaches shared branches—preventing the accumulation of defects that become expensive to fix bugs later.
CI connects the coding phase to subsequent SDLC steps like the corresponding testing phase and deployment, while keeping focus on developer workflows and fast feedback loops.
With the right tools in place, let’s examine how quality is built into the coding phase.
Much of software quality is built during coding, not only caught in later testing phases. Industry data shows that 70% of software failures trace back to poor coding standards, making quality practices during implementation essential.
Quality assurance activities embedded in coding include:
Organizations in 2024-2025 increasingly integrate security checks directly into coding workflows through DevSecOps practices. This includes SAST scanning and dependency vulnerability checks running automatically on every commit and reflects a broader shift toward an AI-driven SDLC across all lifecycle phases and the adoption of AI-powered developer productivity toolchains.
The pull request workflow is the primary mechanism for quality control and directly influences cycle time and pull request review duration:
Review criteria include:
Practical guidelines for effective reviews:
Research shows that implementing version control systems with proper review processes reduced merge conflicts by 70% in multi-team enterprise projects.
The “shift-left” approach means developers write tests alongside or before implementation, catching defects when they’re cheapest to fix. Studies indicate that unit testing during development yields 60-80% bug preemption before system testing.
Test types relevant to the coding phase:
High-quality code includes automated tests committed with the implementation. Teams should perform unit testing as part of their Definition of Done, targeting coverage above 80% for critical business logic.
Static analysis tools enforce coding standards and identify potential issues without running code:
Security-focused tools integrated into coding workflows, alongside broader code quality and maintainability practices, strengthen overall software resilience:
Security testing plays a critical role in the SDLC coding phase by identifying vulnerabilities such as system weaknesses, data breaches, and authentication flaws. It is integrated throughout development, often using automated processes like penetration testing and vulnerability scanning, and is a key part of DevSecOps practices.
These tools help teams address SDLC address security concerns early. Organizations define quality gates—minimum coverage percentages, zero critical vulnerabilities—that must pass before merging.
This approach helps deliver software that remains functional and secure throughout its lifecycle, supporting ongoing maintenance with fewer defects reaching the production environment. Documentation of code and architecture is necessary to ensure long-term maintainability.
With quality practices embedded, let’s see how AI and automation are reshaping the coding phase.
AI-assisted coding has become mainstream by 2024-2025, significantly impacting how software developers work. GitHub reports that tools like Copilot can automate approximately 40% of boilerplate code, freeing developers to focus on complex business logic and underscoring the need to follow AI coding impact metrics and best practices and assess top generative AI tools for developers.
AI capabilities in the coding phase include a growing ecosystem of AI coding assistants that boost development efficiency and AI-driven development platforms that unify engineering data and workflows:
Benefits are significant: faster delivery, reduced manual work on repetitive tasks, and accelerated onboarding for new team members, particularly in distributed teams that rely on AI-powered remote review workflows. However, risks require attention:
AI tools accelerate coding but don’t replace developer judgment. Every suggestion requires evaluation before integration.
Concrete scenarios where AI assists during the SDLC coding phase:
Generating Initial Implementations
A developer writes a function signature and docstring describing the expected behavior. AI suggests the complete implementation, which the developer reviews and refines.
Scaffolding REST Endpoints
Given an OpenAPI specification, AI tools can generate controller stubs, request/response DTOs, and basic validation logic—saving hours of repetitive coding.
Prototyping UI Components
Describing a component’s requirements in natural language yields initial React or Vue component code, including styling and event handlers.
Test Case Suggestions
Based on function signatures and existing tests, AI suggests additional test cases covering edge conditions the developer might overlook.
Refactoring Assistance
During an April 2025 sprint, AI identifies duplicate logic across multiple services and suggests extracting it into a shared utility, complete with migration steps.
All AI output requires review for correctness, performance, licensing compliance, and security before merging. User feedback on AI suggestions helps improve accuracy over time.
With automation and AI accelerating development, let’s see how Agile methodology shapes the coding phase.
Agile methodology has transformed the coding phase of the SDLC by introducing flexibility, collaboration, and a relentless focus on continuous improvement. In Agile, the coding phase is organized into short, time-boxed sprints—typically lasting one to four weeks—where development teams tackle a prioritized set of user stories or features. This approach enables teams to deliver working software incrementally, gather user feedback early, and adapt quickly to changing requirements, especially when combined with lean SDLC practices tailored for startups.
During each sprint, developers collaborate closely, write and refactor code, and perform frequent code reviews to maintain high software quality. Continuous integration and automated testing are integral, ensuring that new code is always production-ready and that bugs are caught early. Agile methodology encourages open communication, regular retrospectives, and iterative enhancements, empowering development teams to improve their processes and outcomes with every sprint. By embracing Agile in the coding phase, organizations can reduce risk, accelerate delivery, and consistently meet customer expectations.
With Agile practices in mind, let’s consider how to deliver scalable software.
Delivering scalable software is essential for organizations aiming to support growth and adapt to changing user demands. Achieving scalable software delivery requires careful attention to system architecture, infrastructure, and robust testing practices throughout the software development process.
A well-architected system lays the foundation for scalability, enabling applications to handle increased traffic and data volumes without sacrificing performance. Leveraging modern infrastructure solutions—such as cloud platforms, containerization, and orchestration tools—gives development teams the flexibility to scale resources up or down as needed. Comprehensive testing, including load and performance testing, ensures that the software remains reliable under varying conditions.
Incorporating DevOps practices like continuous integration and continuous deployment (CI/CD) further streamlines the development process, allowing teams to deliver updates rapidly and with confidence. By prioritizing scalability from the outset, development teams can build software that not only meets current requirements but is also prepared for future growth, ensuring a seamless experience for users and stakeholders alike.
With scalability addressed, let’s look at how the coding phase transitions to testing and deployment.
The coding phase doesn’t end when code compiles—it ends when code is integrated, tested, and ready for formal QA and release. The testing process depends on quality handover from development. Key components such as source code, documentation, test cases, and deployment scripts must be provided to the testing team to ensure a smooth transition.
The goal of the testing phase is to identify and fix bugs, ensuring the software operates as intended before being deployed to users.
Software development teams must provide:
Successful CI builds are promoted through environments:
Feature flags and configuration toggles enable teams to deploy code to production while selectively enabling functionality. This supports scalable software delivery where the final product can be released incrementally.
This approach aligns with customer expectations by enabling faster delivery while maintaining control over feature rollout and supporting customer feedback cycles.
With the handover complete, let’s examine common pitfalls and how to avoid them.
Many SDLC failures trace back to poor practices in the coding phase rather than pure technical limitations. Focusing on the quality of the actual code is crucial to avoid common pitfalls that can lead to costly issues later. Understanding common pitfalls helps teams avoid expensive rework.
In the prevention strategies subsection, it's important to note that proper modular coding allows for easier scalability and future feature additions.
In late 2024, a development team bypassed code review to meet a deadline, introducing a regression bug that affected payment processing. The fix required emergency deployment, customer communication, and three days of recovery effort—far exceeding the time a proper review would have taken.
The maintenance phase inherits whatever quality the coding phase produces. Software projects that cut corners during implementation pay multiples later in support costs, with maintenance potentially consuming 60% of total lifecycle budgets.
Following a structured approach to risk analysis during coding helps identify issues before they reach the testing deployment and maintenance phases.
With pitfalls addressed, let’s conclude with the importance of a strong coding phase in the SDLC.
The coding phase is where requirements and design finally become working software artifacts. It’s the pivotal development stage where planning meets reality, transforming business objectives into the software’s functionality that serves users. Ongoing maintenance is essential to ensure the software remains functional and continues to operate effectively after deployment.
Disciplined coding practices—supported by modern tooling, AI assistance, comprehensive testing, and rigorous reviews—reduce risk and accelerate the entire process. Teams that invest in quality during implementation spend less time fixing bugs in testing and maintenance.
Continuous maintenance is necessary to ensure software remains functional and meets evolving user needs after deployment. The maintenance phase in the Software Development Life Cycle (SDLC) is characterized by constant assistance and improvement, ensuring the software's best possible functioning and longevity. Ongoing support during the maintenance phase addresses issues, applies updates, and adds new features to the software. This phase also involves responding to user feedback, resolving unexpected issues, and upgrading the software based on evolving requirements. Maintenance tasks include frequent software updates, implementing patches, and fixing bugs to ensure software longevity. User support is a crucial component of the maintenance phase, offering help and guidance to users facing difficulties with the software. The maintenance phase is essential for safeguarding the longevity of any piece of software, similar to maintaining a house over time.
View coding not as an isolated activity but as an integrated, collaborative phase connected to planning, design, testing, deployment and maintenance, and operations. The right sdlc model for your organization balances structure with flexibility, enabling software development teams to deliver consistently.
Looking forward, the SDLC coding phase will continue evolving. AI-augmented development, shift-left security practices, and continuous delivery techniques will reshape how traditional software development approaches complex projects. Teams that embrace these changes while maintaining fundamental engineering discipline will build the high quality software that meets customer expectations and supports system performance at scale.
The key components of the SDLC—including planning, design, coding, testing, deployment, and maintenance—work together to deliver high-quality software. Each phase plays a vital role, and ongoing maintenance ensures the software remains functional, secure, and aligned with user needs throughout its lifecycle.
Start by evaluating your current coding practices against the checklists in this article. Choose one area—whether it’s improving code reviews, adding static analysis, or integrating AI tools—and implement it in your next sprint. Incremental improvements compound into significant gains across your software development lifecycle.
If you’ve searched for “burn ups,” chances are you’re either tracking a software project or diving into nuclear engineering literature. This guide explains Agile project management.
Another common Agile project tracking tool is the burn down chart, which is often compared to burn up charts. We'll introduce the basic principles of burn down charts and discuss how they differ from burn up charts later in this guide.
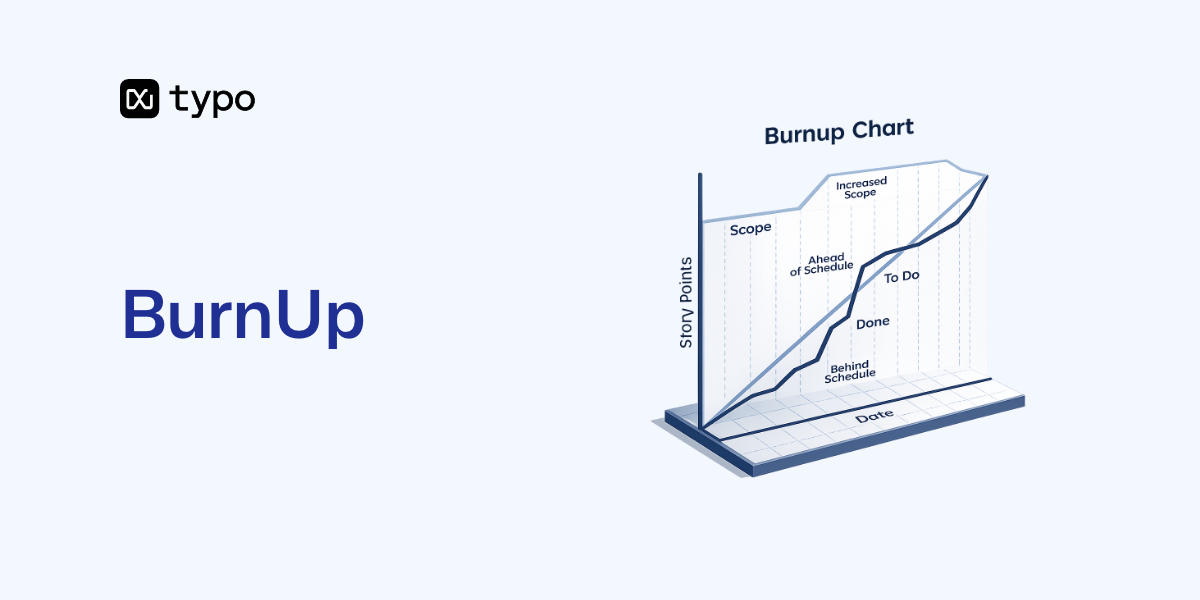
A burn up chart is a visual tool that tracks completed work against total scope over time. Scrum and Kanban teams use it to visualize how close they are to finishing a release, sprint, or project. Unlike a burndown chart that starts high and decreases, a burn up chart starts at zero and rises as the team delivers. A burn down chart visualizes the remaining work over time, starting with the total scope and decreasing as work is completed, and is especially useful for projects with fixed scope.
A typical Agile burn up chart displays two lines on the same graph:
Teams measure progress using various units depending on their workflow, and the choice between story points vs. hours for estimation affects how you interpret the chart:
The horizontal axis typically shows time in days, weeks, or sprints. For example, a product team might configure their x axis to display 10 two-week sprints spanning Q2 through Q4 2025.
Visual elements of an effective burn up chart:
Figure 1: A sample burn up chart for a 6-sprint mobile app project would show a scope line starting at 100 story points, rising to 120 in sprint 3, with the progress line climbing from 0 to meet it by sprint 6.
Burn up charts are favored in Agile environments because they make project progress, scope changes, and completion forecasts visible at a glance. When stakeholders ask “how much work is left?” or “are we going to hit the deadline?”, a burn up chart answers both questions without lengthy explanations.
Key benefits of using burn up charts:
Realistic usage scenarios:
Burn up vs. burndown: key distinction
For a deeper dive into a complete guide to burndown charts, you can explore how they complement burn up charts in Agile tracking.
Prefer burnups when your scope evolves, your team does discovery-heavy work, or you’re managing long-running product roadmaps. A simple burndown may suffice for fixed-scope, short-lived projects like one sprint or a small feature.
The process of creating a burn up chart works across spreadsheets (Excel, Google Sheets) and Agile tools like Jira, Azure DevOps, and ClickUp. These steps are tool-agnostic, so you can apply them anywhere.
Step-by-step process:
Example with actual numbers: Your team begins a release with 120 story points planned. By sprint 3, new regulatory requirements add 30 points, pushing total scope to 150. Your burn up chart shows the scope line jumping from 120 to 150 at the sprint 3 boundary. Meanwhile, your completed work line has reached 45 points. The visual immediately shows stakeholders why the remaining work increased—without making your team look slow.
Configuring a burn up report in Agile tools:
Visual design tips:
Your team should be able to set up a basic burn up chart in under an hour, whether using a spreadsheet template or a built-in tool report.
Reading a burn up chart means understanding what each line, gap, and slope tells you about delivery risk, progress velocity, and scope changes. Once you know the patterns, the chart becomes a powerful forecasting tool.
Understanding the axes:
Interpreting the gap: The space between the scope line and the completed work line at any date represents work remaining. For example:
If your team maintains velocity at 25 points per sprint, you can project completion in two more sprints, assuming you understand how to use Scrum velocity as a planning metric rather than a rigid performance target.
Common patterns and their meanings:
Walkthrough example: Consider a 10-week web redesign project with 150 story points in scope. By week 3, the team has completed only 20 points—well below the ideal pace line that projected 45. The burn up chart makes this gap obvious. After the team removes a critical impediment (switching a blocked vendor integration), velocity doubles. By week 8, completed work reaches 140 points, nearly catching the scope line.
When patterns indicate risk—like a widening gap heading into a November 2025 release—the chart supports practical decisions: renegotiating scope with stakeholders, adding resources, or adjusting the delivery date.
Both burnup charts and burndown charts track progress over time, but they show it from opposite perspectives. A burn up chart displays completed work rising toward scope. A burndown chart displays work remaining falling toward zero.
Key differences:
Concrete example:
When to choose each chart:
Some teams use both charts side by side in Jira or Azure DevOps. This can provide comprehensive views, but teams should agree on which chart serves as the “single source of truth” for status reports and stakeholder communication, while using iteration burndown charts for sprint-level insight.
Burn up charts work at the sprint level, but their real power emerges when applied to releases and multi-team portfolios spanning several quarters.
Release forecasting with projection lines:
Portfolio burn up charts:
Caveats for forecasting:
Advanced setups might integrate burn up charts with other metrics like cycle time, work-in-progress limits, or defect rates, or combine them with additional engineering progress tracking tools such as Kanban boards and dashboards. However, keep the chart itself simple and readable—additional complexity belongs in separate reports.
While burn up charts are invaluable in Agile project management, the term “burnup” also plays a critical role in nuclear engineering, which we’ll explore next.
Update frequency depends on your workflow. For sprints, updating at the end of each day during stand-ups provides early warning of issues. For releases spanning multiple sprints, updating at sprint boundaries often suffices. Kanban teams typically update daily since they don’t have sprint boundaries.
Absolutely. In Kanban, configure the horizontal axis as calendar days rather than discrete sprints. Plot cumulative completed work daily against your target scope. The cumulative flow diagram offers complementary insights, but a burn up chart still works for visualizing progress toward a goal.
Persistent scope growth signals either poor initial estimation, stakeholder pressure, or unclear project boundaries. Use the burn up chart as evidence in stakeholder conversations. Show how each scope increase pushes out the projected completion date, then negotiate trade-offs: add resources, extend timelines, or cut lower-priority features.
Track at both levels if possible. Sprint-level burn up charts help the team during daily stand-ups. Release-level charts inform product managers and stakeholders about overall trajectory. Most Agile tools support both views from the same underlying data.
If your completed work line is tracking parallel to or above an ideal pace line connecting your start point to the target end date, you’re on track. If the gap between your progress line and scope line is shrinking at your current velocity, you should meet the deadline.
For Agile teams:
Start by creating a burn up chart for your next sprint. Watch how making scope and progress visible transforms your team’s conversations—and your ability to deliver on time.

Scrum metrics are quantifiable data points that enable agile teams to measure team performance, track sprint effectiveness, and evaluate delivery quality through transparent, data-driven insights. These specific data points form the backbone of empirical process control within the scrum framework, allowing your development team to inspect and adapt their work systematically.
Direct answer: Scrum metrics are measurements like velocity, sprint burndown, and cycle time that help agile teams track progress, identify bottlenecks, and drive continuous improvement in their development process. These key metrics originated from Lean manufacturing principles and were adapted for iterative software development to address the unpredictability of knowledge work.
By the end of this guide, you will:
Scrum metrics are specific data points that scrum teams track and use to improve efficiency and effectiveness.
Scrum metrics are specific measurements within the scrum framework that track sprint performance, team capacity, and delivery effectiveness. Unlike traditional waterfall metrics focused on time and cost adherence, scrum metrics prioritize team-level empiricism—transparency, inspection, and adaptation—measuring sustainable pace and flow rather than individual productivity.
These agile metrics matter because they provide the visibility needed for cross functional teams to make informed decisions during scrum events like sprint planning, daily standups, and sprint reviews. When your agile team lacks clear measurements, improvements become guesswork rather than targeted action.
Key scrum metrics operate within fixed sprint timeboxes, typically two to four weeks. This cadence creates natural measurement opportunities during sprint planning, where teams measure capacity, and retrospectives, where teams analyze what the data reveals about their development process.
Sprint-based measurement creates a rhythm for tracking agile metrics. Each sprint boundary becomes a data collection point, allowing scrum teams to compare performance across iterations and identify trends that inform future sprints.
Scrum metrics measure collective team output rather than individual productivity. This distinction is critical—velocity is explicitly team-specific and not meant for cross-team comparisons. When organizations misuse metrics to compare agile practitioners across different teams, they distort estimates and erode trust.
Team performance indicators connect directly to sprint-based measurement cycles. Your team delivers work within sprints, and the metrics provide insights into how effectively that collective effort translates to completed user stories and sprint goals.
Metrics support the inspect-and-adapt principles central to agile frameworks. Rather than serving as performance judgment tools, well-implemented scrum metrics drive continuous improvement by revealing patterns and opportunities.
Tracking metrics over time helps identify areas where process changes could improve team effectiveness. A stable trend indicates predictability, increasing trends signal growing capability, while decreasing or erratic patterns flag estimation issues, impediments, or external factors requiring investigation.
Essential metrics for scrum teams fall into three categories based on their focus: sprint execution, quality assurance, and team health. Many agile teams make the mistake of tracking too many metrics simultaneously—focusing on the right combination based on your current challenges yields better outcomes than comprehensive but overwhelming dashboards.
Velocity measures the amount of work a team can complete during a single sprint. It quantifies team capacity by summing the story points of completed work items per sprint. If your team delivers 15, 22, and 18 story points across three sprints, your average velocity is approximately 18 points. This average guides sprint planning to prevent overcommitment and enables release forecasting.
Calculate velocity by tracking remaining story points at sprint end: only fully completed items count toward velocity. Teams typically average the last three to four sprints for forecasting reliability, as this smooths out natural variation.
Sprint Burndown Chart visualizes daily work completion against the sprint plan and helps track progress. Sprint burndown charts plot remaining work against time, creating a visual representation of the team’s progress toward sprint goals. The ideal trajectory runs from total commitment to zero as a straight line, while the actual line—updated daily—reveals real progress. Sprint burndown charts expose risks like flat lines indicating blockages, upward spikes showing scope creep, or steep drops signaling strong momentum.
Story completion ratio measures delivered user stories against committed ones. Completing eight of ten committed stories yields 80% completion. This metric reveals planning accuracy without story points granularity and proves particularly useful for early-stage teams refining their estimation practices.
Throughput is the number of work items completed per sprint, reflecting team output consistency.
Cycle Time measures the duration for a task to progress from "in progress" to "done." Lead Time is the total time from when a request is created until it is delivered. These flow metrics expose efficiency opportunities and help teams measure cycle time improvements over successive sprints.
Escaped defects measure how many bugs or defects were not caught during testing and were found by customers after the release. This indicates gaps in your quality assurance process and Definition of Done. Mature teams target trends below 5% of delivered stories. Defect removal efficiency calculates the percentage of bugs caught before release—aiming for 95% or higher signals a robust testing practice.
Technical Debt Index quantifies suboptimal code that requires future remediation. It balances speed by tracking time spent on debt repayment versus new features. Mature products typically allocate 10-20% of capacity to technical debt management, though this varies based on product age and market pressures.
Team satisfaction surveys and team happiness assessments capture the human factors that predict sustainable delivery. Low team morale correlates with increased turnover and declining productivity—making these leading indicators of future performance problems.
Sprint goal success rate tracks the percentage of sprints where the defined goal is fully achieved. High rates around 85-90% build stakeholder trust, while patterns below 70% highlight overcommitment, unclear acceptance criteria, or unrealistic goals. This outcome-oriented metric aligns with the 2020 Scrum Guide’s emphasis on goals over story completion.
Workload distribution analysis reveals whether work in progress spreads evenly across team members. Concentration of work creates bottlenecks and burnout risks that undermine the team’s success over time.
Customer satisfaction score and net promoter score validate that your team delivers genuine business value. As the ultimate outcome metric, customer satisfaction connects engineering efforts to the organizational mission.
Work in Progress (WIP) tracks the number of items being worked on simultaneously to identify bottlenecks.
Context matters when selecting which metrics to track. A newly-formed agile team benefits from different measurements than a mature team optimizing for flow. Your implementation approach should match your team’s experience level and the specific challenges you face managing complex projects.
Teams should begin formal metric tracking after establishing basic scrum practices—typically after three to four sprints of working together. Premature measurement creates noise without actionable signal.
Define measurement objectives aligned with sprint goals and team challenges—determine whether you’re solving for predictability, quality, or team efficiency.
Select three to five core metrics to avoid measurement overload; start with velocity plus sprint burndown, then add others as these stabilize.
Establish baseline measurements over two to three sprints before attempting to interpret trends or set improvement targets.
Integrate metric reviews into existing scrum ceremonies—sprint reviews for stakeholder-facing metrics, retrospectives for team-focused measurements.
Create action plans based on metric trends and outliers, focusing on one to two improvements per sprint.
Automate collection through development tool integrations to minimize manual tracking overhead.
Teams measure what matters to their current situation. If predictability is your challenge, prioritize sprint execution metrics. If defects keep escaping, focus on quality metrics. If turnover threatens team capacity, measure team health first.
Integrate metric collection with existing development tools like Jira, GitLab, or dedicated engineering intelligence platforms. Manual data entry creates friction that leads to incomplete tracking—automation ensures consistent measurement without burdening team members.
Cumulative flow diagrams visualize how many tasks move through workflow stages over time, exposing bottlenecks through widening bands and throughput through slopes. Modern tools generate these automatically from ticket status changes, providing flow insights without additional tracking effort.
Dashboard creation should follow the principle of surfacing decisions, not just data. An effective agile coach helps teams configure views that prompt action rather than passive observation.
Teams implementing scrum metrics consistently encounter several obstacles. Understanding these challenges in advance helps you navigate them effectively and maintain measurement practices that improve team effectiveness rather than undermine it.
When metrics connect to performance evaluations or bonuses, teams naturally optimize for the measurement rather than the underlying goal. Story points inflate, easy work gets prioritized, and the metrics lose their diagnostic value.
Solution: Focus on trends over absolute numbers and combine multiple complementary metrics to prevent single-metric optimization. Emphasize that metrics exist to help the team improve, not to judge individual contributors. Never compare velocity across different scrum teams—it’s explicitly not designed for this purpose.
Some organizations attempt to track every possible metric simultaneously, creating dashboard overload that prevents actionable interpretation. When everything seems important, nothing gets the attention it deserves.
Solution: Start with three core metrics, establish consistent measurement cadence, and add new metrics only when existing ones are stable and generating insights. Resist pressure to expand tracking until your current metrics drive visible improvements.
Incomplete ticket updates, inconsistent story point assignments, and irregular measurement timing corrupt your data and make trend analysis unreliable.
Solution: Automate data collection through development tool integrations wherever possible. Establish clear metric definitions with the entire development team during retrospectives, ensuring everyone understands what each measurement captures and how to contribute accurate data.
Some team members view metrics with suspicion, fearing surveillance or unfair evaluation. This resistance undermines adoption and can poison team dynamics.
Solution: Involve the team in metric selection from the start. Emphasize improvement over performance evaluation—make it clear that metrics identify pain points in processes, not problems with people. Share positive outcomes from metric-driven changes to demonstrate value and build trust.
Effective scrum metrics drive sprint predictability, quality delivery, and team satisfaction without creating measurement burden. The key insight across all agile methodologies is that metrics serve teams, not the reverse—they provide the transparency needed for informed decisions while respecting sustainable pace.
Research shows that approximately 70% of agile teams track velocity and burndown charts, but only 40% effectively leverage flow metrics like cumulative flow diagrams. High-performing teams achieve 90% sprint goal success rates through consistent, metric-informed empiricism.
Immediate actions to implement:
Related areas to explore include DORA metrics for broader delivery performance measurement, value stream management for end-to-end visibility across your software development lifecycle, and engineering intelligence platforms that automate tracking and surface insights through AI-assisted analysis. As teams mature, flow metrics and throughput measurements increasingly complement traditional velocity tracking.
Metric Calculation Quick Reference:
Scrum Ceremony Integration Checklist:
Recommended Tools by Team Size:
Typo's sprint analysis focuses on leveraging key scrum metrics to enhance team productivity and project outcomes. By systematically tracking sprint performance, Typo ensures that its agile team remains aligned with sprint goals and continuously improves their development process.

Typo emphasizes several essential scrum metrics during sprint analysis:
Typo integrates sprint metrics reviews into regular scrum ceremonies, such as sprint planning, daily standups, sprint reviews, and retrospectives. By combining quantitative data with team feedback, Typo identifies pain points and adapts workflows accordingly.
This data-driven approach supports transparency and fosters a culture of continuous improvement. Typo’s agile coach facilitates discussions around metrics to help the team focus on actionable insights rather than blame, promoting psychological safety and collaboration.
Typo leverages integrated tools to automate data collection from project management systems, reducing manual effort and improving data accuracy. Visualizations like burndown charts and cumulative flow diagrams provide real-time insights into sprint progress and flow stability.
Through disciplined sprint analysis and metric tracking, Typo has achieved improved predictability in delivery, higher product quality, and enhanced team morale. The focus on relevant scrum metrics enables Typo’s development team to make informed decisions, optimize workflows, and consistently deliver value aligned with customer satisfaction goals.

Accelerate metrics are the four key performance indicators that measure software delivery performance and operational excellence across engineering organizations. These research-backed DevOps metrics have become widely recognized as the gold standard for evaluating how effectively teams deliver software and respond to production challenges.
This guide covers DORA metrics implementation, measurement strategies, and practical applications for engineering teams seeking to improve their software delivery process. The target audience includes Engineering leaders, VPs of Engineering, Development Managers, and teams actively using Git, CI/CD pipelines, and SDLC tools who want to gain valuable insights into their development process efficiency.
Accelerate metrics are Deployment Frequency, Lead Time for Changes, Change Failure Rate, and Mean Time to Recovery—proven performance indicators that measure how effectively organizations deliver software while maintaining stability and quality.
By the end of this guide, you will understand:
Accelerate metrics are research-backed key performance indicators developed by the DevOps Research and Assessment (DORA) team to quantify software delivery capabilities. These four key performance indicators provide a balanced view of both velocity and stability, enabling teams to make data-driven decisions about their development process improvements.
The four key Accelerate metrics are deployment frequency, lead time for changes, change failure rate, and time to restore service.
Rather than measuring output like lines of code or commit counts, these metrics focus on outcomes that correlate directly with organizational performance and business value delivery.
The significance of Accelerate metrics stems from extensive research conducted across thousands of global organizations. The accelerate metrics originate from extensive research conducted by Dr. Nicole Forsgren, Jez Humble, and Gene Kim, spanning rigorous research involving over 39,000 professionals across thousands of companies worldwide. This work, published through annual State of DevOps reports and the influential 2018 book “Accelerate: The Science of Lean Software and DevOps,” established the statistical connection between software delivery performance and business outcomes.
Organizations that excel in these DevOps metrics are 2.5 times more likely to exceed profitability targets and demonstrate significantly higher market share growth. This research shifted the industry focus from anecdotal DevOps practices to data-driven measurement of what actually predicts high performing organizations.
Accelerate and DORA metrics are interchangeable terms referring to the same four key metrics for measuring delivery performance. Accelerate metrics are also referred to as DORA metrics, named after the DevOps Research and Assessment Group. The terms are often used synonymously because the DORA team’s research formed the empirical foundation for the Accelerate book’s conclusions.
These metrics fit within broader engineering intelligence initiatives focused on SDLC visibility and operational performance measurement. Understanding how they connect to developer experience frameworks like SPACE helps teams address both the strengths of quantitative measurement and the qualitative aspects of team productivity.
With this foundation established, let’s examine why these specific four metrics were chosen and how each measures a different aspect of the software development lifecycle.
Each accelerate metric captures a distinct dimension of software delivery performance. Two focus on velocity (how fast teams can deliver changes), while two measure stability (how reliable those changes are). Together, they prevent teams from optimizing speed at the expense of quality or vice versa.
Deployment frequency measures how often an organization successfully releases to production.
Deployment frequency measures how often an organization successfully releases code to production or makes changes available to end users. This metric directly reflects a team’s ability to deliver software incrementally and respond quickly to market changes.
High performing teams achieve frequent deployments—often multiple times per day—enabling rapid iteration based on customer feedback. Low performing teams may deploy only once every few months, limiting their responsiveness to user expectations and competitive pressures. High deployment frequency indicates mature DevOps practices including continuous integration, automated testing, and streamlined workflows that reduce friction in the release process.
Lead time for changes defines the time it takes from code committed to code in production.
Lead time for changes tracks the elapsed time from when a developer commits code to when that code runs successfully in production. This metric reveals the efficiency of your entire delivery pipeline, from development through testing to deployment.
Elite teams achieve lead times of less than one hour, reflecting highly automated processes and minimal manual handoffs. Low performing teams often experience lead times stretching to months due to bottlenecks like manual approvals, lengthy testing cycles, or siloed operations teams. Reducing lead time enables faster delivery of new features and bug fixes, directly impacting customer satisfaction.
Change failure rate measures the percentage of deployments that cause a failure in production.
Change failure rate measures the percentage of deployments that result in degraded service, service impairment, or require immediate remediation such as rollbacks or hotfixes. This stability metric indicates the quality and reliability of your deployment practices.
High performing organizations maintain failure rates between 0-15%, demonstrating mature practices like automated testing, canary releases, and feature flags. When failures occur at higher rates (46-60% for low performers), teams spend excessive time on failed deployment recovery time rather than delivering business value. This metric encourages practices that catch issues before they reach production.
Time to restore service measures how long it takes to recover from a failure or incident in production.
Mean time to recovery (MTTR), also called time to restore service, measures how quickly teams can restore service after a production incident or deployment failure. This metric acknowledges that failures will happen and focuses on resilience rather than prevention alone.
Elite teams restore service in less than one hour through robust observability, chaos engineering practices, and well-rehearsed incident response procedures. Low performing teams may take weeks to recover, significantly impacting customer satisfaction and revenue. MTTR reflects both technical capabilities and organizational readiness to respond when problems arise.
These four core metrics create a balanced scorecard that accelerate metrics provide for understanding both speed and stability. With this framework established, let’s explore practical approaches to implementing measurement in your organization.
Moving from understanding accelerate metrics to actually measuring and improving them requires thoughtful integration with your existing development tools and processes. The insights gained from tracking metrics only deliver value when connected to actionable improvement initiatives.
Establishing accurate baseline measurements is essential before pursuing improvement goals. Without reliable data, teams cannot make informed decisions about where to focus their continuous improvement efforts.
Integrating analytics tools with your SDLC platforms enables automated data collection that surfaces actionable insights without burdening development teams with administrative overhead.
These benchmarks, derived from DevOps research across thousands of organizations, serve as directional goals rather than absolute targets. Context matters—a heavily regulated environment may have legitimate reasons for longer lead times due to compliance requirements.
Use benchmarking to identify which metrics represent your biggest opportunities for improvement rather than trying to optimize all four simultaneously. Teams often find that improving one metric (like reducing change failure rate through better testing) naturally improves others (like reducing MTTR because issues are simpler to diagnose).
Organizations implementing accelerate metrics frequently encounter predictable obstacles. Understanding these challenges in advance helps teams establish sustainable measurement practices that drive continuous improvement rather than creating dysfunction.
Many organizations struggle with fragmented toolchains where deployment data, incident records, and code repositories exist in separate systems with no unified view.
Implement engineering intelligence platforms that automatically aggregate data from multiple SDLC tools and provide unified dashboards. These platforms eliminate manual tracking overhead and ensure consistent measurement across various aspects of the delivery pipeline.
When metrics are tied to performance evaluation, teams may artificially inflate deployment frequency by splitting changes into tiny increments or misclassifying incidents to improve MTTR numbers.
Foster psychological safety and focus on team-level improvements rather than individual performance to prevent metric manipulation. Position metrics as diagnostic tools for identifying improvement opportunities, not as evaluation criteria. Involve adopting a culture where metrics reveal problems to solve rather than performance to judge.
Different teams often interpret “deployment,” “failure,” and “incident” differently, making organization-wide comparisons meaningless and preventing accurate benchmarking against DevOps report standards.
Establish organization-wide standards for deployment, failure, and incident definitions with clear documentation and training. Create shared runbooks that define when an event qualifies for each category, ensuring the metrics provide valuable insights that are comparable across the organization.
Some teams resist measurement programs, fearing they will be used punitively or that the overhead will slow down delivery of high quality software.
Emphasize metrics as tools for continuous improvement rather than performance evaluation and involve teams in goal-setting processes. When teams participate in defining targets and improvement approaches, they take ownership of outcomes. Demonstrate early wins by connecting metric improvements to reduced technical debt and improved developer experience.
With these challenges addressed proactively, teams can build sustainable metrics programs that deliver long-term value for DevOps performance optimization.
Accelerate metrics are proven indicators of software delivery excellence that predict organizational performance and business outcomes. By measuring deployment frequency, lead time for changes, change failure rate, and mean time to recovery, engineering leaders gain the visibility needed to drive meaningful improvements in their software development processes.
High performing teams using these metrics achieve 25% faster delivery while maintaining or improving software quality—demonstrating that speed and stability are complementary rather than competing goals.
Immediate next steps to implement accelerate metrics:
Related topics worth exploring include the SPACE framework for understanding developer productivity beyond delivery metrics, cycle time analysis for deeper pipeline optimization, and measuring the impact of AI code review tools on software quality and delivery performance.
When exploring SDLC models, it's important to understand that each model represents a distinct approach to software development, offering unique structures and levels of flexibility tailored to different project requirements. This guide is intended for project managers, software developers, and stakeholders involved in software development projects. Understanding SDLC models is crucial for these audiences because selecting the right model can directly impact project success, efficiency, risk management, and the ability to meet business goals.
This page will compare and explain the most common SDLC models, such as Waterfall, Agile, Spiral, V-Model, and others, helping you identify which SDLC model best fits your team's needs. Whether you're a project manager, developer, or stakeholder, you'll gain clarity on the strengths and limitations of each approach, enabling more informed decisions throughout your software development process.
Software development is the process of designing, creating, testing, and maintaining software applications or systems.
The Software Development Life Cycle (SDLC) concept refers to a structured process that guides the planning, creation, and maintenance of a software product. SDLC methodology outlines the distinct phases and structured approach used to manage and control a software development project, ensuring that project goals, scope, and requirements are clearly defined and met. Software development models, such as Agile or Waterfall provide structured frameworks within the SDLC for managing each stage of the software development project, from initiation to deployment and maintenance.
The software development life cycle (SDLC) is built around a series of well-defined phases, each designed to guide teams toward delivering high quality software in a structured and predictable manner. Understanding these phases is essential for effective project management and for ensuring that software development efforts align with business goals and user needs.
By following these SDLC phases, organizations can manage software development projects more effectively, reduce risks, and deliver solutions that meet both business and technical expectations.
With an understanding of the key phases, let's explore the main SDLC models and how they structure these phases.
SDLC models can be broadly categorized into two main types: sequential and iterative. Sequential models, such as the Waterfall model, follow a linear progression through defined phases. Iterative models, like Agile and Spiral, allow for repeated cycles of development and refinement. It is important to note that there are different SDLC models, each with its own strengths and weaknesses, making them suitable for various project needs.
Among the popular SDLC models are Waterfall, Agile, Spiral, and the V-model. These are just a few examples, as various SDLC models exist to address different project requirements, timelines, budgets, and team expertise. The V-model, also known as a validation model, is a variation of the waterfall methodology that emphasizes verification and validation by associating each development stage with a corresponding testing phase throughout the SDLC.
Additionally, hybrid and risk-driven variants combine elements from multiple models to better suit complex or evolving project demands. Selecting the appropriate SDLC model—or even a hybrid approach—depends on the unique needs and constraints of each software development project.
Now, let's take a closer look at the most popular SDLC models and their characteristics.
Here’s a quick summary of the most popular SDLC models, their definitions, and their typical project scope fits:
Glossary Notes:
For more details on less common SDLC models, see our SDLC Glossary (reference link or appendix).
Selecting the right SDLC model is crucial for project success. The choice should be based on factors like project complexity, risk level (high risk vs. low risk projects), and the need for flexibility or documentation. Using the appropriate model helps ensure quality, timely delivery, budget adherence, and stakeholder satisfaction.
Transitioning from model overviews, let's examine each model in more detail.
The Waterfall model is a classic example of a linear SDLC model. In the Waterfall model, each phase—requirements, design, implementation, testing, deployment, and maintenance—must be completed before the next phase begins. This sequential approach makes the process predictable and easy to manage, especially when requirements are well understood from the start.
The Waterfall model is ideal for projects with the following characteristics:
However, the Waterfall model has some notable drawbacks:
With a clear understanding of the Waterfall model, let's move on to iterative and adaptive approaches.
The Iterative model is based on the concept of iterative development, where the software is built and improved through repeated cycles. Each iteration involves planning, design, implementation, and testing, allowing teams to refine the product incrementally.
A typical iteration lasts between two to six weeks, but the length can be adjusted based on project needs. Shorter iterations enable more frequent assessment of development progress and allow teams to respond quickly to changes.
It is crucial to gather and incorporate customer feedback at the end of each iteration. This feedback helps shape project requirements, prioritize tasks, and ensures the final product aligns with user needs. By continuously monitoring development progress and integrating customer feedback, teams can make necessary adjustments and deliver a product that meets stakeholder expectations.
Next, let's look at Agile, a popular iterative model.
Agile SDLC Model
The Agile SDLC model is designed to accommodate change and the need for flexibility in modern software projects. It is particularly suitable for managing software projects where requirements may evolve over time. Agile emphasizes collaboration among team members and stakeholders, ensuring continuous feedback and alignment throughout the development process.
Agile organizes work into short, iterative cycles called sprints (see glossary note above), allowing teams to deliver functional software quickly and adapt to changing needs. Regular stakeholder involvement is recommended, with reviews and feedback sessions at the end of each sprint to ensure the project stays on track and meets user expectations.
Popular Agile frameworks include Scrum, Kanban, and Extreme Programming (XP). Extreme Programming is known for its focus on iteration, pair programming, and test-driven development, making it highly responsive to change and effective within the broader Agile ecosystem.
Having covered Agile, let's explore models that emphasize risk management and validation.
The Spiral model emphasizes risk assessment in every development cycle, making risk analysis a key activity at each stage. It instructs teams to map risk checkpoints and integrate risk management strategies throughout the process. This approach is particularly suitable for projects with high risk and significant project complexity, as it allows for continuous evaluation and adjustment. The model also recommends the use of prototypes (see glossary note above) in each spiral to address uncertainties and validate requirements early.
Now, let's examine the V-Model, which focuses on verification and validation.
The V-Model, also known as the V-shaped model, is a type of verification and validation model. It extends the traditional waterfall approach by pairing each development phase with a corresponding testing activity, creating a structured and hierarchical process. In this model, testing phases run in parallel with development stages, allowing for rigorous and early detection of errors. Formal test plans are recommended early in the process, ensuring that each phase is thoroughly verified and validated. This makes the V-shaped model especially suitable for regulated projects or those requiring high-quality, error-free software.
Next, let's review models designed for rapid delivery and modular development.
Rapid Application Development (RAD) is an SDLC model that prioritizes rapid prototyping actions, enabling teams to quickly build and refine working versions of the software. RAD is particularly effective for complex projects that require frequent adjustments and rapid delivery, as it allows for iterative development and continuous user involvement. Teams are advised to establish strong user-feedback loops to ensure the evolving product meets requirements. However, caution should be exercised regarding scalability risks, as RAD may not be suitable for very large-scale systems without careful planning.
Incremental Model is an SDLC approach that delivers software in modular increments, each building on the previous. This model is ideal for projects with evolving requirements and a need for early partial releases. It recommends priority-based increment planning, allowing teams to focus on delivering the most valuable features first and adapt to changes as the project progresses.
Big Bang Model is an SDLC model characterized by minimal planning, where development starts with little or no requirements definition. It is typically used for small, low risk projects with minimal planning. The approach is simple but carries high project risk and is not recommended for complex or large projects.
DevOps is an SDLC approach that promotes CI/CD pipeline integration, with continuous delivery being a key practice. Continuous Integration/Continuous Delivery (CI/CD) refers to the ongoing, automated process of integrating code changes and deploying software updates. DevOps also requires a cultural and organizational shift, fostering collaboration and shared responsibility between development and operations teams. This shift impacts the entire organizational mindset and structure, encouraging teams to communicate openly and adopt new practices that improve efficiency and automation.
Teams are encouraged to suggest cross-team collaboration practices and include monitoring and feedback automation to ensure rapid response to issues and continuous improvement.
With a comprehensive understanding of the main SDLC models, let's compare their strengths and tradeoffs.
When comparing popular SDLC models, it's important to understand the key phases that structure each development process. Each model organizes the software lifecycle into distinct stages, such as requirements gathering, design, development, testing, deployment, and maintenance. The way these key phases are sequenced and emphasized can significantly impact project flexibility, cost, time-to-market, and the overall quality of the final product.
Below is a comparison table outlining the tradeoffs between major SDLC models:
Note: Some less common models may not be included in this table. For a full glossary, see SDLC Glossary. For insights on common challenges and how to address them, see understanding the hurdles in sprint reviews.
Understanding these tradeoffs will help you align your project needs with the most suitable SDLC model.
Clearly defining your project scope is essential to ensure that the chosen SDLC model aligns with customer expectations and addresses stakeholder needs. The following steps can help guide your selection process:
By grouping these considerations, you can make a more informed decision about which SDLC model best fits your project.
With your project scope and constraints in mind, let's move on to the practical steps for selecting an SDLC model.
Selecting the right SDLC model involves a structured approach. Use the following checklist to guide your decision:
Following these steps will help ensure a transparent and justifiable model selection process.
Once you've selected a model, the right tools and techniques can further support your SDLC implementation.
To support each phase of the software development life cycle, teams rely on a variety of tools and techniques that streamline the software development process and enhance overall quality. These tools are important because they help automate tasks, improve collaboration, and ensure consistency and traceability throughout each SDLC phase—especially for readers unfamiliar with software development tooling.
Project Management Tools: Solutions like Jira, Trello, and Asana help teams plan, track progress, and manage tasks throughout the development process. These tools facilitate collaboration, ensure accountability, and provide visibility into project status.
Requirements Management Tools: Tools such as Confluence and IBM DOORS assist in capturing, organizing, and tracking project requirements. They help ensure that all stakeholder needs are documented and addressed during the development life cycle sdlc.
Design and Modeling Tools: Software like Lucidchart, Figma, and Enterprise Architect enable teams to create visual representations of system architecture, workflows, and user interfaces. These tools support clear communication and help prevent design misunderstandings.
Development and Version Control Tools: Integrated development environments (IDEs) such as Visual Studio Code and Eclipse, along with version control systems like Git, streamline coding, code review, and collaboration among software developers.
Testing and Quality Assurance Tools: Automated testing frameworks (e.g., Selenium, JUnit) and continuous integration platforms (e.g., Jenkins, Travis CI) help teams conduct thorough testing, catch defects early, and maintain high code quality throughout the software development process.
Deployment and Monitoring Tools: Solutions like Docker, Kubernetes, and platform engineering tools such as New Relic or Datadog support automated deployment, scalability, and real-time performance monitoring, ensuring smooth transitions from development to production.
Collaboration and Communication Tools: Platforms like Slack, Microsoft Teams, and Zoom foster effective communication among distributed development and operations teams, supporting agile methodologies and continuous improvement.
By leveraging these SDLC tools and techniques, organizations can optimize each stage of the development process, improve collaboration, and deliver high quality software that meets user and business requirements.
With the right tools in place, let's look at best practices for implementing your chosen SDLC model.
By structuring your implementation approach, you can maximize the benefits of your chosen SDLC model.
Next, let's consider risk, compliance, and maintenance factors that can impact your project's long-term success.
Addressing these considerations will help safeguard your project against unforeseen challenges.
Now, let's see how these models work in practice through real-world case studies.
These case studies provide practical insights into the strengths and limitations of each SDLC model.
To wrap up, let's summarize key recommendations and next steps for adopting the right SDLC model.
By following these recommendations, you can confidently select and implement the SDLC model that best fits your project's unique needs.

Modern software teams face a paradox: they have more data than ever about their development process, yet visibility into the actual flow of work—from an idea in a backlog to code running in production—remains frustratingly fragmented. Value stream management tools exist to solve this problem.
Value stream management (VSM) originated in lean manufacturing, where it helped factories visualize and optimize the flow of materials. In software delivery, the concept has evolved dramatically. Today, value stream management tools are platforms that connect data across planning, coding, review, CI/CD, and operations to optimize flow from idea to production. They aggregate signals from disparate systems—Jira, GitHub, GitLab, Jenkins, and incident management platforms—into a unified view that reveals where work gets stuck, how long each stage takes, and what’s actually reaching customers.
Unlike simple dashboards that display metrics in isolation, value stream management solutions provide end to end visibility across the entire software delivery lifecycle. They surface flow metrics, identify bottlenecks, and deliver actionable insights that engineering leaders can use to make data driven decision making a reality rather than an aspiration. Typo is an AI-powered engineering intelligence platform that functions as a value stream management tool for teams using GitHub, GitLab, Jira, and CI/CD systems—combining SDLC visibility, AI-based code reviews, and developer experience insights in a single platform.
Why does this matter now? Several forces have converged to make value stream management VSM essential for engineering organizations:
Key takeaways:
The most mature software organizations have shifted their focus from “shipping features” to “delivering measurable customer value.” This distinction matters. A team can deploy code twenty times a day, but if those changes don’t improve customer satisfaction, reduce churn, or drive revenue, the velocity is meaningless.
Value stream management tools bridge this gap by linking engineering work—issues, pull requests, deployments—to business outcomes like activation rates, NPS scores, and ARR impact. Through integrations with project management systems and tagging conventions, stream management platforms can categorize work by initiative, customer segment, or strategic objective. This visibility transforms abstract OKRs into trackable delivery progress.
With Typo, engineering leaders can align initiatives with clear outcomes. For example, a platform team might commit to reducing incident-driven work by 30% over two quarters. Typo tracks the flow of incident-related tickets versus roadmap features, showing whether the team is actually shifting its time toward value creation rather than firefighting.
Centralizing efforts across the entire process:
The real power emerges when teams use VSM tools to prioritize customer-impacting work over low-value tasks. When analytics reveal that 40% of engineering capacity goes to maintenance work that doesn’t affect customer experience, leaders can make informed decisions about where to invest.
Example: A mid-market SaaS company tracked their value streams using a stream management process tied to customer activation. By measuring the cycle time of features tagged “onboarding improvement,” they discovered that faster value delivery—reducing average time from PR merge to production from 4 days to 12 hours—correlated with a 15% improvement in 30-day activation rates. The visibility made the connection between engineering metrics and business outcomes concrete.
How to align work with customer value:
A value stream dashboard presents a single-screen view mapping work from backlog to production, complete with status indicators and key metrics at each stage. Think of it as a real time data feed showing exactly where work sits right now—and where it’s getting stuck.
The most effective flow metrics dashboards show metrics across the entire development process: cycle time (how long work takes from start to finish), pickup time (how long items wait before someone starts), review time, deployment frequency, change failure rate, and work-in-progress across stages. These aren’t vanity metrics; they’re the vital signs of your delivery process.
Typo’s dashboards aggregate data from Jira (or similar planning tools), Git platforms like GitHub and GitLab, and CI/CD systems to reveal bottlenecks in real time. When a pull request has been sitting in review for three days, it shows up. When a service hasn’t deployed in two weeks despite active development, that anomaly surfaces.
Drill-down capabilities matter enormously. A VP of Engineering needs the organizational view: are we improving quarter over quarter? A team lead needs to see their specific repositories. An individual contributor wants to know which of their PRs need attention. Modern stream management software supports all these perspectives, enabling teams to move from org-level views to specific pull requests that are blocking delivery.
Comparison use cases like benchmarking squads or product areas are valuable, but a warning: using metrics to blame individuals destroys trust and undermines the entire value stream management process. Focus on systems, not people.
Essential widgets for a modern VSM dashboard:
Typo surfaces these value stream metrics automatically and flags anomalies—like sudden spikes in PR review times after introducing a new process or approval requirement. This enables teams to catch process improvements before they plateau.
DORA (DevOps Research and Assessment) established four key metrics that have become the industry standard for measuring software delivery performance: deployment frequency, lead time for changes, mean time to restore, and change failure rate. These metrics emerged from years of research correlating specific practices with organizational performance.
Stream management solutions automatically collect DORA metrics without requiring manual spreadsheets or data entry. By connecting to Git repositories, CI/CD pipelines, and incident management tools, they generate accurate measurements based on actual events—commits merged, deployments executed, incidents opened and closed.
Typo’s approach to DORA includes out-of-the-box dashboards showing all four metrics with historical trends spanning months and quarters. Teams can see not just their current state but their trajectory. Are deployments becoming more frequent while failure rates stay stable? That’s a sign of genuine improvement efforts paying off.
For engineering leaders, DORA metrics provide a common language for communicating performance to business stakeholders. Instead of abstract discussions about technical debt or velocity, you can report that deployment frequency increased 3x between Q1 and Q3 2025 while maintaining stable failure rates—a clear signal that continuous delivery investments are working.
DORA metrics are a starting point, not a destination. Mature value stream management implementations complement them with additional flow, quality, and developer experience metrics.
How leaders use DORA metrics to drive decisions:
See engineering metrics for a boardroom perspective.
Combining quantitative data (cycle time, failures) with qualitative data (developer feedback, perceived friction) gives a fuller picture of flow efficiency measures. Numbers tell you what’s happening; surveys tell you why.
Typo includes developer experience surveys and correlates responses with delivery metrics to uncover root causes of burnout or frustration. When a team reports low satisfaction and analytics reveal they spend 60% of time on incident response, the path forward becomes clear.
Value stream analytics is the analytical layer on top of raw metrics, helping teams understand where time is spent and where work gets stuck. Metrics tell you that cycle time is 8 days; analytics tells you that 5 of those days are spent waiting for review.
When analytics are sliced by team, repo, project, or initiative, they reveal systemic issues. Perhaps one service has consistently slow reviews because its codebase is complex and few people understand it. Maybe another team’s PRs are oversized, taking days to review properly. Or flaky tests might cause deployment failures that require manual intervention. Learn more about the limitations of JIRA dashboards and how integrating with Git can address these systemic issues.
Typo analyzes each phase of the SDLC—coding, review, testing, deploy—and quantifies their contribution to overall cycle time. This visibility enables targeted process improvements rather than generic mandates. If review time is your biggest constraint, doubling down on CI/CD automation won’t help.
Analytics also guide experiments. A team might trial smaller PRs in March-April 2025 and measure the change in review time and defect rates. Did breaking work into smaller chunks reduce cycle time? Did it affect quality? The data answers these questions definitively.
Visual patterns worth analyzing:
The connection to continuous improvement is direct. Teams use analytics to run monthly or quarterly reviews and decide the next constraint to tackle. This echoes Lean thinking and the Theory of Constraints: find the bottleneck, improve it, then find the next one. Organizations that drive continuous improvement using this approach see 20-50% reductions in cycle times, according to industry benchmarks.
Typo can automatically spot these patterns and suggest focus areas—flagging repos with consistently slow reviews or high failure rates after deploy—so teams know where to start without manual analysis.
Value stream forecasting predicts delivery timelines, capacity, and risk based on historical flow metrics and current work-in-progress. Instead of relying on developer estimates or story point calculations, it uses actual delivery data to project when work will complete.
AI-powered tools analyze past work—typically the last 6-12 months of cycle time data—to forecast when a specific epic, feature, or initiative is likely to be delivered. The key difference from traditional estimation: these forecasts improve automatically as more data accumulates and patterns emerge.
Typo uses machine learning to provide probabilistic forecasts. Rather than saying “this will ship on March 15,” it might report “there’s an 80% confidence this initiative will ship before March 15, and 95% confidence it will ship before March 30.” This probabilistic approach better reflects the inherent uncertainty in software development.
Use cases for engineering leaders:
Traditional planning relies on manual estimation and story points, which are notoriously inconsistent across teams and individuals. Value stream management tools bring evidence-based forecasting using real delivery patterns—what actually happened, not what people hoped would happen.
Typo surfaces early warnings when current throughput cannot meet a committed deadline, prompting scope negotiations or staffing changes before problems compound.
Value stream mapping for software visualizes how work flows from idea to production, including the tools involved, the teams responsible, and the wait states between handoffs. It’s the practice that underlies stream visualization in modern engineering organizations.
Digital VSM tools replace ad-hoc whiteboard sessions with living maps connected to real data from Jira, Git, CI/CD, and incident systems. Instead of a static diagram that’s outdated within weeks, you have a dynamic view that reflects current reality. This is stream mapping updated for the complexity of modern software development.
Value stream management platforms visually highlight handoffs, queues, and rework steps that generate friction. When a deployment requires three approval stages, each creating wait time, the visualization makes that cost visible. When work bounces between teams multiple times before shipping, the rework pattern emerges. These friction points are key drivers measured by DORA metrics, which provide deeper insights into software delivery performance.
The organizational benefits extend beyond efficiency. Visualization creates shared understanding across cross functional teams, improves collaboration by making dependencies explicit, and clarifies ownership of each stage. When everyone sees the same picture, alignment becomes easier.
Example visualizations to describe: See the DORA Lab #02 episode featuring Marian Kamenistak on engineering metrics for insights on visualizing engineering performance data.
Visualization alone is not enough. It must be paired with outcome goals and continuous improvement cycles. A beautiful map of a broken process is still a broken process.
Software delivery typically has two dominant flows: the “happy path” (features and enhancements) and the “recovery stream” (incidents, hotfixes, and urgent changes). Treating them identically obscures important differences in how work should move.
A VSM tool should visualize both value streams distinctly, with different metrics and priorities for each. Feature work optimizes for faster value delivery while maintaining quality. Incident response optimizes for stability and speed to resolution.
Example: Track lead time for new capabilities in a product area—targeting continuous improvement toward shorter cycles. Separately, track MTTR for production outages in critical services—targeting reliability and rapid recovery. The desired outcomes differ, so the measurements should too.
Typo can differentiate incident-related work from roadmap work based on labels, incident links, or branches, giving leaders full visibility into where engineering time is really going. This prevents the common problem where incident overload is invisible because it’s mixed into general delivery metrics.
Mapping information flow—Slack conversations, ticket comments, documentation reviews—not just code flow, exposes communication breakdowns and approval delays. A pull request might be ready for review, but if the notification gets lost in Slack noise, it sits idle.
Example: A release process required approval from security, QA, and the production SRE before deployment. Each approval added an average of 6 hours of wait time. By removing one approval stage (shifting security review to an earlier, async process), the team improved cycle time by nearly a full day.
Typo correlates wait times in different stages—“in review,” “awaiting QA,” “pending deployment”—with overall cycle time, helping teams quantify the impact of each handoff. This turns intuitions about slow processes into concrete data supporting streamlining operations.
Handoffs to analyze:
Learn more about how you can measure work patterns and boost developer experience with Typo.
Visualizations and metrics only matter if they lead to specific improvement experiments and measurable outcomes. A dashboard that no one acts on is just expensive decoration.
The improvement loop is straightforward: identify constraint → design experiment → implement change for a fixed period (4-6 weeks) → measure impact → decide whether to adopt permanently. This iterative process respects the complexity of software systems while maintaining momentum toward desired outcomes.
Selecting a small number of focused initiatives works better than trying to improve everything at once. “Reduce PR review time by 30% this quarter” is actionable. “Improve engineering efficiency” is not. Focus on initiatives within the team’s control that connect to business value.
Actions tied to specific metrics:
Involve cross-functional stakeholders—product, SRE, security—in regular value stream reviews. Making improvements part of a shared ritual encourages cross functional collaboration and ensures changes stick. This is how stream management requires organizational commitment beyond just the engineering team.
Example journey: A 200-person engineering organization adopted a value stream management platform in early 2025. At baseline, their average cycle time was 11 days, deployment frequency was twice weekly, and developer satisfaction scored 6.2/10. By early 2026, after three improvement cycles focusing on review time, WIP limits, and deployment automation, they achieved 4-day cycle time, daily deployments, and 7.8 satisfaction. The longitudinal analysis in Typo made these gains visible and tied them to specific investments.
Selecting a stream management platform is a significant decision for engineering organizations. The right tool accelerates improvement efforts; the wrong one becomes shelfware.
Evaluation criteria:
Typo differentiates itself with AI-based code reviews, AI impact measurement (tracking how tools like Copilot affect delivery speed and quality), and integrated developer experience surveys—capabilities that go beyond standard VSM features. For teams adopting AI coding assistants, understanding their impact on flow efficiency measures is increasingly critical.
Before committing, run a time-boxed pilot (60-90 days) with 1-2 teams. The goal: validate whether the tool provides actionable insights that drive actual behavior change, not just more charts.
Homegrown dashboards vs. specialized platforms:
Ready to see your own value stream metrics? Start Free Trial to connect your tools and baseline your delivery performance within days, not months. Or Book a Demo to walk through your specific toolchain with a Typo specialist.
Weeks 1: Connect tools
Weeks 2-3: Baseline metrics
Week 4: Choose initial outcomes
Weeks 5-8: Run first improvement experiment
Weeks 9-10: Review results
Change management tips:
Value stream management tools transform raw development data into a strategic advantage when paired with consistent improvement practices and organizational commitment. The benefits of value stream management extend beyond efficiency—they create alignment between engineering execution and business objectives, encourage cross functional collaboration, and provide the visibility needed to make confident decisions about where to invest.
The difference between teams that ship predictably and those that struggle often comes down to visibility and the discipline to act on what they see. By implementing a value stream management process grounded in real data, you can move from reactive firefighting to proactive optimizing flow across your entire software delivery lifecycle.
Start your free trial with Typo to see your value streams clearly—and start shipping with confidence.
Value Stream Management (VSM) is a foundational approach for organizations seeking to optimize value delivery across the entire software development lifecycle. At its core, value stream management is about understanding and orchestrating the flow of work—from the spark of idea generation to the moment a solution reaches the customer. By applying value stream management VSM principles, teams can visualize the entire value stream, identify bottlenecks, and drive continuous improvement in their delivery process.
The value stream mapping process is central to VSM, providing a clear, data-driven view of how value moves through each stage of development. This stream mapping enables organizations to pinpoint inefficiencies, streamline operations, and ensure that every step in the process contributes to business objectives and customer satisfaction. Effective stream management requires not only the right tools but also a culture of collaboration and a commitment to making data-driven decisions.
By embracing value stream management, organizations empower cross-functional teams to align their efforts, optimize flow, and deliver value more predictably. The result is a more responsive, efficient, and customer-focused delivery process—one that adapts to change and continuously improves over time.
A value stream represents the complete sequence of activities that transform an initial idea into a product or service delivered to the customer. In software delivery, understanding value streams means looking beyond individual tasks or teams and focusing on the entire value stream—from concept to code, and from deployment to customer feedback.
Value stream mapping is a powerful technique for visualizing this journey. By creating a visual representation of the value stream, teams can see where work slows down, where handoffs occur, and where opportunities for improvement exist. This stream mapping process helps organizations measure flow, track progress, and ensure that every step is aligned with desired outcomes.
When teams have visibility into the entire value stream, they can identify bottlenecks, optimize delivery speed, and improve customer satisfaction. Value stream mapping not only highlights inefficiencies but also uncovers areas where automation, process changes, or better collaboration can make a significant impact. Ultimately, understanding value streams is essential for any organization committed to streamlining operations and delivering high-quality software at pace.
The true power of value stream management lies in its ability to connect day-to-day software delivery with broader business outcomes. By focusing on the value stream management process, organizations ensure that every improvement effort is tied to customer value and strategic objectives.
Key performance indicators such as lead time, deployment frequency, and cycle time provide measurable insights into how effectively teams are delivering value. When cross-functional teams share a common understanding of the value stream, they can collaborate to identify areas for streamlining operations and optimizing flow. This alignment is crucial for driving customer satisfaction and achieving business growth.
Stream management is not just about tracking metrics—it’s about using those insights to make informed decisions that enhance customer value and support business objectives. By continuously refining the delivery process and focusing on outcomes that matter, organizations can improve efficiency, accelerate time to market, and ensure that software delivery is a true driver of business success.
Adopting value stream management is not without its hurdles. Many organizations face challenges such as complex processes, multiple tools that don’t communicate, and data silos that obscure the flow of work. These obstacles can make it difficult to measure flow metrics, identify bottlenecks, and achieve faster value delivery.
Encouraging cross-functional collaboration and fostering a culture of continuous improvement are also common pain points. Without buy-in from all stakeholders, improvement efforts can stall, and the benefits of value stream management solutions may not be fully realized. Additionally, organizations may struggle to maintain a customer-centric focus, losing sight of customer value amid the complexity of their delivery processes.
To overcome these challenges, it’s essential to leverage stream management solutions that break down data silos, integrate multiple tools, and provide actionable insights. By prioritizing data-driven decision making, optimizing flow, and streamlining processes, organizations can unlock the full potential of value stream management and drive meaningful business outcomes.
Modern engineering teams that excel in software delivery consistently apply value stream management principles and foster a culture of continuous improvement. The most effective teams visualize the entire value stream, measure key metrics such as lead time and deployment frequency, and use these insights to identify and address bottlenecks.
Cross-functional collaboration is at the heart of successful stream management. By bringing together diverse perspectives and encouraging open communication, teams can drive continuous improvement and deliver greater customer value. Data-driven decision making ensures that improvement efforts are targeted and effective, leading to faster value delivery and better business outcomes.
Adopting value stream management solutions enables teams to streamline operations, improve flow efficiency, and reduce lead time. The benefits of value stream management are clear: increased deployment frequency, higher customer satisfaction, and a more agile response to changing business needs. By embracing these best practices, modern engineering teams can deliver on their promises, achieve strategic objectives, and create lasting value for their customers and organizations.
A value stream map is more than just a diagram—it’s a strategic tool that brings clarity to your entire software delivery process. By visually mapping every step from idea generation to customer delivery, engineering teams gain a holistic view of how value flows through their organization. This stream mapping process is essential for identifying bottlenecks, eliminating waste, and ensuring that every activity contributes to business objectives and customer satisfaction.
Continuous Delivery (CD) is at the heart of modern software development, enabling teams to release new features and improvements to customers quickly and reliably. By integrating value stream management (VSM) tools into the continuous delivery pipeline, organizations gain end-to-end visibility across the entire software delivery lifecycle. This integration empowers teams to identify bottlenecks, optimize flow efficiency measures, and make data-driven decisions that accelerate value delivery.
With VSM tools, engineering teams can automate the delivery process, reducing manual handoffs and minimizing lead time from code commit to production deployment. Real-time dashboards and analytics provide actionable insights into key performance indicators such as deployment frequency, flow time, and cycle time, allowing teams to continuously monitor and improve their delivery process. By surfacing flow metrics and highlighting areas for improvement, VSM tools drive continuous improvement and help teams achieve higher deployment frequency and faster feedback loops.
The combination of continuous delivery and value stream management VSM ensures that every release is aligned with customer value and business objectives. Teams can track the impact of process changes, measure flow efficiency, and ensure that improvements translate into tangible business outcomes. Ultimately, integrating VSM tools with continuous delivery practices enables organizations to deliver software with greater speed, quality, and confidence—turning the promise of seamless releases into a reality.
Organizations across industries are realizing transformative results by adopting value stream management (VSM) tools to optimize their software delivery processes. For example, a leading financial services company implemented value stream management VSM to gain visibility into their delivery process, resulting in a 50% reduction in lead time and a 30% increase in deployment frequency. By leveraging stream management solutions, they were able to identify bottlenecks, streamline operations, and drive continuous improvement across cross-functional teams.
In another case, a major retailer turned to VSM tools to enhance customer experience and satisfaction. By mapping their entire value stream and focusing on flow efficiency measures, they achieved a 25% increase in customer satisfaction within just six months. The ability to track key metrics and align improvement efforts with business outcomes enabled them to deliver value to customers faster and more reliably.
These real-world examples highlight how value stream management empowers organizations to improve delivery speed, reduce waste, and achieve measurable business outcomes. By embracing stream management and continuous improvement, companies can transform their software delivery, enhance customer satisfaction, and maintain a competitive edge in today’s fast-paced digital landscape.
Achieving excellence in value stream management (VSM) requires ongoing learning, the right tools, and access to a vibrant community of practitioners. For organizations and key stakeholders looking to deepen their expertise, a wealth of resources is available to support continuous improvement and optimize the entire value stream.
By leveraging these resources, organizations can empower cross-functional teams, break down data silos, and foster a culture of data-driven decision making. Continuous engagement with the VSM community and ongoing investment in stream management software ensure that improvement efforts remain aligned with business objectives and customer value—driving sustainable success across the entire value stream.
Software development life cycle phases are the structured stages that guide software projects from initial planning through deployment and maintenance. These seven key phases provide a systematic framework that transforms business requirements into high quality software while maintaining control over costs, timelines, and project scope.
Understanding and properly executing these phases ensures systematic, high-quality software delivery that aligns with business objectives and user requirements.
What This Guide Covers
This guide examines the seven core SDLC phases, their specific purposes and deliverables, and proven implementation strategies. We cover traditional and agile approaches to phase management but exclude specific programming languages, tools, or vendor-specific methodologies.
Who This Is For
This guide is designed for software developers, project managers, team leads, and stakeholders involved in software projects. Whether you’re managing your first software development project or looking to optimize existing development processes, you’ll find actionable frameworks for improving project outcomes.
Why This Matters
Proper SDLC phase execution reduces project risks by 40% according to industry research, ensures on-time delivery, and creates alignment between development teams and business stakeholders. Organizations following structured SDLC processes report 45% fewer critical defects compared to those using ad hoc development approaches.
What You’ll Learn:
Software development life cycle phases are structured checkpoints that transform business ideas into functional software through systematic progression. The SDLC is composed of distinct development stages, with each stage contributing to the overall process by addressing specific aspects of software creation, from requirements gathering to deployment and maintenance. Each development phase serves as a quality gate, ensuring that teams complete essential work before advancing to subsequent stages. The software development life cycle (SDLC) is used by software engineers to plan, design, develop, test, and maintain software applications.
Phase-based development reduces project complexity by breaking large initiatives into manageable segments. This structured process enables quality control at each stage and provides stakeholders with clear visibility into project progress and decision points.
The seven key phases interconnect through defined deliverables and feedback loops, where outputs from each previous phase become inputs for the following development stage.
Definition: The planning phase establishes project scope, objectives, and resource requirements through collaborative stakeholder analysis. This initial development stage defines what success looks like and creates the foundation for all project decisions.
Key deliverables: Project charter documenting business objectives, initial requirements gathering from stakeholders, feasibility assessment covering technical and financial constraints, and comprehensive resource allocation plans detailing team structure and timeline.
Connection to overall SDLC: This phase sets the foundation for all subsequent phases by defining measurable success criteria and establishing the framework for requirements analysis and system design.
Definition: The requirements analysis phase involves detailed gathering and documentation of functional and non-functional requirements that define what the software solution must accomplish.
Key deliverables: Software Requirement Specification document (SRS) containing detailed system requirements, user stories with acceptance criteria for agile development teams, system constraints covering performance and security needs, and traceability matrices linking requirements to business objectives.
Building on planning: This phase transforms high-level project goals from the planning phase into specific, measurable requirements that guide system design and development work.
Definition: The design phase creates technical blueprints that translate requirements into implementable system architecture, defining how the software solution will function at a technical level. At this stage, software engineering plays a critical role as the development team is responsible for building the framework, defining functionality, and outlining the structure and interfaces to ensure the software's efficiency, usability, and integration readiness.
Key deliverables: System architecture diagrams showing component relationships, database design with entity relationships and data flows, UI/UX mockups for user interfaces, and detailed technical specifications guiding implementation teams.
Unlike previous phases: This development stage shifts focus from defining “what” the system should do to designing “how” the system will work technically, bridging requirements and actual software development.
Transition: With design specifications complete, development teams can begin the implementation phase where designs become functional code.
The transition from design to development represents a critical shift where technical specifications guide the creation of actual software components, followed by systematic validation to ensure quality standards.
Definition: The implementation phase converts design documents into functional code using selected programming languages and development frameworks, transforming technical specifications into working software modules. AI can enhance the SDLC by automating repetitive tasks and predicting potential issues in the software development process.
Key activities: Development teams break down system modules into manageable coding tasks with clear deadlines and dependencies. Software engineers write code following established coding standards while implementing version control processes to maintain code quality and enable team collaboration. AI-powered code reviews can streamline review and feedback, and AI can generate reusable code snippets to assist developers.
Quality management: Code review processes ensure that multiple developers validate each component before integration, while continuous integration practices automatically test code changes as development progresses.
Definition: The testing phase provides systematic verification that software components meet established requirements through comprehensive unit testing, integration testing, system testing, and user acceptance testing. Software testing is a critical component of the SDLC, playing a key role in quality assurance and ensuring the reliability of the software before deployment.
Testing process: Quality assurance teams identify bugs through structured testing scenarios, document defects with reproduction steps, and collaborate with development teams to fix bugs identified during testing. This corresponding testing phase validates not only functional requirements but also performance benchmarks, security standards, security testing to identify vulnerabilities and ensure software robustness, and usability criteria.
Quality gates: Testing environment validation ensures software quality before any deployment to production environment, with automated testing frameworks providing continuous validation throughout development cycles.
Definition: The deployment phase manages the controlled release of tested software to production environments while minimizing disruption to existing users and business operations. The deployment phase involves rolling out the tested software to end users, which may include a beta-testing phase or pilot launch.
Release management: Deployment teams coordinate user training sessions, deliver comprehensive documentation for system administrators, and activate support systems to handle post-release questions and issues. The software release life cycle encompasses these stages, including deployment, continuous delivery, and post-release management, ensuring a structured approach to software launches.
Risk mitigation: Teams implement rollback procedures and monitoring systems to ensure post-deployment stability, with continuous delivery practices enabling rapid response to production issues.
Definition: The maintenance phase provides ongoing support through bug fixes, performance optimization, and feature enhancements based on user requirements and changing business needs.
Continuous improvement: Development teams integrate customer feedback into enhancement planning while maintaining system evolution strategies that adapt to new technologies and market requirements.
Long-term sustainability: This phase often consumes up to 60% of total software development lifecycle costs, making efficient maintenance processes critical for project success.
Transition: Different projects require varying approaches to executing these phases based on complexity, timeline, and organizational constraints.
Different software projects require tailored approaches to executing development life cycle phases, with various methodologies offering distinct advantages for specific project characteristics and team capabilities. Compared to other lifecycle management methodologies, SDLC provides a structured framework, but alternatives may emphasize flexibility, rapid iteration, or continuous delivery, depending on organizational needs and project goals.
Waterfall model approach: Linear progression through phases with formal quality gates and comprehensive documentation requirements at each stage. Traditional software development using this SDLC model works well for complex projects with stable requirements and regulatory compliance needs. Waterfall is ideal for smaller projects with well-defined requirements and minimal client involvement. The V-shaped model is best for time-limited projects with highly specific requirements prioritizing testing and quality assurance.
Agile methodology approach: Iterative process that compresses multiple phases into rapid development cycles called sprints, enabling development teams to respond quickly to changing customer expectations and market feedback. Agile is ideal for large, complex projects that require frequent changes and close collaboration with multiple stakeholders. The Iterative Model enables better control of scope, time, and resources, but it may lead to technical debt if errors are not addressed early.
Hybrid models: Many software development teams combine structured planning phases with flexible implementation approaches, maintaining comprehensive requirements analysis while enabling iterative development and continuous delivery practices.
DevOps** integration:** Modern development and operations teams break down traditional silos between development, testing, and deployment phases through automation and continuous collaboration throughout the development lifecycle. DevOps is perfect for teams seeking continuous integration and deployment in large projects, emphasizing long-term maintenance.
Continuous Integration/Continuous Deployment (CI/CD): These practices merge development phase work with testing and deployment activities, enabling rapid application development while maintaining software quality standards.
Quality gates: Development teams establish defined checkpoints that ensure phase completion criteria before progression, maintaining systematic control while enabling flexibility within individual phases.
Transition: Selecting the right approach requires careful assessment of project characteristics and organizational capabilities.
Leveraging continuous delivery methodologies represents a transformative paradigm shift within software development workflows that empowers development teams to deliver high-caliber software solutions through optimized velocity and precision. By streamlining and automating the building, testing, and deployment pipelines, continuous delivery ensures that every code modification undergoes rigorous validation processes and remains production-ready for rapid, reliable user deployment. This sophisticated approach minimizes manual intervention points, substantially reduces the probability of human-induced errors, and accelerates the feedback loop mechanisms between development teams and end-user constituencies.
Integrating continuous delivery frameworks into development workflows enables teams to respond dynamically to customer feedback patterns, adapt seamlessly to evolving requirement specifications, and maintain consistent improvement flows into production environments. This methodology proves particularly valuable in agile development ecosystems, where rapid iteration cycles and continuous enhancement processes are fundamental for satisfying dynamic customer expectations and market demands. By optimizing the development workflow architecture, continuous delivery not only enhances software quality metrics but also reinforces the overall organizational agility and responsiveness capabilities across development and operations teams.
For organizations seeking to optimize their software development lifecycle efficiency, continuous delivery serves as a critical enabler of streamlined, reliable, and customer-centric software delivery workflows that enhance productivity while maintaining superior quality standards.
Understanding project requirements and team capabilities enables informed decisions about which software development models will best support successful project delivery within specific organizational contexts.
When to use this: Project managers and technical leads can apply this framework when planning software development initiatives or optimizing existing development processes.
Organizations should select approaches based on project stability requirements, team experience, and customer feedback integration needs. Complex projects with regulatory requirements often benefit from traditional approaches, while software applications requiring market responsiveness work well with agile methodology.
Transition: Even with optimal methodology selection, specific challenges commonly arise during SDLC phase execution.
Harnessing the power of precise metrics has fundamentally reshaped how software development teams ensure they consistently deliver exceptional software that not only achieves ambitious business objectives but also exceeds customer expectations. Strategic performance indicators such as code quality, testing coverage, defect density, and customer satisfaction unlock unprecedented insights into the effectiveness and efficiency of development processes, creating a powerful foundation for continuous improvement.
Through systematic monitoring of these transformative metrics, development teams can uncover hidden opportunities for process optimization, strengthen cross-functional collaboration, and ensure their software development workflows consistently deliver exceptional value that resonates with customers and drives business success.
Leveraging a comprehensive toolkit has transformed how modern software development teams navigate every stage of the development process, ensuring the delivery of exceptional software solutions. These powerful tools reshape collaboration dynamics, streamline complex workflows, and provide unprecedented visibility into project trajectories.
Let's dive into how these essential tools optimize development processes and drive success across teams:
By harnessing these transformative tools, software development teams can optimize their entire development ecosystem, enhance cross-functional communication, and deliver robust, reliable software solutions that meet the demanding requirements of today's rapidly evolving technological landscape.
These challenges affect software project success regardless of chosen development lifecycle methodology, requiring proactive management strategies to maintain project momentum and software quality.
Solution: Implement formal change control processes with comprehensive impact assessment procedures that evaluate how requirement changes affect timeline, budget, and technical architecture decisions.
Development teams should establish clear stakeholder communication protocols and expectation management frameworks that document all requirement changes and their implications for subsequent development phases.
Solution: Establish automated testing frameworks during the design phase and define specific coverage metrics that ensure comprehensive unit testing, integration testing, and system testing throughout the development process.
Quality assurance teams should integrate test planning with development phase activities, creating testing environments that parallel production environment configurations and enable continuous validation of software components.
Solution: Create standardized handoff procedures with detailed deliverable checklists that ensure complete information transfer between development teams working on different SDLC phases.
Implement documentation standards that support effective collaboration between software engineers, project management teams, and stakeholders throughout the systems development lifecycle.
Transition: Addressing these challenges systematically creates the foundation for consistent project success.
Mastering software development life cycle phases provides the foundation for consistent, successful software delivery that aligns development team efforts with business objectives while maintaining high quality software standards throughout the development process. A system typically consists of integrated hardware and software components that work together to perform complex functions, and a structured SDLC is essential to ensure these components are effectively coordinated to achieve advanced operational goals.
To get started:
Related Topics: Explore specific SDLC models like the spiral model for high-risk projects, DevOps integration for continuous delivery, and lifecycle management methodologies that support complex software solutions requiring ongoing maintenance and evolution.

Software product metrics measure quality, performance, and user satisfaction, aligning with business goals to improve your software. This article explains essential metrics and their role in guiding development decisions.
Software product metrics are quantifiable measurements that assess various characteristics and performance aspects of software products. These metrics are designed to align with business goals, add user value, and ensure the proper functioning of the product. Tracking these critical metrics ensures your software meets quality standards, performs reliably, and fulfills user expectations. User Satisfaction metrics include Net Promoter Score (NPS), Customer Satisfaction Score (CSAT), and Customer Effort Score (CES), which provide valuable insights into user experiences and satisfaction levels. User Engagement metrics include Active Users, Session Duration, and Feature Usage, which help teams understand how users interact with the product. Additionally, understanding software metric product metrics in software is essential for continuous improvement.
Evaluating quality, performance, and effectiveness, software metrics guide development decisions and align with user needs. They provide insights that influence development strategies, leading to enhanced product quality and improved developer experience and productivity. These metrics help teams identify areas for improvement, assess project progress, and make informed decisions to enhance product quality.
Quality software metrics reduce maintenance efforts, enabling teams to focus on developing new features and enhancing user satisfaction. Comprehensive insights into software health help teams detect issues early and guide improvements, ultimately leading to better software. These metrics serve as a compass, guiding your development team towards creating a robust and user-friendly product.
Software quality metrics are essential quantitative indicators that evaluate the quality, performance, maintainability, and complexity of software products. These quantifiable measures enable teams to monitor progress, identify challenges, and adjust strategies in the software development process. Additionally, metrics in software engineering play a crucial role in enhancing overall software product’s quality.
By measuring various aspects such as functionality, reliability, and usability, quality metrics ensure that software systems meet user expectations and performance standards. The following subsections delve into specific key metrics that play a pivotal role in maintaining high code quality and software reliability.
Defect density is a crucial metric that helps identify problematic areas in the codebase by measuring the number of defects per a specified amount of code. Typically measured in terms of Lines of Code (LOC), a high defect density indicates potential maintenance challenges and higher defect risks. Pinpointing areas with high defect density allows development teams to focus on improving those sections, leading to a more stable and reliable software product and enhancing defect removal efficiency.
Understanding and reducing defect density is essential for maintaining high code quality. It provides a clear picture of the software’s health and helps teams prioritize bug fixes and software defects. Consistent monitoring allows teams to proactively address issues, enhancing the overall quality and user satisfaction of the software product.
Code coverage is a metric that assesses the percentage of code executed during testing, ensuring adequate test coverage and identifying untested parts. Static analysis tools like SonarQube, ESLint, and Checkstyle play a crucial role in maintaining high code quality by enforcing consistent coding practices and detecting potential vulnerabilities before runtime. These tools are integral to the software development process, helping teams adhere to code quality standards and reduce the likelihood of defects.
Maintaining high code quality through comprehensive code coverage leads to fewer defects and improved code maintainability. Software quality management platforms that facilitate code coverage analysis include:
The Maintainability Index is a metric that provides insights into the software’s complexity, readability, and documentation, all of which influence how easily a software system can be modified or updated. Metrics such as cyclomatic complexity, which measures the number of linearly independent paths in code, are crucial for understanding the complexity of the software. High complexity typically suggests there may be maintenance challenges ahead. It also indicates a greater risk of defects.
Other metrics like the Length of Identifiers, which measures the average length of distinct identifiers in a program, and the Depth of Conditional Nesting, which measures the depth of nesting of if statements, also contribute to the Maintainability Index. These metrics help identify areas that may require refactoring or documentation improvements, ultimately enhancing the maintainability and longevity of the software product.
Performance and reliability metrics are vital for understanding the software’s ability to perform under various conditions over time. These metrics provide insights into the software’s stability, helping teams gauge how well the software maintains its operational functions without interruption. By implementing rigorous software testing and code review practices, teams can proactively identify and fix defects, thereby improving the software’s performance and reliability.
The following subsections explore specific essential metrics that are critical for assessing performance and reliability, including key performance indicators and test metrics.
Mean Time Between Failures (MTBF) is a key metric used to assess the reliability and stability of a system. It calculates the average time between failures, providing a clear indication of how often the system can be expected to fail. A higher MTBF indicates a more reliable system, as it means that failures occur less frequently.
Tracking MTBF helps teams understand the robustness of their software and identify potential areas for improvement. Analyzing this metric helps development teams implement strategies to enhance system reliability, ensuring consistent performance and meeting user expectations.
Mean Time to Repair (MTTR) reflects the average duration needed to resolve issues after system failures occur. This metric encompasses the total duration from system failure to restoration, including repair and testing times. A lower MTTR indicates that the system can be restored quickly, minimizing downtime and its impact on users. Additionally, Mean Time to Recovery (MTTR) is a critical metric for understanding how efficiently services can be restored after a failure, ensuring minimal disruption to users.
Understanding MTTR is crucial for evaluating the effectiveness of maintenance processes. It provides insights into how efficiently a development team can address and resolve issues, ultimately contributing to the overall reliability and user satisfaction of the software product.
Response time measures the duration taken by a system to react to user commands, which is crucial for user experience. A shorter response time indicates a more responsive system, enhancing user satisfaction and engagement. Measuring response time helps teams identify performance bottlenecks that may negatively affect user experience.
Ensuring a quick response time is essential for maintaining high user satisfaction and retention rates. Performance monitoring tools can provide detailed insights into response times, helping teams optimize their software to deliver a seamless and efficient user experience.
User engagement and satisfaction metrics are vital for assessing how users interact with a product and can significantly influence its success. These metrics provide critical insights into user behavior, preferences, and satisfaction levels, helping teams refine product features to enhance user engagement.
Tracking these metrics helps development teams identify areas for improvement and ensures the software meets user expectations. The following subsections explore specific metrics that are crucial for understanding user engagement and satisfaction.
Net Promoter Score (NPS) is a widely used gauge of customer loyalty, reflecting how likely customers are to recommend a product to others. It is calculated by subtracting the percentage of detractors from the percentage of promoters, providing a clear metric for customer loyalty. A higher NPS indicates that customers are more satisfied and likely to promote the product.
Tracking NPS helps teams understand customer satisfaction levels and identify areas for improvement. Focusing on increasing NPS helps development teams enhance user satisfaction and retention, leading to a more successful product.
The number of active users reflects the software’s ability to retain user interest and engagement over time. Tracking daily, weekly, and monthly active users helps gauge the ongoing interest and engagement levels with the software. A higher number of active users indicates that the software is effectively meeting user needs and expectations.
Understanding and tracking active users is crucial for improving user retention strategies. Analyzing user engagement data helps teams enhance software features and ensure the product continues to deliver value.
Tracking how frequently specific features are utilized can inform development priorities based on user needs and feedback. Analyzing feature usage reveals which features are most valued and frequently utilized by users, guiding targeted enhancements and prioritization of development resources.
Monitoring specific feature usage helps development teams gain insights into user preferences and behavior. This information helps identify areas for improvement and ensures that the software evolves in line with user expectations and demands.
Financial metrics are essential for understanding the economic impact of software products and guiding business decisions effectively. These metrics help organizations evaluate the economic benefits and viability of their software products. Tracking financial metrics helps development teams make informed decisions that contribute to the financial health and sustainability of the software product. Tracking metrics such as MRR helps Agile teams understand their product's financial health and growth trajectory.
The following subsections explore specific financial metrics that are crucial for evaluating software development.
Customer Acquisition Cost (CAC) represents the total cost of acquiring a new customer, including marketing expenses and sales team salaries. It is calculated by dividing total sales and marketing costs by the number of new customers acquired. A high customer acquisition costs (CAC) shows that targeted marketing strategies are necessary. It also suggests that enhancements to the product’s value proposition may be needed.
Understanding CAC is crucial for optimizing marketing efforts and ensuring that the cost of acquiring new customers is sustainable. Reducing CAC helps organizations improve overall profitability and ensure the long-term success of their software products.
Customer lifetime value (CLV) quantifies the total revenue generated from a customer. This measurement accounts for the entire duration of their relationship with the product. It is calculated by multiplying the average purchase value by the purchase frequency and lifespan. A healthy ratio of CLV to CAC indicates long-term value and sustainable revenue.
Tracking CLV helps organizations assess the long-term value of customer relationships and make informed business decisions. Focusing on increasing CLV helps development teams enhance customer satisfaction and retention, contributing to the financial health of the software product.
Monthly recurring revenue (MRR) is predictable revenue from subscription services generated monthly. It is calculated by multiplying the total number of paying customers by the average revenue per customer. MRR serves as a key indicator of financial health, representing consistent monthly revenue from subscription-based services.
Tracking MRR allows businesses to forecast growth and make informed financial decisions. A steady or increasing MRR indicates a healthy subscription-based business, while fluctuations may signal the need for adjustments in pricing or service offerings.
Selecting the right metrics for your project is crucial for ensuring that you focus on the most relevant aspects of your software development process. A systematic approach helps identify the most appropriate product metrics that can guide your development strategies and improve the overall quality of your software. Activation rate tracks the percentage of users who complete a specific set of actions consistent with experiencing a product's core value, making it a valuable metric for understanding user engagement.
The following subsections provide insights into key considerations for choosing the right metrics.
Metrics selected should directly support the overarching goals of the business to ensure actionable insights. By aligning metrics with business objectives, teams can make informed decisions that drive business growth and improve customer satisfaction. For example, if your business aims to enhance user engagement, tracking metrics like active users and feature usage will provide valuable insights.
A data-driven approach ensures that the metrics you track provide objective data that can guide your marketing strategy, product development, and overall business operations. Product managers play a crucial role in selecting metrics that align with business goals, ensuring that the development team stays focused on delivering value to users and stakeholders.
Clear differentiation between vanity metrics and actionable metrics is essential for effective decision-making. Vanity metrics may look impressive but do not provide insights or drive improvements. In contrast, actionable metrics inform decisions and strategies to enhance software quality. Vanity Metrics should be avoided; instead, focus on actionable metrics tied to business outcomes to ensure meaningful progress and alignment with organizational goals.
Using the right metrics fosters a culture of accountability and continuous improvement within agile teams. By focusing on actionable metrics, development teams can track progress, identify areas for improvement, and implement changes that lead to better software products. This balance is crucial for maintaining a metrics focus that drives real value.
As a product develops, the focus should shift to metrics that reflect user engagement and retention in line with our development efforts. Early in the product lifecycle, metrics like user acquisition and activation rates are crucial for understanding initial user interest and onboarding success.
As the product matures, metrics related to user satisfaction, feature usage, and retention become more critical. Metrics should evolve to reflect the changing priorities and challenges at each stage of the product lifecycle.
Continuous tracking and adjustment of metrics ensure that development teams remain focused on the most relevant aspects of project management in the software, leading to sustained tracking product metrics success.
Having the right tools for tracking and visualizing metrics is essential for automatically collecting raw data and providing real-time insights. These tools act as diagnostics for maintaining system performance and making informed decisions.
The following subsections explore various tools that can help track software metrics and visualize process metrics and software metrics effectively.
Static analysis tools analyze code without executing it, allowing developers to identify potential bugs and vulnerabilities early in the development process. These tools help improve code quality and maintainability by providing insights into code structure, potential errors, and security vulnerabilities. Popular static analysis tools include Typo, SonarQube, which provides comprehensive code metrics, and ESLint, which detects problematic patterns in JavaScript code.
Using static analysis tools helps development teams enforce consistent coding practices and detect issues early, ensuring high code quality and reducing the likelihood of software failures.
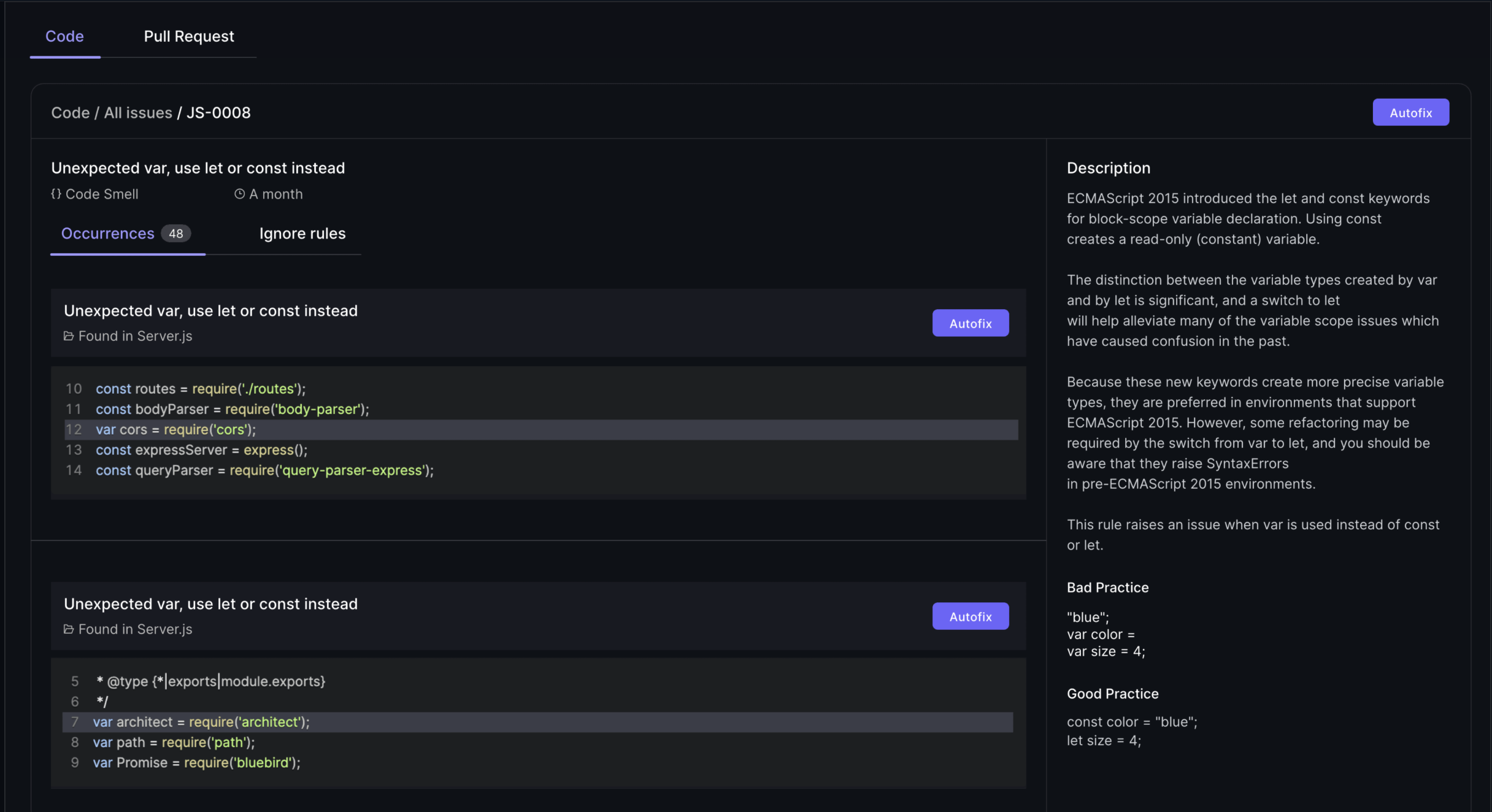
Dynamic analysis tools execute code to find runtime errors, significantly improving software quality. Examples of dynamic analysis tools include Valgrind and Google AddressSanitizer. These tools help identify issues that may not be apparent in static analysis, such as memory leaks, buffer overflows, and other runtime errors.
Incorporating dynamic analysis tools into the software engineering development process helps ensure reliable software performance in real-world conditions, enhancing user satisfaction and reducing the risk of defects.
Performance monitoring tools track performance, availability, and resource usage. Examples include:
Insights from performance monitoring tools help identify performance bottlenecks and ensure adherence to SLAs. By using these tools, development teams can optimize system performance, maintain high user engagement, and ensure the software meets user expectations, providing meaningful insights.
AI coding assistants do accelerate code creation, but they also introduce variability in style, complexity, and maintainability. The bottleneck has shifted from writing code to understanding, reviewing, and validating it.
Effective AI-era code reviews require three things:
AI coding reviews are not “faster reviews.” They are smarter, risk-aligned reviews that help teams maintain quality without slowing down the flow of work.
Understanding and utilizing software product metrics is crucial for the success of any software development project. These metrics provide valuable insights into various aspects of the software, from code quality to user satisfaction. By tracking and analyzing these metrics, development teams can make informed decisions, enhance product quality, and ensure alignment with business objectives.
Incorporating the right metrics and using appropriate tools for tracking and visualization can significantly improve the software development process. By focusing on actionable metrics, aligning them with business goals, and evolving them throughout the product lifecycle, teams can create robust, user-friendly, and financially successful software products. Using tools to automatically collect data and create dashboards is essential for tracking and visualizing product metrics effectively, enabling real-time insights and informed decision-making. Embrace the power of software product metrics to drive continuous improvement and achieve long-term success.
Software product metrics are quantifiable measurements that evaluate the performance and characteristics of software products, aligning with business goals while adding value for users. They play a crucial role in ensuring the software functions effectively.
Defect density is crucial in software development as it highlights problematic areas within the code by quantifying defects per unit of code. This measurement enables teams to prioritize improvements, ultimately reducing maintenance challenges and mitigating defect risks.
Code coverage significantly enhances software quality by ensuring that a high percentage of the code is tested, which helps identify untested areas and reduces defects. This thorough testing ultimately leads to improved code maintainability and reliability.
Tracking active users is crucial as it measures ongoing interest and engagement, allowing you to refine user retention strategies effectively. This insight helps ensure the software remains relevant and valuable to its users. A low user retention rate might suggest a need to improve the onboarding experience or add new features.
AI coding reviews enhance the software development process by optimizing coding speed and maintaining high code quality, which reduces human error and streamlines workflows. This leads to improved efficiency and the ability to quickly identify and address bottlenecks.

Miscommunication and unclear responsibilities are some of the biggest reasons projects stall, especially for engineering, product, and cross-functional teams.
A survey by PMI found that 37% of project failures are caused by a lack of clearly defined roles and responsibilities. When no one knows who owns what, deadlines slip, there’s no accountability, and team trust takes a hit.
A RACI chart can change that. By clearly mapping out who is Responsible, Accountable, Consulted, and Informed, RACI charts bring structure, clarity, and speed to team workflows.
But beyond the basics, we can use automation, graph models, and analytics to build smarter RACI systems that scale. Let’s dive into how.
A RACI chart is a project management tool that clearly outlines roles and responsibilities across a team. It defines four key roles:
RACI charts can be used in many scenarios from coordinating a product launch to handling a critical incident to organizing sprint planning meetings.
While traditional relational databases can model RACI charts, graph databases are a much better fit. Graphs naturally represent complex relationships without rigid table structures, making them ideal for dynamic team environments. In a graph model:

Using a graph database like Neo4j or Amazon Neptune, teams can quickly spot patterns. For example, you can easily find individuals who are assigned too many "Responsible" tasks, indicating a risk of overload.

You can also detect tasks that are missing an "Accountable" person, helping you catch potential gaps in ownership before they cause delays.

Graphs make it far easier to deal with complex team structures and keep projects running smoothly. And as organizations and projects grow, so does the need for it.
Once you model RACI relationships, you can apply simple algorithms to detect imbalances in how work is distributed. For example, you can spot tasks missing "Consulted" or "Informed" connections, which can cause blind spots or miscommunication.
By building scoring models, you can measure responsibility density, i.e., how many tasks each person is involved in, and then flag potential issues like redundancy. If two people are marked as "Accountable" for the same task, it could cause confusion over ownership.
Using tools like Python with libraries such as Pandas and NetworkX, teams can create matrix-style breakdowns of roles versus tasks. This makes it easy to visualize overlaps, gaps, and overloaded roles, helping managers balance team workloads more effectively and ensure smoother project execution.
After clearly mapping the RACI roles, teams can automate workflows to move even faster. Assignments can be auto-filled based on project type or templates, reducing manual setup.
You can also trigger smart notifications, like sending a Slack or email alert, when a "Responsible" task has no "Consulted" input, or when a task is completed without informing stakeholders.
Tools like Zapier or Make help you automate workflows. And one of the most common use cases for this is automatically assigning a QA lead when a bug is filed or pinging a Product Manager when a feature pull request (PR) is merged.
To make full use of RACI models, you can integrate directly with popular project management tools via their APIs. Platforms like Jira, Asana, Trello, etc., allow you to extract task and assignee data in real time.
For example, a Jira API call can pull a list of stories missing an "Accountable" owner, helping project managers address gaps quickly. In Asana, webhooks can automatically trigger role reassignment if a project’s scope or timeline changes.
These integrations make it easier to keep RACI charts accurate and up to date, allowing teams to respond dynamically as projects evolve, without the need for constant manual checks or updates.
Visualizing RACI data makes it easier to spot patterns and drive better decisions. Clear visual maps surface bottlenecks like overloaded team members and make onboarding faster by showing new hires exactly where they fit. Visualization also enables smoother cross-functional reviews, helping teams quickly understand who is responsible for what across departments.
Popular libraries like D3.js, Mermaid.js, Graphviz, and Plotly can bring RACI relationships to life. Force-directed graphs are especially useful, as they visually highlight overloaded individuals or missing roles at a glance.
There could be a dashboard that dynamically pulls data from project management tools via API, updating an interactive org-task-role graph in real time. Teams could immediately see when responsibilities are unbalanced or when critical gaps emerge, making RACI a living system that actively guides better collaboration.
Collecting RACI data over time gives teams a much clearer picture of how work is actually distributed. Because at the start it might be one things and as the project evolves it becomes entirely different.
Regularly analyzing RACI data helps spot patterns early, make better staffing decisions, and ensure responsibilities stay fair and clear.
Several simple metrics can give you powerful insights. Track the average number of tasks assigned as "Responsible" or "Accountable" per person. Measure how often different teams are being consulted on projects; too little or too much could signal issues. Also, monitor the percentage of tasks that are missing a complete RACI setup, which could expose gaps in planning.
You don’t need a big budget to start. Using Python with Dash or Streamlit, you can quickly create a basic internal dashboard to track these metrics. If your company already uses Looker or Tableau, you can integrate RACI data using simple SQL queries. A clear dashboard makes it easy for managers to keep workloads balanced and projects on track.
Keeping RACI charts consistent across teams requires a mix of planning, automation, and gradual culture change. Here are some simple ways to enforce it:
RACI charts are one of those parts of management theory that actually drive results when combined with data, automation, and visualization. By clearly defining who is Responsible, Accountable, Consulted, and Informed, teams avoid confusion, reduce delays, and improve collaboration.
Integrating RACI into workflows, dashboards, and project tools makes it easier to spot gaps, balance workloads, and keep projects moving smoothly. With the right systems in place, organizations can work faster, smarter, and with far less friction across every team.

Developers want to write code, not spend time managing infrastructure. But modern software development requires agility.
Frequent releases, faster deployments, and scaling challenges are the norm. If you get stuck in maintaining servers and managing complex deployments, you’ll be slow.
This is where Platform-as-a-Service (PaaS) comes in. It provides a ready-made environment for building, deploying, and scaling applications.
In this post, we’ll explore how PaaS streamlines processes with containerization, orchestration, API gateways, and much more.
Platform-as-a-Service (PaaS) is a cloud computing model that abstracts infrastructure management. It provides a complete environment for developers to build, deploy, and manage applications without worrying about servers, storage, or networking.
For example, instead of configuring databases or managing Kubernetes clusters, developers can focus on coding. Popular PaaS options like AWS Elastic Beanstalk, Google App Engine, and Heroku handle the heavy lifting.
These solutions offer built-in tools for scaling, monitoring, and deployment - making development faster and more efficient.
PaaS simplifies software development by removing infrastructure complexities. It accelerates the application lifecycle, from coding to deployment.
Businesses can focus on innovation without worrying about server management or system maintenance.
Whether you’re a startup with a goal to launch quickly or an enterprise managing large-scale applications, PaaS offers all the flexibility and scalability you need.
Here’s why your business can benefit from PaaS:
Irrespective of the size of the business, these are the benefits that no one wants to leave on the table. This makes PaaS an easy choice for most businesses.
PaaS platforms offer a suite of components that helps teams achieve effective software delivery. From application management to scaling, these tools simplify complex tasks.
Understanding these components helps businesses build reliable, high-performance applications.
Let’s explore the key components that power PaaS environments:
Containerization tools like Docker and orchestration platforms like Kubernetes enable developers to build modular, scalable applications using microservices.
Containers package applications with their dependencies, ensuring consistent behavior across development, testing, and production.
In a PaaS setup, containerized workloads are deployed seamlessly.
For example, a video streaming service could run separate containers for user authentication, content management, and recommendations, making updates and scaling easier.
PaaS platforms often include robust orchestration tools such as Kubernetes, OpenShift, and Cloud Foundry.
These manage multi-container applications by automating deployment, scaling, and maintenance.
Features like auto-scaling, self-healing, and service discovery ensure resilience and high availability.
For the same video streaming service that we discussed above, Kubernetes can automatically scale viewer-facing services during peak hours while maintaining stable performance.
API gateways like Kong, Apigee, and AWS API Gateway act as entry points for managing external requests. They provide essential services like rate limiting, authentication, and request routing.
In a microservices-based PaaS environment, the API gateway ensures secure, reliable communication between services.
It can help manage traffic to ensure premium users receive prioritized access during high-demand events.
Deployment pipelines are the backbone of modern software development. In a PaaS environment, they automate the process of building, testing, and deploying applications.
This helps reduce manual work and accelerates time-to-market. With efficient pipelines, developers can release new features quickly and maintain application stability.
PaaS platforms integrate seamlessly with tools for Continuous Integration/Continuous Deployment (CI/CD) and Infrastructure-as-Code (IaC), streamlining the entire software lifecycle.
CI/CD automates the movement of code from development to production. Platforms like Typo, GitHub Actions, Jenkins, and GitLab CI ensure every code change is tested and deployed efficiently.
Benefits of CI/CD in PaaS:
IaC tools like Terraform, AWS CloudFormation, and Pulumi allow developers to define infrastructure using code. Instead of manual provisioning, infrastructure resources are declared, versioned, and deployed consistently.
Advantages of IaC in PaaS:
Together, CI/CD and IaC ensure smoother deployments, greater agility, and operational efficiency.
PaaS offers flexible scaling to manage application demand.
Tools like Kubernetes, AWS Elastic Beanstalk, and Azure App Services provide auto-scaling, automatically adjusting resources based on traffic.
Additionally, load balancers distribute incoming requests across instances, preventing overload and ensuring consistent performance.
For example, during a flash sale, PaaS can scale horizontally and balance traffic, maintaining a seamless user experience.
Performance benchmarking is essential to ensure your PaaS workloads run efficiently. It involves measuring how well applications respond under different conditions.
By tracking key performance indicators (KPIs), businesses can optimize applications for speed, reliability, and scalability.
Key Performance Indicators (KPIs) to Monitor:
To benchmark and monitor performance, tools like JMeter and k6 simulate real-world traffic. For continuous monitoring, Prometheus gathers metrics from PaaS environments, while Grafana provides real-time visualizations for analysis.
For deeper insights into engineering performance, platforms like Typo can analyze application behavior and identify inefficiencies.
By combining infrastructure monitoring with detailed engineering analytics, teams can optimize resource utilization and resolve performance bottlenecks faster.
PaaS simplifies software development by handling infrastructure management, automating deployments, and optimizing scalability.
It allows developers to focus on building innovative applications without the burden of server management.
With features like CI/CD pipelines, container orchestration, and API gateways, PaaS ensures faster releases and seamless scaling.
To maintain peak performance, continuous benchmarking and monitoring are essential. Platforms like Typo provide in-depth engineering analytics, helping teams identify and resolve issues quickly.
Start leveraging PaaS and tools like Typoapp.io to accelerate development, enhance performance, and scale with confidence.

The software engineering industry is diverse and spans a variety of job titles that can vary from company to company. Moreover, this industry is continuously evolving, which makes it difficult to clearly understand what each title actually means and how to advance in these positions.
Given below is the breakdown of common engineering job titles, their responsibilities, and ways to climb the career ladder.
Software engineering represents a comprehensive and dynamic discipline that leverages engineering methodologies to architect, develop, and maintain sophisticated software systems. At its foundation, software engineering encompasses far more than code generation—it integrates the complete software development lifecycle, spanning initial system architecture and design through rigorous testing protocols, strategic deployment, and continuous maintenance optimization. Software engineers serve as the cornerstone of this ecosystem, utilizing their technical expertise to analyze complex challenges and deliver scalable, high-performance solutions that drive technological advancement.
Within this evolving landscape, diverse software engineer classifications emerge, each reflecting distinct experience trajectories and operational responsibilities. Junior software engineers typically focus on mastering foundational competencies while supporting cross-functional development teams, whereas senior software engineers and principal engineers tackle sophisticated architectural challenges and mentor emerging talent. Positions such as software engineer II represent intermediate-level roles where professionals are expected to contribute autonomously and resolve increasingly complex technical problems. As market demand for skilled software engineers continues to accelerate, understanding these software engineering classifications and their strategic contributions proves essential for professionals seeking to optimize their career trajectory or organizations aiming to build robust engineering teams.
Chief Technology Officer (CTO) is the highest attainable post in software engineering. The Chief Technology Officer is a key member of the executive team, responsible for shaping the company's technology strategy and working closely with other executives to ensure alignment with business goals. They are multi-faceted and require a diverse skill set. Any decision of theirs can either make or break the company. While their specific responsibilities depend on the company’s size and makeup, a few common ones are listed below:
In startups or early-stage companies, the Chief Technology Officer may also serve as a technical co-founder or technical co, deeply involved in selecting technology stacks, designing system integrations, and collaborating with other executive leaders to set the company’s technical direction.
In facing challenges, the CTO must work closely with stakeholders, board members, and the executive team to align technology initiatives with overall business goals.
Vice President of Engineering (VP of Engineering) is one of the high-level executives who reports directly to the CTO. As a vice president, this senior executive is responsible for overseeing the entire engineering department, shaping technical strategy, and managing large, cross-functional teams within the organizational hierarchy. The Vice President of Engineering also actively monitors the team's progress to ensure continuous improvement in performance, workflow, and collaboration. They have at least 10 years of experience in leadership. They bridge the gap between technical execution and strategic leadership and ensure product development aligns with the business goals.
Not every company includes a Director of Engineering. Usually, the VP or CTO takes their place and handles both responsibilities. This role requires a combination of technical depth, leadership, communication, and operational excellence. They translate strategic goals into day-to-day operations and delivery.
Software Engineering Managers are mid-level leaders who manage both people and technical know-how. As software engineering managers, they are responsible for leading teams, making key decisions, and overseeing software development projects. They have a broad understanding of all aspects of designing, innovation, and development of software products and solutions.
Principal Software Engineers are responsible for strategic technical decisions at a company’s level. They may not always manage people directly, but lead by influence. Principal software engineers may also serve as chief architects, responsible for designing large-scale computing systems and selecting technology stacks to ensure the technology infrastructure aligns with organizational strategy. They drive tech vision, strategy, and execution of complex engineering projects within an organization.
Staff Software Engineers, often referred to more generally as staff engineers, tackle open-ended problems, find solutions, and support team and organizational goals. They are recognized for their extensive, advanced technical skills and ability to solve complex problems.
Staff engineers may progress to senior staff engineer roles, taking on even greater leadership and strategic responsibilities within the organization. Both staff engineers and senior staff engineers are often responsible for leading large projects, mentoring engineering teams, and contributing to long-term technology strategy. These roles play a key part in risk assessment and cross-functional communication, ensuring that critical projects are delivered successfully and align with organizational objectives.
A Senior Software Engineer, often referred to as a senior engineer, assists software engineers with daily tasks and troubleshooting problems. Senior engineers typically progress from a mid level engineer role and may take on leadership positions such as team lead or tech lead as part of their career path. They have a strong grasp of both foundation concepts and practical implementation.
Leadership skills are essential for senior engineers, especially when mentoring junior team members or managing projects. Senior engineers, team leads, and tech leads are also responsible for debugging code and ensuring technical standards are maintained within the team. The career path for engineers often includes progression from mid level engineer to senior engineer, then to leadership positions such as team lead, tech lead, or engineering manager. In project management, team leads and tech leads play a key role in guiding teams and implementing new technologies.
A Software Engineer, also known as a software development engineer, writes and tests code. Entry-level roles such as junior software engineer and junior engineer focus on foundational skills, including testing code and writing test code to ensure software quality. They are early in their careers and focus mainly on learning, supporting, and contributing to the software development process under the guidance of senior engineers. Software Engineer III is a more advanced title, representing a higher level of responsibility and expertise within the software engineering career path.
Beyond the fundamental development positions, software engineering comprises an extensive spectrum of specialized roles that address distinct technical requirements and operational challenges within modern organizations. Software architects, for instance, are tasked with designing comprehensive structural frameworks and system blueprints for complex software ecosystems, ensuring optimal scalability, maintainability, and strategic alignment with overarching business objectives. Their deep expertise in architectural patterns and system design principles proves instrumental in facilitating technical guidance across development teams while establishing robust coding standards and best practices.
As technological advancements continue to reshape the industry landscape, unprecedented specialized roles have emerged to address evolving market demands. Machine learning engineers concentrate on architecting intelligent systems capable of autonomous learning from vast datasets, playing a pivotal role in developing sophisticated AI-driven applications and predictive analytics platforms. Site reliability engineers (SREs) ensure that software ecosystems remain robust, scalable, and maintain high availability metrics, effectively bridging software engineering methodologies with comprehensive IT operations management. DevOps engineers streamline and optimize the entire development lifecycle and deployment pipeline, fostering enhanced collaboration between development and operations teams to accelerate delivery timelines while improving overall system reliability and performance metrics.
These specialized roles comprise essential components for organizations aiming to maintain competitive advantages and drive technological innovation within their respective markets. By thoroughly understanding the unique operational responsibilities and technical skill sets required for each specialized position, companies can strategically assemble well-rounded software engineering teams capable of addressing diverse technical challenges and facilitating scalable solutions across complex development environments.
The comprehensive landscape of software engineering undergoes continuous transformation driven by AI-driven technological paradigms and dynamic industry requirements analysis. In recent operational cycles, transformative methodologies such as cloud-native architectures, artificial intelligence frameworks, and machine learning algorithms have fundamentally reshaped how software engineers approach complex problem-solving scenarios and streamline development workflows. The accelerating emphasis on cybersecurity protocols and data privacy compliance has simultaneously introduced sophisticated challenges and strategic opportunities for software engineering professionals seeking to optimize their technical capabilities.
Industry-specific variations demonstrate significant impact on defining operational responsibilities and performance expectations for software engineers across diverse sectors. For instance, technology-focused organizations typically prioritize rapid innovation cycles, deployment velocity, and adoption of cutting-edge technological stacks, while traditional enterprise environments often emphasize seamless integration of software solutions into established business process workflows. These fundamental differences influence comprehensive project scopes, from the types of development initiatives engineers execute to the specific technology architectures and deployment methodologies they implement for optimal performance.
Maintaining comprehensive awareness of industry trend patterns and understanding how various sectors approach software engineering optimization proves crucial for professionals seeking to advance their technical career trajectories. This strategic knowledge also enables organizations to adapt their development methodologies, attract top-tier technical talent, and construct resilient, future-ready engineering teams capable of delivering scalable, high-performance solutions that align with evolving market demands and technological advancement cycles.
Software engineers leverage some of the most optimized compensation architectures in the contemporary job market ecosystem, reflecting the exponential demand trajectory for their specialized technical competencies and domain expertise. Compensation algorithms vary based on multifaceted parameters including geographical data points, industry verticals, experience matrices, and specific role taxonomies. For instance, entry-level software engineers typically initialize with robust baseline compensation packages, while senior software engineers, principal architects, and those occupying specialized technical niches can command substantially enhanced remuneration structures, frequently surpassing $200,000 annually within leading technological innovation hubs and high-performance computing environments.
Beyond foundational salary frameworks, numerous organizations deploy comprehensive benefit optimization strategies to attract and retain top-tier software engineering talent pools. These sophisticated packages may encompass equity participation mechanisms, performance-driven bonus algorithms, flexible work arrangement protocols, and enterprise-grade health insurance infrastructures. Select companies additionally provision professional development acceleration programs, wellness optimization initiatives, and generous paid time-off allocation systems that enhance overall talent retention metrics and employee satisfaction indices.
Understanding the compensation optimization potential and benefit architecture frameworks associated with diverse software engineering role classifications empowers technical professionals to execute data-driven career trajectory decisions and enables organizations to maintain competitive positioning in attracting skilled engineering resources. This strategic comprehension facilitates optimal resource allocation and ensures sustainable talent acquisition pipelines within the rapidly evolving technological landscape.
How do organizational frameworks and cultural architectures impact software engineering talent acquisition and retention strategies? Establishing robust company culture and clearly defined organizational values represents critical infrastructure components in attracting and retaining high-caliber software engineering professionals. Organizations that architect environments fostering innovation ecosystems, collaborative workflows, and continuous learning frameworks demonstrate significantly higher success rates in building high-performing software engineering teams. When software engineers experience comprehensive support systems, value recognition protocols, and empowerment mechanisms to contribute strategic ideas, they exhibit enhanced engagement metrics and demonstrate elevated motivation levels to drive measurable results across development lifecycles.
What role do diversity, equity, and inclusion frameworks play in modern software engineering organizations? Diversity, equity, and inclusion (DEI) initiatives have evolved into fundamental pillars within the software engineering landscape, representing not merely compliance requirements but strategic advantages for organizational excellence. Companies that prioritize and systematically implement these values through structured methodologies attract broader candidate pools while simultaneously leveraging diverse perspectives that fuel enhanced creativity algorithms and sophisticated problem-solving capabilities. Transparent communication protocols, achievement recognition systems, and structured professional growth pathways further optimize employee satisfaction metrics and retention analytics, creating sustainable talent management ecosystems.
How can organizations leverage cultural intelligence to create optimal software engineering environments? By comprehensively understanding and strategically implementing company culture frameworks and organizational value systems, enterprises can architect environments where software engineers demonstrate peak performance capabilities, resulting in accelerated innovation cycles, enhanced productivity metrics, and sustainable long-term organizational success. These cultural optimization strategies create symbiotic relationships between individual professional development and organizational objectives, establishing foundations for continuous improvement and scalable growth patterns across software engineering operations.
Constant learning is the key. In the AI era, one needs to upskill continuously. Prioritize both technical aspects and AI-driven areas, including machine learning, natural language processing, and AI tools like GitHub Copilot. You can also pursue certification, attend a workshop, or enroll in an online course. This will enhance your development process and broaden your expertise.
Constructive feedback is the most powerful tool in software engineering. Receiving feedback from peers and managers helps to identify strengths and areas for growth. You can also leverage AI-powered tools to analyze coding habits and performance objectively. This provides a clear path for continuous improvement and development.
Technology evolves quickly, especially with the rise of Generative AI. Read industry blogs, participate in webinars, and attend conferences to stay up to date with established practices and latest trends in AI and ML. This helps to make informed decisions about which skills to prioritize and which tools to adopt.
Leadership isn't only about managing people. It is also about understanding new methods and tools to enhance productivity. Collaborate with cross-functional teams, leverage AI tools for better communication and workflow management. Take initiative in projects, mentor and guide others towards innovative solutions.
Understanding the career ladder involves mastering different layers and taking on more responsibilities. You should be aware of both traditional roles and emerging opportunities in AI and ML. Moreover, soft skills, including communication, mentorship, and decision making, are as critical as the above-mentioned skills. This will help to prepare you to climb the ladder with purpose and clarity.
With the constantly evolving software engineering landscape, it is crucial to understand the responsibilities of each role clearly. By upskilling continuously and staying updated with the current trends, you can advance confidently in your career. The journey might be challenging, but with the right strategy and mindset, you can do it. All the best!

Starting a startup is like setting off on an adventure without a full map. You can’t plan every detail, instead you need to move fast, learn quickly, and adapt on the go. Traditional Software Development Life Cycle (SDLC) methods, like Waterfall, are too rigid for this kind of journey.
That’s why many startups turn to Lean Development: a faster, more flexible approach grounded in lean philosophy, which emphasizes waste reduction and continuous improvement. Lean Software Development is a translation of lean manufacturing principles and practices to the software development domain, drawing its philosophy from the manufacturing industry where lean principles were pioneered to optimize production and assembly lines.
Key benefits of Lean Development for startups include:
Lean Software Development is considered an integral part of the Agile software development methodology, and the lean agile approach combines principles from both Lean and Agile to optimize workflows and foster team responsibility.
Lean and Agile share roots in the agile manifesto and agile methodology, which emphasize iterative progress, collaboration, and responsiveness to change. Lean Software Development was popularized by Mary and Tom Poppendieck in their 2003 book, "Lean Software Development: An Agile Toolkit."
The Lean approach is often associated with the Minimum Viable Product (MVP) strategy, enabling rapid deployment and iterative feedback to refine products efficiently.
In this blog, we’ll explore what Lean Development is, how it compares to other methods, and the key practices startups use to build smarter and grow faster.
The lean SDLC model focuses on reducing waste and maximizing value to create high-quality software. Lean focuses on improving processes and efficiency, while Agile focuses on enhancing products. Adopting lean development practices within the SDLC helps minimize risks, reduce costs, and accelerate time to market. Lean Software Development encourages a culture of continuous improvement and learning within teams, emphasizing the learning process through short iteration cycles, feedback sessions, and ongoing communication. Implementing lean concepts involves assessing current processes, training teams in lean principles, and piloting projects to test and scale successful strategies. Lean Software Development promotes team empowerment and collaboration among team members, encouraging teams to break down problems into constituent elements to optimize workflow and foster team unity. Lean software development promotes a collaborative environment and empowers team members. The agile community acts as a supportive network that promotes the adoption and adaptation of Lean and Agile practices. Both Lean and Agile emphasize continuous improvement and accountability within product development teams, with Lean guided by the principles of lean software. Lean Software Development is implemented through specific agile practices and agile frameworks such as Scrum and Kanban, which are based on agile principles.
Lean development is especially effective for startups because it enables them to bring their product to market quickly, even with limited resources. This model emphasizes adaptability, customer feedback, and iterative processes.
Benefits of Lean Development:
The foundational principles of lean software development methodologies trace their origins to advanced manufacturing optimization systems, specifically the revolutionary Toyota Production System (TPS) implemented during the 1980s. This groundbreaking production framework fundamentally transformed manufacturing workflows by implementing systematic waste elimination protocols and value stream optimization techniques designed to maximize customer-centric deliverables. The TPS methodology gained widespread industry recognition for its capability to streamline production pipelines, optimize resource allocation algorithms, and deliver superior quality outputs through minimal resource consumption patterns while maintaining operational efficiency benchmarks.
The 1990s witnessed a paradigm shift when "The Machine That Changed The World" publication catalyzed global awareness of lean manufacturing principles, demonstrating how these optimization methodologies could be systematically adapted across diverse industry verticals beyond traditional automotive production systems. As software development landscapes evolved through technological advancement cycles, industry thought leaders and methodology architects began recognizing the transformative potential of applying lean optimization principles to software development lifecycle (SDLC) processes. The early 2000s marked a critical inflection point with the publication of "Lean Software Development: An Agile Toolkit" by Mary and Tom Poppendieck, which served as a comprehensive methodology framework that systematically adapted core lean manufacturing principles to software engineering practices. This influential methodology guide introduced the seven fundamental lean principles that now serve as operational guidelines for modern lean software development implementations. Today, lean development approaches function as essential architectural frameworks for both emerging startups and enterprise-level organizations, enabling development teams to eliminate process inefficiencies, optimize customer value delivery mechanisms, and implement continuous improvement protocols throughout their development workflows.
In Traditional models like Waterfall, the requirements are locked in at the beginning. The agile methodology is guided by the agile manifesto, which outlines core agile principles such as customer collaboration, iterative progress, and responsiveness to change. Agile uses specific agile frameworks like Scrum and Kanban to implement these principles, emphasizing iterative development through sprints and regular feedback. Lean software development is considered an integral part of the Agile software development methodology, and the lean agile approach combines principles from both to optimize workflow and foster team responsibility. While Agile development shares some similarities with Lean, Lean places an even greater emphasis on minimizing waste and improving processes, whereas Agile focuses on enhancing products. Both Lean and Agile emphasize continuous improvement, accountability within product development teams, and utilize iterative development to enable rapid updates and responsiveness to feedback.
The first principle of Lean methodology is waste elimination, which involves identifying and eliminating non-value-adding activities such as inefficient processes, excessive documentation, or redundant meetings. The Lean software development process includes the identification and elimination of waste to optimize efficiency. Regular meetings are held by project managers to identify and eliminate waste such as unnecessary code and process delays. Instead, the methodology prioritizes tasks that directly add value to products or the customer experience. This allows the development team to optimize their efforts, deliver value to customers effectively, and avoid multitasking, which can dilute focus.
Lean development focuses on creating value, reducing waste, and prioritizing build quality throughout the software development process. Build quality is a key focus of Lean Development, emphasizing the importance of build integrity to ensure software is reliable, adaptable, and maintainable. Building quality involves preventing waste while maintaining high standards, often through test-driven development and regular feedback. Software that has bugs and errors reduces the customer base, which can further impact quality. The second principle states that software issues must be solved immediately, not after the product is launched in the market. Methodologies such as pair programming and test-driven development help increase product quality and maintain a continuous feedback loop.
The market environment is constantly changing, and customers' expectations are growing. This principle prioritizes learning as much as possible before committing to serious, irreversible decisions. It helps avoid teams getting trapped by decisions made early in the development process, encouraging them to commit only at the last responsible moment. Prepare a decision-making model that outlines the necessary steps and gather relevant data to enable fast product delivery and continuous learning.
One of the key principles of the lean SDLC model is to deliver fast. This means building a simple solution, bringing it to market quickly, and enhancing it incrementally based on customer feedback. In Lean Software Development, team releases often involve launching a minimum viable product (MVP) to gather user feedback and guide future improvements. The MVP strategy focuses on rapid development of products with limited functionality and launching them to the market to gauge user reaction. Speed to market is a competitive advantage in the software industry, allowing teams to test assumptions early. It also enables better adjustment of the product to current customer needs in subsequent iterations, saving money and making the development process more result-oriented.
This principle states that people are the most valuable asset in an organization. The product development team is responsible for delivery and continuous improvement, making their empowerment crucial to project success. Agile teams, which operate within Lean and Agile frameworks, play a key role in continuous improvement and accountability through practices like sprints and retrospectives. Empowered teams with high autonomy report better engagement, job satisfaction, and ownership over outcomes. Lean Software Development promotes team empowerment and collaboration among team members. Respecting teamwork focuses on empowering team members and fostering a collaborative environment, especially under tight deadlines. When working together, it is important to respect each other despite differences. Lean development focuses on identifying gaps in the work process that might lead to challenges and conflicts. A few ways to minimize these gaps include encouraging open communication, valuing diverse perspectives, and creating a productive, innovative environment by respecting and nurturing talent.
The learning process in Lean SDLC model is continuous, enabling teams to improve through short iteration cycles, feedback sessions, and ongoing communication with customers. Learning usually takes place in one of three areas: new technologies, new skills, or a better understanding of users’ wants and needs. This lean principle focuses on amplifying learning by creating and retaining knowledge. Amplifying learning is achieved through practices like code reviews and paired programming to ensure knowledge is shared among team members. Learning is further enhanced through extensive code reviews and cross-team meetings in Lean Software Development. This is achieved by providing the necessary infrastructure to properly document and preserve valuable insights. Various methods for creating and retaining knowledge include user story development, pair programming, knowledge-sharing sessions, and thoroughly commented code.
This principle emphasizes optimizing the entire process and value stream rather than focusing on individual processes. It highlights the importance of viewing software delivery as an interconnected system, where improving one part in isolation can create bottlenecks elsewhere. Optimize the Whole encourages focusing on the entire value stream instead of isolated parts, ensuring that improvements benefit the overall flow and efficiency. Techniques to optimize the whole include value stream mapping, enhancing cross-functional collaboration, reducing handoff delays, and ensuring smooth integration between teams.
Within the framework of lean software development methodologies, customer feedback transcends traditional quality assurance checkpoints to function as the primary algorithmic driver influencing architectural decisions, feature prioritization matrices, and development velocity optimization. The lean development paradigm necessitates comprehensive stakeholder requirement analysis and seamless integration of user input streams throughout the entire Software Development Life Cycle (SDLC), establishing robust feedback loop mechanisms that enable rapid hypothesis validation, dynamic feature adjustment protocols, and real-time market demand calibration through continuous integration and deployment pipelines.
This systematic focus on customer feedback integration facilitates the delivery of enterprise-grade software solutions that consistently exceed user experience benchmarks while maintaining adaptive responsiveness to volatile market conditions and emerging technological requirements. Through the implementation of early-stage customer engagement protocols and iterative feedback collection systems, startup organizations can effectively eliminate unnecessary feature development overhead, substantially reduce resource allocation inefficiencies, and architect fundamentally transformative business solutions that demonstrate measurable market penetration success. Ultimately, customer satisfaction metrics become the primary Key Performance Indicator (KPI) governing development team objectives, orchestrating value delivery optimization strategies that ensure maximum return on investment with each production release cycle.
Continuous Integration (CI) comprises a foundational methodology within lean software development paradigms, strategically designed to optimize rapid delivery mechanisms and ensure high-caliber software solutions. This approach involves developers systematically creating and merging code modifications into centralized repositories through multiple daily iterations, automatically triggering sophisticated testing frameworks and comprehensive integration validation processes. CI methodologies ensure that software development workflows maintain seamless operational continuity, enabling early detection of potential issues while significantly mitigating risks associated with costly integration complications during subsequent development phases.
By transforming integration and testing protocols into systematic, routine components of the development lifecycle, development teams can effectively eliminate operational inefficiencies and resource waste typically associated with last-minute remediation efforts and extensive rework processes. CI frameworks empower development organizations to accelerate customer value delivery, maintain robust and stable codebase architectures, and implement responsive feedback mechanisms for continuous improvement. Consequently, continuous integration serves as an essential cornerstone for any lean software development process architected to deliver reliable, customer-centric solutions while maintaining startup-level operational velocity and market responsiveness.
Implementing lean software development methodologies represents a paradigm shift requiring comprehensive organizational transformation, particularly for development teams entrenched in traditional waterfall project management frameworks. The primary impediments encompass resistance to cultural metamorphosis—encompassing both cognitive restructuring and operational workflow modifications. Development teams frequently encounter significant challenges when abandoning established Gantt chart-driven processes, sprint planning methodologies, and legacy requirement documentation practices. Additionally, identifying and quantifying muda (waste) within intricate software engineering lifecycles demands sophisticated analysis of value stream mapping, cycle time metrics, and throughput optimization. These teams must navigate the complexity of distinguishing between value-added activities and non-value-added processes while simultaneously addressing technical debt accumulation and feature delivery bottlenecks.
Achieving successful lean software development implementation necessitates leadership commitment to cultivating a kaizen-driven culture emphasizing continuous improvement methodologies and empowering cross-functional team members to engage in controlled experimentation and iterative learning cycles. Strategic implementation requires establishing transparent communication channels, implementing comprehensive training programs focused on lean principles such as pull-based development, just-in-time delivery, and defect prevention strategies, while ensuring visible executive sponsorship from project managers and product owners throughout the transformation journey. Through systematic focus on incremental process improvements, celebrating measurable velocity increases and lead time reductions, development organizations can progressively establish confidence in lean engineering practices including Test-Driven Development (TDD), Continuous Integration/Continuous Deployment (CI/CD) pipelines, and automated quality assurance frameworks. Ultimately, embracing lean principles across the entire Software Development Life Cycle (SDLC) cultivates highly adaptive, innovation-focused, and performance-optimized engineering teams capable of delivering superior customer value while maintaining sustainable development practices.
To maximize lean software development efficacy, startups must systematically implement lean methodologies across comprehensive software development lifecycle phases. This approach involves implementing relentless focus on customer value optimization, waste elimination protocols, and establishing robust quality assurance frameworks from foundational development stages. Empowering development team members becomes a critical success factor—leveraging their technical expertise and enabling autonomous decision-making capabilities that optimize production workflows and streamline value delivery mechanisms.
Adopting advanced lean practices including test-driven development frameworks, continuous integration pipelines, and value stream mapping methodologies enables development teams to identify performance bottlenecks, eliminate redundant process steps, and accelerate customer value delivery cycles. Implementing quality assurance protocols at every development stage, rather than depending exclusively on end-stage validation testing, ensures the final software architecture meets customer demand specifications and aligns with business objective parameters. Through continuous process improvement methodologies and systematic lean thinking application, startups can architect software solutions that not only satisfy but exceed customer expectation benchmarks, establishing foundational frameworks for sustained long-term success trajectories.
For startups, Lean Development offers a smarter way to build software. It promotes agility, customer focus, and efficiency that are critical ingredients for success. By embracing the top seven principles, startups can bring better products to market faster, with fewer resources and more certainty.

This article is for Agile practitioners, Scrum Masters, and project managers looking to understand the difference between velocity and capacity. If you’re searching for clarity on the query “agile velocity vs capacity,” you’re in the right place. We’ll compare and contrast these two essential Agile metrics, explain why understanding the difference matters for Agile success, and provide actionable best practices for your team.
Many Agile teams confuse velocity with capacity. Both measure work, but they serve different purposes. Understanding the difference between agile velocity vs capacity is key to better planning and execution. The primary focus of these metrics is not just tracking work, but ensuring the delivery of business value.
Agile’s rise in popularity is no surprise—it helps teams deliver on time. Velocity tracks completed work over time, guiding future estimates. Capacity measures available resources, ensuring realistic commitments. In Agile planning, capacity represents the total amount of work a team can realistically handle in a sprint, taking into account team availability and workload.
Misusing these metrics can lead to missed deadlines and inefficiencies. High velocity alone does not guarantee business value, so the primary focus should remain on outcomes rather than just numbers. Used correctly, they boost productivity and streamline workflows.
In this blog, we’ll break down agile velocity vs capacity, highlight their differences, and share best practices to ensure agile success for you. Understanding these concepts is essential for effective project management, as it enables better planning, resource allocation, and successful Agile project delivery.
Summary: Agile Velocity vs Capacity
Both Agile velocity and capacity are essential for effective project management and sprint planning. Velocity measures past performance, while capacity estimates future availability
Metrics are the backbone of effective Agile project management. They provide teams with the data needed to measure progress, identify bottlenecks, and make informed decisions. By leveraging the right metrics, Agile teams can optimize performance, improve predictability, and deliver greater business value.
Modern Agile methodologies rely on a variety of metrics to track and improve team performance. Among these, velocity and capacity are two of the most critical for monitoring team throughput and orchestrating strategic resource allocation in software development environments.
Velocity tracking and capacity management serve as the cornerstone metrics for sophisticated project orchestration in Agile development ecosystems. Velocity analytics measure the quantifiable work units that development teams successfully deliver during defined sprint iterations, utilizing story points, task hours, or feature completions as measurement standards. Within Scrum frameworks, a scrum team uses these metrics to assess their performance, improve sprint planning, and ensure successful delivery of project goals.
Capacity planning algorithms analyze team bandwidth by evaluating developer availability, skill sets, technical constraints, and historical performance data to establish realistic delivery expectations. Through continuous monitoring of these interconnected metrics, Agile practitioners can execute predictive planning, establish achievable sprint commitments, and maintain consistent delivery cadences that align with stakeholder expectations and business objectives.
Mastering the intricate relationship between velocity analytics and capacity optimization proves indispensable for development teams pursuing maximum productivity efficiency and sustainable value delivery in complex software development initiatives. Machine learning algorithms increasingly assist teams in analyzing velocity trends, predicting capacity fluctuations based on team composition changes, and identifying optimization opportunities through historical sprint data analysis.
In the comprehensive sections that follow, we’ll examine the technical foundations of these measurement frameworks, explore advanced calculation methodologies including weighted story point systems and capacity utilization algorithms, and demonstrate why these metrics remain absolutely critical for achieving consistent success in Agile software development and strategic project management execution.
Transition: With a solid understanding of why metrics matter, let’s dive into the specifics of Agile velocity and how it’s calculated.
Agile velocity measures how much work the team completes during a single iteration or sprint, typically in story points (Fact: 2, 3). It is a retrospective measurement that helps teams understand their past performance and forecast future work.
Velocity is calculated by averaging the total story points completed over multiple sprints. Here’s how to calculate Agile velocity:
Example:
Average velocity = (30 + 25 + 35) ÷ 3 = 30 story points per sprint
Each sprint's completed story points is a data point used to calculate velocity. The average number of story points delivered in past sprints helps teams calculate velocity for future planning.
Velocity is not fixed—it evolves as teams improve. Story point estimation and assigning story points are fundamental to measuring velocity, and relative estimation is used to compare task complexity. New teams may start with lower velocity, which grows as they refine their processes. However, it is not a direct measure of efficiency. High velocity does not always mean better performance.
Understanding velocity helps teams make data-driven decisions. Teams measure velocity by tracking the number of story points completed over multiple sprints, and team velocity provides a basis for forecasting future work. It ensures sprint planning aligns with past performance, reducing the risk of overcommitment.
Story points are a unit of measure for effort, and accurate story point estimation is essential for reliable velocity metrics.
Transition: Now that we've covered how velocity works, let's look at how capacity complements it in Agile planning.
Agile capacity refers to the work that can be accomplished within a specific timeframe, like a sprint (Fact: 1). It is a prospective measurement that estimates the team’s future availability to take on work.
Capacity is based on available working hours in a sprint. It factors in team size, work hours per day, and non-project time. Agile capacity is typically quantified in terms of total available development hours (Fact: 3).
Steps to Calculate Agile Capacity:
Example:
If one member is on leave for 2 days, the adjusted capacity is: (4 × 8 × 10) + (1 × 8 × 8) = 384 hours
Capacity fluctuates based on external factors such as:
Measuring capacity involves assessing each team member’s availability and individual capacity to ensure accurate planning and workload management. Tracking it ensures smoother sprint execution and better resource management.
Transition: With both velocity and capacity defined, let’s directly compare these two metrics and clarify their key differences for Agile teams.
The main difference between Agile velocity and capacity is that velocity measures past performance while capacity estimates future availability (Fact: 1, 2). Velocity is a retrospective measurement, while capacity is a prospective measurement.
Agile velocity is typically measured in story points, while Agile capacity is quantified in terms of total available development hours (Fact: 3).
While both velocity and capacity deal with workload, they serve different roles. The confusion arises when teams assume high capacity means high velocity. Both measure work, but they serve different purposes. Capacity agile velocity refers to using both metrics together for more effective sprint planning and project management.
But velocity depends on factors beyond available hours—such as efficiency, experience, and blockers. A team's capacity is the total potential workload they can take on, while the team's output is the actual work delivered during a sprint.
For example, a team with a capacity of 400 hours may complete only 30 story points. The work done depends on efficiency, not just available hours.
A team may have 500 hours of capacity but deliver only 35 story points. Predictability relies on velocity, while availability depends on capacity.
For example, two teams with the same capacity (400 hours) may have different velocities—one completing 40 story points, another only 25. Experience and engineering efficiency are the reasons behind this gap.
Example:
External factors impact both, but their effects differ. Capacity loss is predictable, while velocity fluctuations are harder to forecast.
When planning for the upcoming sprint, teams use both metrics to forecast and allocate tasks effectively for the next iteration.
Clear sprint goals help align the planned work with both the team’s capacity and their past velocity, ensuring that objectives are realistic and achievable within the sprint.
If a team has a velocity of 30 story points but a capacity of 500 hours, taking on 50 story points will likely lead to failure. Sprint planning should balance both, prioritizing past velocity over raw capacity.
For example, a team with a velocity of 25 story points may improve to 35 story points after optimizing workflows. Capacity (e.g., 400 hours) remains the same unless sprint length or team size changes.
Velocity improves with Agile maturity, while capacity remains a logistical factor. Tracking these changes enables teams to plan for future iterations and supports continuous improvement by monitoring Lead Time for Changes.
Using capacity as a performance metric can mislead teams. Many teams fall into the trap of misusing these metrics, focusing on numbers rather than meaningful insights, which leads to measurement theater. A high capacity does not mean a team should take on more work. Similarly, a drop in velocity does not always indicate lower performance—it may mean more complex work was tackled.
Example:
Misinterpreting these metrics can lead to overloading, burnout, and poor sprint outcomes. Focusing solely on maximizing velocity can undermine a sustainable pace and negatively impact team well-being. It is important to use metrics effectively to measure the team’s productivity and team’s performance, ensuring they are used to enhance productivity and support sustainable growth, rather than causing burnout.
Transition: Now that you understand the differences between velocity and capacity, let’s explore how to plan capacity effectively in Agile projects.
Capacity planning represents a critical algorithmic component within Agile project management frameworks. It ensures development teams establish realistic sprint commitments through sophisticated resource allocation methodologies.
Strategic capacity planning implementations not only establish sustainable development velocity patterns but also optimize team performance through intelligent workload balancing algorithms and burnout risk mitigation strategies.
When development teams consistently align sprint commitments with empirically-measured Agile capacity baselines, they achieve superior positioning for high-quality deliverable execution within predetermined temporal constraints.
This disciplined project management methodology enables teams to dynamically adapt to evolving requirement specifications, maintain laser focus on sprint objective achievement, and ultimately drive customer satisfaction metrics through reliable delivery pipeline optimization and predictable throughput patterns.
Transition: With capacity planning in place, it’s important to understand how Agile velocity compares to traditional project management metrics.
Agile velocity has fundamentally transformed project management paradigms by leveraging collective team output measured in story points, revolutionizing traditional individual performance tracking approaches.
By harnessing data on story point completion across sprint cycles, Agile velocity transforms historical performance analytics into strategic forecasting capabilities and optimizes resource allocation processes. This approach enhances accuracy and delivers comprehensive visibility into team capabilities, enabling organizations to streamline forecasting operations and establish more achievable project commitments.
By leveraging comprehensive data analytics from previous sprint cycles, teams can enhance decision-making capabilities, establish realistic performance targets, and streamline overall execution efficiency in subsequent development iterations.
Transition: Beyond metrics, effective communication and collaboration are essential for Agile teams to achieve their goals.
In Agile project management frameworks, effective communication protocols and cross-functional collaboration among development teams are critical success factors for achieving project deliverables and sprint objectives.
This collaborative methodology not only enhances data-driven decision-making processes but also enables proactive identification and mitigation of project risks during early development phases.
Advanced collaboration frameworks facilitate the detection of potential bottlenecks, resource constraints, and technical debt accumulation that could impact sprint velocity and overall project timeline adherence.
When cross-functional team members operate with seamless integration and optimized communication workflows, they demonstrate significantly higher probability of delivering high-quality software products that meet acceptance criteria and achieve successful project outcomes.
This systematic approach to Agile collaboration leverages team synergies, reduces development cycle times, and ensures consistent delivery of value-driven features that align with business objectives and customer requirements throughout the entire development lifecycle.
Transition: Effective collaboration sets the stage for continuous improvement, a core principle of Agile methodology.
Continuous improvement serves as the cornerstone of Agile methodology, driving teams to systematically evaluate and optimize their operational workflows.
Regular retrospective sessions and structured feedback frameworks provide comprehensive opportunities to identify optimization areas, refine operational practices, and implement transformative changes that drive superior project outcomes.
By strategically focusing on both velocity optimization and capacity management, Agile development teams can streamline their delivery pipelines, maintain sustainable operational pace, and achieve elevated levels of customer satisfaction while maximizing business value generation across all project deliverables.
Transition: To put these concepts into practice, let’s review the best practices for balancing Agile velocity and capacity.
Here are some best practices to follow to strike the right balance between Agile velocity and capacity:
Transition: By following these best practices, your team can maximize the benefits of both metrics and achieve Agile success.
Understanding the difference between velocity and capacity is key to Agile success.
Companies can enhance agility by integrating AI into their engineering process with Typo. It enables AI-powered engineering analytics that tracks both metrics, identifies bottlenecks, and optimizes sprint planning. Automated fixes and intelligent recommendations help teams improve velocity without overloading capacity.
By leveraging AI-driven insights, businesses can make smarter decisions and accelerate delivery.
Want to see how AI can streamline your Agile processes?

Many confuse engineering management with project management. The overlap makes it easy to see why.
Both involve leadership, planning, and execution. Both drive projects to completion. But their goals, focus areas, and responsibilities differ significantly.
This confusion can lead to hiring mistakes and inefficient workflows.
A project manager ensures a project is delivered on time and within scope. Project management generally refers to managing a singular project. An engineering manager looks beyond a single project, focusing on team growth, technical strategy, and long-term impact.
Strong communication skills and soft skills are essential for both roles, as they help coordinate tasks, clarify priorities, and ensure team understanding—key factors for project success and effective collaboration. Both engineering and project management roles require excellent communication skills.
Understanding these differences is crucial for businesses and employees alike.
Let’s break down the key differences.
Engineering management focuses on leading engineering teams and driving technical success. It involves decisions related to engineering resource allocation, team growth, and process optimization, as well as addressing the challenges facing engineering managers. Most engineering managers have an engineering background, which is essential for technical leadership and effective decision-making.
In a software company, an engineering manager oversees multiple teams building a new AI feature. The engineering manager leads the engineering team, providing technical leadership and guiding them through complex problems. Providing technical leadership and guidance includes making architectural judgment calls in engineering management.
Their role extends beyond individual projects. They also have to mentor engineers and help them adjust to workflows. Mentoring, coaching, and developing engineers is a responsibility of engineering management. Technological problem solving ability and strong problem solving skills are crucial for addressing technical challenges and optimizing processes.
Engineering project management focuses on delivering specific projects on time and within scope. Project planning and developing a detailed project plan are crucial initial steps, enabling project managers to outline objectives, allocate resources, and establish timelines for successful execution.
For the same AI feature, the project manager coordinates deadlines, assigns tasks, and tracks progress. Project management involves coordinating resources, managing risks, and overseeing the project lifecycle from initiation to closure. Project managers oversee the entire process from planning to completion across multiple departments. They manage dependencies, remove roadblocks, and ensure developers have what they need.
Defining project scope, setting clear project goals, and leading a dedicated project team are essential to ensure the project finishes successfully. A project management professional is often required to manage complex engineering projects, ensuring effective risk management and successful project delivery.
Both engineering management and engineering project management fall under classical project management.
However, their roles differ based on the organization's structure.
In Engineering, Procurement, and Construction (EPC) organizations, project managers play a central role, while engineering managers operate within project constraints.
In contrast, in pure engineering firms, the difference fades, and project managers often assume engineering management responsibilities.
Engineering management focuses on the broader development of engineering teams and processes. It is not tied to a single project but instead ensures long-term success by improving technical strategy.
On the other hand, engineering project management is centered on delivering a specific project within defined constraints. The project manager ensures clear goals, proper task delegation, and timely execution. Once the project is completed, their role shifts to the next initiative.
The core lies in time and continuity. Engineering managers operate on an ongoing basis without a defined endpoint. Their role is to ensure that engineering teams continuously improve and adapt to evolving technologies.
Even when individual projects end, their responsibilities persist as they focus on optimizing workflows.
Engineering project managers, in contrast, work within fixed project timelines. Their focus is to ensure that specific engineering initiatives are delivered on time and under budget.
Each software project has a lifecycle, typically consisting of phases such as — initiation, planning, execution, monitoring, and closure.
For example, if a company is building a recommendation engine, the engineering manager ensures the team is well-trained and the technical process are set up for accuracy and efficiency. Meanwhile, the project manager tracks the AI model's development timeline, coordinates testing, and ensures deployment deadlines are met.
Once the recommendation engine is live, the project manager moves on to the next project, while the engineering manager continues refining the system and supporting the team.
Engineering managers allocate resources based on long-term strategy. They focus on team stability, ensuring individual engineers work on projects that align with their expertise.
Project managers, however, use temporary resource allocation models. They often rely on tools like RACI matrices and effort-based planning to distribute workload efficiently.
If a company is launching a new mobile app, the project manager might pull engineers from different teams temporarily, ensuring the right expertise is available without long-term restructuring.
Engineering management establishes structured frameworks like communities of practice, where engineers collaborate, share expertise, and refine best practices.
Technical mentorship programs ensure that senior engineers pass down insights to junior team members, strengthening the organization's technical depth. Additionally, capability models help map out engineering competencies.
In contrast, engineering project management prioritizes short-term knowledge capture for specific projects.
Project managers implement processes to document key artifacts, such as technical specifications, decision logs, and handover materials. These artifacts ensure smooth project transitions and prevent knowledge loss when team members move to new initiatives.
Engineering managers operate within highly complex decision environments, balancing competing priorities like architectural governance, technical debt, scalability, and engineering culture.
They must ensure long-term sustainability while managing trade-offs between innovation, cost, and maintainability. Decisions often involve cross-functional collaboration, requiring alignment with product teams, executive leadership, and engineering specialists.
Engineering project management, however, works within defined decision constraints. Their focus is on scope, cost, and time. Project managers are in charge of achieving as much balance as possible among the three constraints.
They use structured frameworks like critical path analysis and earned value management to optimize project execution.
While they have some influence over technical decisions, their primary concern is delivering within set parameters rather than shaping the technical direction.
Engineering management performance is measured on criterias like code quality improvements, process optimizations, mentorship impact, and technical thought leadership. The focus is on continuous improvement not immediate project outcomes.
Engineering project management, on the other hand, relies on quantifiable delivery metrics.
Project manager's success is determined by on-time milestone completion, adherence to budget, risk mitigation effectiveness, and variance analysis against project baselines. Engineering metrics like cycle times, defect rates, and stakeholder satisfaction scores ensure that projects remain aligned with business objectives.
Engineering managers drive value through capability development and innovation enablement. They focus on building scalable processes and investing in the right talent.
Their work leads to long-term competitive advantages, ensuring that engineering teams remain adaptable and technically strong.
Engineering project managers create value by delivering projects predictably and efficiently. Their role ensures that cross-functional teams work in sync and delivery remains structured.
By implementing agile workflows, dependency mapping, and phased execution models, they ensure business goals are met without unnecessary delays.
Engineering management requires deep engagement with leadership, product teams, and functional stakeholders.
Engineering managers participate in long-term planning discussions, ensuring that engineering priorities align with broader business goals. They also establish feedback loops with teams, improving alignment between technical execution and market needs.
Engineering project management, however, relies on temporary, tactical stakeholder interactions.
Project managers coordinate status updates, cross-functional meetings, and expectation management efforts. Their primary interfaces are delivery teams, sponsors, and key decision-makers involved in a specific initiative.
Unlike engineering managers, who shape organizational direction, project managers ensure smooth execution within predefined constraints. Engineering managers typically provide technical guidance to project managers, ensuring alignment with broader technical strategies.
Continuous improvement serves as the cornerstone of effective engineering management in today's rapidly evolving technological landscape. Engineering teams must relentlessly optimize their processes, enhance their technical capabilities, and adapt to emerging challenges to deliver high-quality software solutions efficiently. Engineering managers function as catalysts in cultivating environments where continuous improvement isn't merely encouraged—it's embedded into the organizational DNA. This strategic mindset empowers engineering teams to maintain their competitive edge, drive innovation, and align with dynamic business objectives that shape market trajectories.
To accelerate continuous improvement initiatives, engineering management leverages several transformative strategies:
Regular feedback and assessment: Engineering managers should systematically collect and analyze feedback from engineers, stakeholders, and end-users to identify optimization opportunities across the development lifecycle.
Root cause analysis: When engineering challenges surface, effective managers dive deep beyond symptomatic fixes to uncover fundamental issues that impact system reliability and performance.
Experimentation and testing: Engineering teams flourish when empowered to experiment with cutting-edge tools, methodologies, and frameworks that can revolutionize project outcomes and technical excellence.
Knowledge sharing and collaboration: Continuous improvement thrives in ecosystems where technical expertise flows seamlessly across organizational boundaries and team structures.
Training and development: Strategic investment in engineer skill development ensures technical excellence and organizational readiness for emerging technological paradigms.
By implementing these advanced strategies, engineering managers establish cultures of continuous improvement that drive systematic refinement of technical processes, skill development, and project delivery capabilities. This holistic approach not only enables engineering teams to achieve tactical objectives but also strengthens organizational capacity to exceed business goals and deliver exceptional value to customers through innovative solutions.
Continuous improvement also represents a critical convergence point for project management excellence. Project managers and engineering managers should collaborate intensively to identify areas where project execution can be enhanced, risks can be predicted and mitigated, and project requirements can be more precisely met through data-driven insights. By embracing a continuous improvement philosophy, project teams can respond more dynamically to changing requirements, prevent scope creep through predictive analytics, and ensure successful delivery of complex engineering initiatives.
When examining engineering management versus project management, continuous improvement emerges as a fundamental area of strategic alignment. While project management concentrates on tactical delivery of individual initiatives, engineering management encompasses strategic optimization of technical resources, architectural decisions, and cross-functional processes spanning multiple teams and projects. By applying continuous improvement principles across both disciplines, organizations can achieve unprecedented levels of efficiency, innovation velocity, and business objective alignment.
Ultimately, continuous improvement is indispensable for engineering project management, enabling teams to deliver solutions that exceed defined constraints, technical specifications, and business requirements. By fostering cultures of perpetual learning and adaptive optimization, engineering project managers and engineering managers ensure their teams remain prepared for next-generation challenges while positioning the organization for sustained competitive advantage and long-term market leadership.
Visibility is key to effective engineering and project management. Without clear insights, inefficiencies go unnoticed, risks escalate, and productivity suffers. Engineering analytics bridge this gap by providing real-time data on team performance, code quality, and project health.
Typo enhances this further with AI-powered code analysis and auto-fixes, improving efficiency and reducing technical debt. It also offers developer experience visibility, helping teams identify bottlenecks and streamline workflows.
With better visibility, teams can make informed decisions, optimize resources, and accelerate delivery.
.png)
In the ever-changing world of software development, tracking progress and gaining insights into your projects is crucial. Software development teams rely on project management tools like Jira to organize and track their work. While GitHub Analytics provides developers and teams with valuable data-driven intelligence, relying solely on GitHub data may not provide the full picture needed for making informed decisions. Integrating tools from the Atlassian Marketplace can help save time and reduce context switching by streamlining workflows and automating updates. Integrating Jira and GitHub reduces context switching for development teams by minimizing the need to move between different tools, allowing them to focus more on coding and less on manual updates.
By integrating GitHub Analytics with JIRA, engineering teams can gain a more comprehensive view of their development workflows, enabling them to take more meaningful actions within one platform for a unified workflow.
The strategic convergence of GitHub and JIRA repositories establishes a comprehensive ecosystem that leverages the combined capabilities of two fundamental development platforms within modern software engineering workflows. Through systematic integration of version control systems with project management infrastructure, development teams architect a unified operational framework that optimizes process efficiency and facilitates enhanced cross-functional collaboration throughout organizational hierarchies. This technological synthesis enables teams to establish direct traceability matrices between code modifications and project deliverables, thereby streamlining progress monitoring, issue resolution protocols, and stakeholder alignment mechanisms. Machine learning-enhanced project visibility ensures that development teams can minimize cognitive load associated with context switching, maintain sustained focus on core development activities, and significantly amplify productivity metrics across sprint cycles. Whether orchestrating multi-repository architectures or coordinating complex project dependencies, the GitHub-JIRA integration paradigm ensures that development workflows achieve optimal efficiency parameters, collaborative processes maintain seamless operational continuity, and engineering teams consistently deliver enterprise-grade code solutions with measurable quality assurance.
GitHub Analytics offers valuable insights into:
However, GitHub Analytics primarily focuses on repository activity and code contributions. It lacks visibility into broader project management aspects such as sprint progress, backlog prioritization, and cross-team dependencies. While GitHub has some built-in analytics, it often requires syncing with other tools to get a complete view of git activity and ensure seamless collaboration across platforms. This limited perspective can hinder a team’s ability to understand the complete picture of their development workflow and make informed decisions.
JIRA is a widely used platform for issue tracking, sprint planning, and agile project management. When combined with GitHub Analytics, it creates a powerful ecosystem that integrates multiple tools into one platform, acting as one tool for managing both code and project tasks, and:
JIRA delivers comprehensive, enterprise-grade integration capabilities engineered to seamlessly orchestrate your GitHub repositories within sophisticated project management ecosystems. The GitHub for JIRA application revolutionizes collaborative workflows by establishing intelligent linkages between GitHub commits, branch structures, and pull request lifecycles to designated JIRA issue tracking entities, thereby furnishing project stakeholders and development teams with unprecedented visibility into end-to-end development operations and deployment pipelines.
Through advanced smart commit functionality, development practitioners can dynamically update JIRA issue states directly from GitHub commit message protocols, facilitating automated status transitions and temporal tracking mechanisms without disrupting their integrated development environments or coding workflows. Furthermore, this robust integration architecture empowers cross-functional teams to instantiate branch creation processes and initialize pull request workflows directly from JIRA issue contexts, ensuring comprehensive work item traceability from initial planning phases through production deployment cycles. These sophisticated built-in integration tools enable organizations to optimize development workflow orchestration, maintain repository governance standards, and establish transparent communication channels across all project stakeholders while enhancing overall development lifecycle efficiency.
Beyond JIRA's built-in capabilities, which serve as foundational elements for basic project management and issue tracking, a comprehensive ecosystem of sophisticated third-party integration applications emerges to dramatically transform and enhance the intricate connection between GitHub and JIRA platforms, establishing unprecedented levels of workflow automation and collaborative efficiency. These advanced integration solutions, including powerful tools such as Unito and Git Integration for JIRA, represent cutting-edge developments in the realm of development operations, offering an extensive array of sophisticated features like bi-directional synchronization capabilities that ensure seamless data flow between platforms, intelligent automated workflow updates that respond dynamically to repository changes and issue status modifications, comprehensive reporting mechanisms that provide detailed analytics and insights into development progress, commit tracking systems that maintain complete visibility over code changes and their relationship to project requirements, and branch management features that enable developers to monitor and coordinate distributed development efforts across multiple feature branches and release cycles.
Through the implementation of these sophisticated integration tools, project managers and development teams can achieve unprecedented levels of commit and branch tracking effectiveness, enabling them to maintain comprehensive oversight of code evolution while simultaneously automating traditionally repetitive and time-consuming tasks such as status updates, issue transitions, and progress reporting, all while customizing their development workflows to precisely fit the unique operational requirements, team dynamics, and project complexities that characterize their specific organizational environments. Furthermore, these third-party applications provide significantly enhanced collaboration features that encompass real-time communication capabilities, automated notification systems, and integrated review processes, making it substantially easier for distributed teams to maintain alignment across different time zones and geographical locations while enabling project managers to exercise comprehensive oversight and maintain strategic visibility across multiple concurrent projects, ensuring that development initiatives remain coordinated and aligned with broader organizational objectives. By strategically leveraging these sophisticated integration capabilities, development teams can maximize the combined value proposition of both JIRA's project management strengths and GitHub's source code management capabilities, creating a unified development ecosystem that ensures their software development processes and project management workflows remain perpetually synchronized, optimized, and aligned with industry best practices for modern software delivery.
Automation serves as the foundational architecture driving sophisticated GitHub and JIRA integration ecosystems. Through the implementation of intelligent automated rule engines and webhook-driven workflows, development teams can establish real-time synchronization mechanisms that dynamically update JIRA issue tracking based on comprehensive GitHub repository activities, including pull request merge operations, commit push events, and branch management actions. This automation framework eliminates the necessity for manual data entry processes and context switching overhead, enabling software engineers to maintain focused development cycles while simultaneously providing project stakeholders and Scrum masters with instantaneous visibility into sprint progress and delivery pipeline status. Advanced automation orchestration not only reduces cognitive load and operational friction but also ensures data integrity, cross-platform consistency, and audit trail compliance across integrated development environments. Through sophisticated automated workflow configurations, engineering organizations can optimize their DevOps processes, implement comprehensive code change tracking with full traceability matrices, and maintain continuous project velocity with enhanced operational efficiency and reduced time-to-market cycles.
Start leveraging the power of integrated analytics with tools like Typo, a dynamic platform designed to optimize your GitHub and JIRA experience. To connect Jira with external platforms, you typically need to follow a setup process that involves installation, configuration, and granting the necessary permissions. As part of this process, you may be required to link your GitHub account to authorize and enable the integration between your repositories and Jira. Typo and similar apps support integration with platforms like GitHub Enterprise Server and Azure DevOps, as well as compatibility with both Jira Cloud and Jira Server, ensuring seamless integration regardless of your Jira deployment. These integrations often do not require you to write code, simplifying the setup process for teams. Whether you’re working on a startup project or managing an enterprise-scale development team, such tools can offer powerful analytics tools tailored to your specific needs.
While orchestrating the sophisticated integration between GitHub and JIRA repositories can fundamentally transform and streamline your development team's operational workflows, there are prevalent implementation pitfalls that can significantly impede your organizational success and operational efficiency. One particularly critical challenge involves inadequate configuration protocols of the integration architecture, which can result in fragmented or compromised data synchronization mechanisms between these collaborative platforms, thereby undermining the integrity of your development ecosystem. Another substantial obstacle comprises neglecting to leverage intelligent commit functionalities, which consequently diminishes the capability to dynamically update JIRA issue tracking directly from GitHub commit messaging protocols and severely compromises valuable project traceability and audit mechanisms. Development teams should also meticulously avoid circumventing the establishment of comprehensive automation rule frameworks, as this oversight can precipitate unnecessary manual intervention requirements and substantially reduce overall productivity optimization. By ensuring your integration architecture is comprehensively configured with precision, maximizing utilization of intelligent commit strategies, and implementing robust automated update protocols, your development organization can maintain optimal data integrity standards, foster enhanced cross-functional collaboration paradigms, and achieve maximum operational value from your GitHub and JIRA integration ecosystem.
While GitHub Analytics is a valuable tool for tracking repository activity, integrating it with JIRA unlocks deeper engineering insights, allowing teams to make smarter, data-driven decisions. By bridging the gap between code contributions and project management, teams can improve efficiency, enhance collaboration, and ensure that engineering efforts align with business goals.
Whether you aim to enhance software delivery, improve team collaboration, or refine project workflows, Typo provides a flexible, data-driven platform to meet your needs.
1. How to integrate GitHub with JIRA for better analytics?
2. What are some common challenges in integrating JIRA with Github?
3. How can I ensure the accuracy of data in my integrated GitHub and JIRA analytics?
.png)
Software teams relentlessly pursue rapid, consistent value delivery. Yet, without proper metrics, this pursuit becomes directionless.
Many organizations across various industries track and improve cycle time to enhance process efficiency and workflow optimization.
While engineering productivity is a combination of multiple dimensions, issue cycle time acts as a critical indicator of team efficiency. Cycle time includes all steps, activities, and tasks involved in the production process, providing a comprehensive view of how work moves from start to finish.
Simply put, this metric reveals how quickly engineering teams convert requirements into deployable solutions. Accurate measurement of issue cycle time is essential, as it ensures the metric reliably reflects engineering efficiency and supports informed decision-making.
By understanding and optimizing issue cycle time, teams can accelerate delivery and enhance the predictability of their development practices.
In this guide, we discuss cycle time’s significance and provide actionable frameworks for measurement and improvement.
Issue cycle time measures the duration between when work actively begins on a task and its completion. This is the actual time spent on the task, excluding any waiting periods or idle time.
This metric specifically tracks the time developers spend actively working on an issue, excluding external delays or waiting periods.
Unlike lead time, which includes all elapsed time from issue creation, cycle time focuses purely on active development effort. Cycle time calculation and the use of a cycle time formula are essential for quantifying this metric, helping teams identify bottlenecks, benchmark performance, and find opportunities for improvement.
Cycle time can also be measured over different time periods, such as monthly or quarterly, to evaluate team performance and process efficiency.
Learn more about measuring and improving engineering productivity.
In Agile and Scrum methodologies, a user story represents a unit of work or requirement within software development projects. Tracking the cycle time of user stories helps teams understand and optimize their process efficiency.
Understanding these components allows teams to identify bottlenecks and optimize their development workflow effectively. Effective measurement of Issue Cycle Time requires tracking status changes in project management tools to ensure data accuracy.
Here’s why you must track issue cycle time:
Issue cycle time is one of the most valuable metrics for software development teams, as it helps measure how efficiently issues are resolved from start to finish. Cycle time data provides actionable insights for process improvement, enabling teams to identify bottlenecks, allocate resources more effectively, and drive continuous improvement.
Tracking issue cycle time allows you to spot inefficiencies, understand team performance, and make informed decisions to optimize your workflow. By analyzing cycle time data, you can also ensure that your process improvements are based on accurate, relevant information.
Issue Cycle Time and Pull Request Cycle Time are complementary metrics, each providing unique insights into different aspects of the software development process.
Issue cycle time directly correlates with team output capacity. Shorter cycle times allows teams to complete more work within fixed timeframes. So resource utilization is at peak. This accelerated delivery cadence compounds over time, allowing teams to tackle more strategic initiatives rather than getting bogged down in prolonged development cycles.
By tracking cycle time metrics, teams can pinpoint specific stages where work stalls. This reveals process inefficiencies, resource constraints, or communication gaps that break flow. Data-driven bottleneck identification allows targeted process improvements rather than speculative changes.
Rapid cycle times help build tighter feedback loops between developers, reviewers, and stakeholders. When issues move quickly through development stages, teams maintain context and momentum. When collaboration is streamlined, handoff friction is reduced. And there's no knowledge loss between stages, either.
Consistent cycle times help in reliable sprint planning and release forecasting. Teams can confidently estimate delivery dates based on historical completion patterns. This predictability helps align engineering efforts with business goals and improves cross-functional planning.
Quick issue resolution directly impacts user experience. When teams maintain efficient cycle times, they can respond quickly to customer feedback and deliver improvements more frequently. This responsiveness builds trust and strengthens customer relationships.
Grasping the intricate distinction between cycle time and lead time has become fundamental for organizations seeking to optimize their engineering operations and drive operational excellence. While both serve as critical performance indicators in sophisticated process management frameworks, they measure distinctly different dimensions of workflow efficiency, each providing unique insights into operational bottlenecks and optimization opportunities.
Cycle time represents the precise duration of active engagement—the actual hands-on working time invested from the moment development teams initiate productive effort until task completion is achieved. This metric deliberately excludes idle periods, queue waiting times, and external dependency delays, focusing exclusively on the value-adding activities and productive effort contributed by engineering teams. By analyzing cycle time patterns, organizations can assess their teams’ actual productivity capacity and identify internal process inefficiencies that directly impact development velocity.
Lead time, conversely, encompasses the comprehensive end-to-end journey—capturing the total elapsed duration from the initial customer request submission or ticket creation through to the final delivery of the completed solution to stakeholders. This holistic measurement incorporates all waiting periods, cross-functional handoffs, approval cycles, and any external dependencies or delays that may materialize throughout the entire process lifecycle. For example, material procurement is a common external dependency that can significantly extend lead time, as teams may need to wait for necessary materials before proceeding. Lead time analysis reveals the complete customer experience timeline and exposes systemic delays that may frustrate end-users despite efficient internal development processes.
By implementing comprehensive tracking mechanisms for both cycle time and lead time metrics, organizations gain unprecedented visibility into their operational performance landscape and can make data-driven optimization decisions. Monitoring these complementary indicators enables teams to pinpoint specific bottlenecks—whether they originate from sluggish handoff procedures, resource allocation constraints, or external vendor dependencies that create process friction. This analytical insight empowers targeted process enhancement initiatives, such as streamlining complex approval workflows, implementing automated deployment pipelines, or eliminating manual intervention steps, which collectively reduce operational overhead and significantly enhance customer satisfaction metrics. Ultimately, understanding and systematically optimizing both cycle time and lead time performance indicators empowers development teams to deliver exceptional value with greater velocity and predictable consistency, fostering a culture of continuous improvement that permeates the entire software development lifecycle.
The development process is a journey that can be summed up in three phases. By analyzing each phase, teams can gain valuable cycle time insights that help identify bottlenecks and optimize their workflow. Teams should regularly analyze phase durations to identify opportunities to optimize processes and maintain engineering efficiency. Let’s break these phases down:
The initial phase includes critical pre-development activities that significantly impact
overall cycle time. This period begins when a ticket enters the backlog and ends when active development starts.
Teams often face delays in ticket assignment due to unclear prioritization frameworks or manual routing processes. One of the reasons behind this is resource allocation, which frequently occurs when assignment procedures lack automation.
Implementing automated ticket routing and standardized prioritization matrices can substantially reduce initial delays.
The core development phase represents the most resource-intensive segment of the cycle. Development time varies based on complexity, dependencies, and developer expertise.
Common delay factors are:
Success in this phase demands precise requirement documentation and proactive dependency management, both of which contribute to optimizing Lead Time for Changes. One should also establish escalation paths. Teams should maintain living documentation and implement pair programming for complex tasks.
The final phase covers all post-development activities required for production deployment.
This stage often becomes a significant bottleneck due to:
How can this be optimized? By:
Each phase comes with many optimization opportunities. Teams should measure phase-specific metrics to identify the highest-impact improvement areas. Regular analysis of phase durations allows targeted process refinement, which is critical to maintaining software engineering efficiency.
Effective cycle time measurement requires the right tools and systematic analysis approaches. Measuring cycle time is crucial for improving operational performance and process optimization, as it helps identify bottlenecks and drive efficiency. Cycle time data, when collected and maintained with proper data hygiene, is valuable for tracking and improving efficiency across departments, supporting decision-making and continuous improvement. Issue cycle time can be measured at the organizational, team, and individual level using tools such as an Engineering Management Platform. Businesses must establish clear frameworks for data collection, benchmarking, and continuous monitoring to derive actionable insights.
Here’s how you can measure issue cycle time:
Modern development platforms offer integrated cycle time tracking capabilities. Tools like Typo automatically capture timing data across workflow states. Accurate measurement and proper data hygiene are essential for reliable cycle time tracking and meaningful analysis.
These platforms provide comprehensive dashboards displaying velocity trends, bottleneck indicators, and predictability metrics.
Integration with version control systems enables correlation between code changes and cycle time patterns. Advanced analytics features support custom reporting and team-specific performance views.
Benchmark definition requires contextual analysis of team composition, project complexity, and delivery requirements. Using the cycle time formula and performing cycle time calculation are key steps in establishing benchmarks and identifying improvement opportunities.
Start by calculating your team’s current average cycle time across different issue types. Factor in:
The right approach is to define acceptable ranges rather than fixed targets. Consider setting graduated improvement goals: 10% reduction in the first quarter, 25% by year-end.
Data visualization converts raw metrics into actionable insights. Cycle time scatter plots show completion patterns and outliers. Cumulative flow diagrams can also be used to show work in progress limitations and flow efficiency. Control charts track stability and process improvements over time. Visualizations provide cycle time insights that help teams understand their operational processes and identify opportunities to streamline operations.
Ideally businesses should implement:
By implementing these visualizations, businesses can identify bottlenecks and optimize workflows for greater engineering productivity.
Establish structured review cycles at multiple organizational levels. These could be:
These reviews should be templatized and consistent. The idea to focus on:
Pull Request (PR) cycle time, alternatively referred to as merge request cycle time in GitLab environments or code review cycle time across various version control systems, represents a fundamental performance indicator that engineering organizations leverage to quantify development velocity while simultaneously ensuring adherence to stringent code quality standards. This comprehensive metric encompasses the entire temporal journey of a proposed code modification, tracking its progression from initial submission through peer review processes, stakeholder approval workflows, automated testing pipelines, and ultimate integration into the primary codebase repository. Modern DevOps practitioners recognize PR cycle time as a critical component within broader DORA (DevOps Research and Assessment) metrics, alongside deployment frequency, lead time for changes, and mean time to recovery.
Through systematic monitoring and analysis of PR cycle time patterns, software engineering teams acquire actionable intelligence regarding the operational efficiency of their collaborative review mechanisms and continuous integration workflows. Extended PR cycle times frequently indicate underlying systemic bottlenecks, including reviewer capacity constraints, insufficient review guidelines documentation, inadequate automated testing coverage, or suboptimal branching strategies that can significantly impede development velocity and compromise overall operational effectiveness. Engineering leaders utilizing tools like GitHub Analytics, GitLab Insights, or specialized platforms such as LinearB and Pluralsight Flow can identify these friction points through comprehensive cycle time analysis. Conversely, optimized PR cycle time distributions facilitate rapid code integration cycles, substantially reducing cognitive overhead associated with context switching between multiple feature branches, while maintaining high development momentum and preserving engineering team productivity across distributed development environments.
Strategic optimization of PR cycle time not only accelerates the continuous delivery of feature enhancements, critical bug remediation, and security patches but also establishes a foundation for enhanced code quality through expeditious peer feedback loops and automated quality assurance processes. This systematic approach to cycle time optimization directly correlates with elevated customer satisfaction metrics, as engineering teams demonstrate increased agility in responding to evolving user requirements, competitive market pressures, and emerging technological opportunities. For engineering leadership and DevOps practitioners, PR cycle time serves as an indispensable diagnostic metric that illuminates opportunities for process refinement, workflow automation, and establishment of collaborative development environments that promote both individual productivity and collective code ownership principles within modern software delivery organizations.
Engineering analytics constitutes a comprehensive methodology for harnessing data-driven insights to optimize and enhance software development lifecycle (SDLC) workflows and operational efficiency. Through systematic data aggregation and advanced analytical processing of critical performance indicators including cycle time metrics, lead time optimization parameters, and pull request (PR) lifecycle analytics, development teams can strategically identify process bottlenecks, implement targeted workflow optimizations, and establish sustainable continuous improvement frameworks. This data-centric approach enables organizations to leverage historical performance patterns and predictive modeling techniques to anticipate potential impediments and proactively address inefficiencies before they impact delivery timelines.
How does engineering analytics transform organizational decision-making processes and operational methodologies? By implementing robust engineering analytics platforms, organizations fundamentally shift from intuition-based and anecdotal decision-making paradigms to sophisticated, data-driven strategic approaches that leverage machine learning algorithms and advanced statistical analysis. This transformation empowers cross-functional teams to precisely pinpoint operational inefficiencies through anomaly detection, systematically track and quantify the measurable impact of process modifications and infrastructure changes, and execute informed strategic decisions that significantly enhance overall operational efficiency and resource utilization. Contemporary engineering analytics solutions provide comprehensive dashboard interfaces, real-time monitoring capabilities, and automated reporting mechanisms that visualize key performance indicators (KPIs) and metrics, thereby facilitating trend analysis, comparative team performance assessments, and data-driven prioritization of targeted process improvement initiatives.
Through strategic implementation and adoption of engineering analytics methodologies, software development organizations can systematically streamline complex workflows, optimize resource allocation to reduce operational costs, and accelerate the delivery of higher-quality software products while maintaining stringent performance standards. This comprehensive analytical approach not only drives significant improvements in internal operational processes and team productivity metrics but also substantially enhances customer satisfaction levels by ensuring that development teams consistently meet or exceed established delivery expectations and service level agreements (SLAs), ultimately creating a competitive advantage through superior software delivery capabilities and enhanced organizational agility.
Optimizing operational expenditures comprises a critical objective for numerous enterprises, and leveraging cycle time and lead time analytics represents a data-driven methodology to achieve substantial cost reductions. By implementing comprehensive monitoring systems that analyze cycle time and lead time metrics, development teams can systematically identify operational inefficiencies including redundant workflow steps, extended idle periods, and duplicative processes that significantly escalate operational overhead and resource consumption.
Deploying targeted process optimization strategies—such as intelligent automation of repetitive computational tasks, standardization of workflow architectures, and systematic elimination of performance bottlenecks—enables organizations to minimize operational waste while enhancing throughput efficiency without compromising deliverable quality or customer satisfaction metrics. Machine learning-driven cost reduction algorithms ensure optimal resource allocation across development phases, guaranteeing that every operational step within the development pipeline contributes measurable value to the final deliverable.
Through continuous monitoring and analysis of cycle time and lead time performance indicators, organizations can systematically identify emerging opportunities for cost optimization, rapidly adapt to evolving business requirements, and maintain competitive differentiation in dynamic market conditions. The resultant outcome comprises a streamlined, highly agile operational framework that delivers enhanced value propositions to customers while maintaining rigorous expenditure controls and resource efficiency.
Streamlining workflows represents a critical optimization strategy for organizations pursuing enhanced operational efficiency, cost reduction, and accelerated value delivery to end-users through systematic process engineering. By leveraging advanced analytics platforms to examine cycle time metrics, lead time distributions, and throughput patterns, development teams can identify performance bottlenecks, resource constraints, and inefficiency patterns that impede optimal process flow. These analytical insights enable teams to pinpoint specific stages where work accumulates, where handoffs create delays, and where manual interventions introduce variability into otherwise streamlined operations.
Effective workflow optimization encompasses the systematic elimination of non-value-added activities, the implementation of intelligent automation frameworks for repetitive manual tasks, and the strategic allocation of computational and human resources to ensure seamless work progression from initiation to completion. By integrating sophisticated tracking tools such as application performance monitoring (APM) solutions, workflow orchestration platforms, and engineering analytics dashboards, teams can continuously monitor cycle time trends, identify recurring bottlenecks through pattern recognition algorithms, and implement data-driven process improvements that drive accelerated delivery cycles while maintaining quality standards. These tools analyze historical performance data, predict future resource requirements, and automatically trigger optimization recommendations based on established efficiency baselines and industry best practices.
A comprehensively streamlined workflow architecture not only accelerates development velocity and reduces time-to-market but also significantly enhances customer satisfaction metrics by enabling rapid response capabilities to user feedback, market fluctuations, and evolving business requirements. Through continuous workflow refinement methodologies, including lean process optimization, value stream mapping, and automated workflow intelligence, organizations establish competitive advantages, elevate team performance indicators, and cultivate a culture of continuous improvement that encompasses iterative optimization, predictive analytics, and adaptive process management capabilities that support sustainable long-term organizational success and operational excellence.
Focus on the following proven strategies to enhance workflow efficiency while maintaining output quality:
By consistently applying these best practices, engineering teams can reduce delays, achieve process optimization, and optimise issue cycle time for sustained success. Process optimization and project management methodologies play a crucial role in reducing cycle time and streamlining processes.
A mid-sized fintech company with 40 engineers faced persistent delivery delays despite having talented developers. Their average issue cycle time had grown to 14 days, creating mounting pressure from stakeholders and frustration within the team.
After analyzing their workflow data, they used cycle time data to identify bottlenecks and track improvements. This analysis provided valuable insights for continuous improvement.
They identified three critical bottlenecks:
Code Review Congestion: Senior developers were becoming bottlenecks with 20+ reviews in their queue, causing delays of 3-4 days for each ticket.
Environment Stability Issues: Inconsistent test environments led to frequent deployment failures, adding an average of 2 days to cycle time.
Unclear Requirements: Developers spent approximately 30% of their time seeking clarification on ambiguous tickets.
The team implemented a structured optimization approach:
Phase 1: Baseline Establishment (2 weeks)
Phase 2: Targeted Interventions (8 weeks)
Phase 3: Measurement and Refinement (Ongoing)
Results After 90 Days:
The most significant insight came from breaking down the cycle time improvements by phase: while the initial automation efforts produced quick wins, the team culture changes around WIP limits and requirement clarity delivered the most substantial long-term benefits.
This example demonstrates that effective cycle time optimization requires both technical solutions and process refinements. The fintech company continues to monitor its cycle time data, making incremental improvements that maintain their enhanced velocity without sacrificing quality or team wellbeing.
Achieving engineering operations excellence has become a strategic imperative for software development teams aiming to deliver high-quality products with unprecedented speed and efficiency. At the heart of this transformation lies the optimization of cycle time—a critical metric that measures how quickly teams can move an issue from initial request to final delivery. How does consistent cycle time tracking impact development workflows? By analyzing average cycle time across projects, teams gain invaluable insights into their development processes, enabling them to:
To reach operational excellence, engineering teams must embrace a culture of continuous improvement and process optimization. This journey begins with measuring cycle time using a clear cycle time formula, establishing robust baseline metrics, and monitoring cycle time trends over extended periods. How do teams pinpoint the hidden delays in their workflows? By systematically analyzing their processes, teams can identify:
Targeted process improvements—such as automating repetitive tasks, refining the review process, and optimizing resource allocation—help reduce cycle time and lead to more efficient cycle times across all development initiatives.
Optimizing cycle time transcends mere speed improvements; it's fundamentally about delivering consistent value, improving code quality, and enhancing customer satisfaction. How do efficient cycle times transform customer relationships? Efficient cycle times allow teams to respond rapidly to bug fixes and feature requests, ensuring that customer needs are met promptly and effectively. By leveraging cycle time tracking tools and engineering analytics, teams can:
Engineering leaders play a pivotal role in this transformational journey. How do leaders foster operational excellence? By prioritizing accurate measurement, fostering a data-driven culture, and championing the use of key metrics like cycle time, lead time, and development velocity, leaders can guide their teams toward operational excellence. They should also focus on:
A crucial aspect of achieving engineering operations excellence is the optimization of the review process. How do pull requests and code reviews impact development velocity? Pull requests and code reviews are often significant sources of delay in the development workflow. By streamlining these processes—through intelligent automation, clear guidelines, and efficient collaboration—teams can:
Data collection and analysis form the foundation of this strategic approach. How do teams ensure sustainable improvements? By systematically gathering data on cycle time, lead time, and other key metrics, teams can identify trends, measure the impact of process changes, and implement targeted process improvements. This commitment to accurate measurement and continuous monitoring ensures that:
In summary, engineering operations excellence is achieved by optimizing cycle time, streamlining processes, and fostering a culture of continuous improvement. By tracking cycle time, measuring lead time, and refining the review process, software development teams can deliver high-quality products faster, improve customer satisfaction, and maintain a competitive edge. Through the strategic use of engineering analytics, baseline metrics, and tracking tools, teams can make informed decisions, allocate resources effectively, and drive ongoing process optimization—ensuring long-term success in today's fast-paced software development landscape where agility and efficiency determine market leadership.
Issue cycle time directly impacts development velocity and team productivity. By tracking and optimizing this metric, teams can deliver value faster.
Typo's real-time issue tracking combined with AI-powered insights automates improvement detection and suggests targeted optimizations. Our platform allows teams to maintain optimal cycle times while reducing manual overhead.
Ready to accelerate your development workflow? Book a demo today!

SDLC methodologies provide structured processes for building software, differing in flexibility, delivery pace, and approach to change. This guide is intended for software developers, project managers, and business stakeholders seeking to understand and select the most suitable SDLC methodology for their projects. Choosing the right SDLC methodology is crucial for project success, efficiency, and meeting business goals. SDLC methodologies are structured processes that guide software development and maintenance, helping organizations deliver high-quality software solutions that align with user requirements and business objectives.
The Software Development Life Cycle (SDLC) methodologies provide a structured framework for guiding software development and maintenance. The SDLC process is a cornerstone of project management, helping companies track and control software projects more effectively.
Development teams need to select the right approach for their project based on its needs and requirements. We have curated the top 8 SDLC methodologies that you can consider. Choose the one that best aligns with your project. Over time, SDLC methodologies have evolved significantly since the early days of the Waterfall method, leading to more flexible and adaptive approaches. Let’s get started:
Software Development Lifecycle (SDLC) serves as the foundational architectural framework that underpins any sophisticated software development methodology. It provides a comprehensive, systematized approach enabling development teams to strategically orchestrate planning phases, design specifications, implementation protocols, testing procedures, and deployment strategies for software applications with optimal efficiency and precision. Through adherence to a structured development lifecycle methodology, organizations can effectively optimize resource allocation, establish clear deliverable expectations, and generate high-quality software solutions that align with user requirements and business objectives.
A meticulously architected SDLC empowers development teams to navigate the intricate complexities inherent in software development processes, ensuring that each critical phase—from initial conceptualization through ongoing maintenance and support—undergoes rigorous management and oversight. This systematic approach not only mitigates the risk of costly development errors and technical debt but also streamlines the entire development workflow, facilitating enhanced progress tracking capabilities and adaptive responsiveness to evolving requirements. Ultimately, the software development lifecycle SDLC framework enables development teams to deliver robust, scalable, and secure software applications that meet stringent timeline requirements while maintaining budgetary constraints and operational efficiency. If you're looking for the right tools to streamline your SDLC, check out this guide.
With this foundational understanding, let's explore the most widely used SDLC methodologies in detail.
Before diving into each methodology, here’s a comparative overview of the top SDLC methodologies and their core characteristics:
SDLC methodologies are structured processes that guide software development and maintenance. Each methodology offers a unique approach to flexibility, delivery pace, and handling change, making it essential to choose the one that best fits your project’s needs.
The waterfall methodology is the oldest surviving SDLC methodology that follows a linear, sequential approach. In this approach, the development team completes each phase before moving on to the next, and each phase has its own project plan detailing the tasks and deliverables required. The five phases include Requirements, Design, Implementation, Verification (which includes the testing phase), and Maintenance.
The waterfall methodology requires that once a phase is completed, the team cannot return to the previous phase, making it difficult to address issues that arise later. The testing phase in the waterfall methodology occurs only after the implementation (coding) phase is complete, which can delay the identification of defects. The Waterfall model is best suited for projects with clear, well-defined requirements and a low probability of change. However, it has been criticized for its rigidity and lack of flexibility, leading to lengthy development cycles and making it difficult and expensive to implement changes after the fact. The Waterfall model was first introduced by Winston W. Royce in the 1970s.

However, in today’s world, the waterfall methodology is not ideal for large and complex projects, as it does not allow teams to revisit the previous phase. The Waterfall methodology is often considered outdated, as many organizations have moved towards more flexible methodologies like Agile. That said, the Waterfall Model serves as the foundation for all subsequent SDLC models, which were designed to address its limitations.
This software development approach is known as an iterative methodology, which embraces repetition and incremental progress. In the Iterative model, each iteration cycles through all the phases of the SDLC, allowing for continuous refinement and improvement. The development team uses iterative development, enabling repeated cycles of planning, testing, and refinement based on feedback and changing requirements. This approach builds software piece by piece while identifying additional needs as they go along. Each new phase produces a more refined version of the software.

In this model, only the major requirements are defined from the beginning. One well-known iterative model is the Rational Unified Process (RUP), developed by IBM, which aims to enhance team productivity across various project types. Agile, one of the most popular SDLC methodologies, is also based on iterative development, flexibility, and organization-wide collaboration.
This methodology is similar to the iterative model but differs in its focus. In the incremental model, the product is developed and delivered in small, functional increments through multiple cycles. It prioritizes critical features first and then adapts additional functionalities as requirements evolve throughout the project.

Simply put, the product is not held back until it is fully completed. Instead, it is released in stages, with each increment providing a usable version. This allows for easy incorporation of changes in later increments. However, this approach requires thorough planning and design and may require more resources and effort.
The Agile SDLC methodology is a flexible and iterative approach to software development. Developed in 2001, it combines iterative and incremental models aiming to increase collaboration, gather feedback, and enable rapid product delivery. It is based on the theory “Fail Fast and Early,” which emphasizes quick testing and learning from failures early to minimize risks, save resources, and drive rapid improvement.
Agile teams are collaborative, cross-functional groups that organize their work into sprints or visual workflows, such as Kanban boards, to enhance responsiveness, transparency, and continuous improvement. Agile structures projects into sprints—time-boxed iterations that typically last between 1–4 weeks. This approach emphasizes continuous collaboration between team members and stakeholders, with regular cycles of feedback and iteration. Agile benefits from high customer orientation and strong team collaboration, making it most suitable for ongoing projects that need to adapt to changing market requirements and demands. However, Agile relies on minimal documentation, which can make it less suitable for complex projects. Agile emphasizes collaboration, continuous delivery, and customer feedback.

The software product is divided into small incremental parts that pass through some or all the SDLC phases. Each new version is tested and feedback is gathered from stakeholders throughout their process. This allows for catching issues early before they grow into major ones. A few of its sub-models include Extreme Programming (XP), Rapid Application Development (RAD), and Kanban. Scrum is a popular agile framework—a structured approach within Agile that organizes teams and workflows to enhance project flexibility, collaboration, and efficiency.
A flexible SDLC approach in which the project cycles through four phases: Planning, Risk Analysis, Engineering, and Evaluation, repeatedly in a figurative spiral until completion. This methodology is widely used by leading software companies, as it emphasizes risk analysis, ensuring that each iteration focuses on identifying and mitigating potential risks.

This model also prioritizes customer feedback and incorporates prototypes throughout the development process. It is particularly suitable for large and complex projects with high-risk factors and a need for early user input. However, for smaller projects with minimal risks, this model may not be ideal due to its high cost.
Derived from Lean Manufacturing principles, the Lean Model focuses on maximizing user value by minimizing waste and optimizing processes. It aligns well with the Agile methodology by eliminating multitasking and encouraging teams to prioritize essential tasks in the present moment.

The Lean Model is often associated with the concept of a Minimum Viable Product (MVP), a basic version of the product launched to gather user feedback, understand preferences, and iterate for improvements. Key tools and techniques supporting the Lean model include value stream mapping, Kanban boards, the 5S method, and Kaizen events.
An extension to the waterfall model, the V-model is also known as the verification and validation model. It is categorized by its V-shaped structure that emphasizes a systematic and disciplined approach to software development. In this approach, the verification phase ensures that the product is being built correctly and the validation phase focuses on the correct product is being built. These two phases are linked together by implementation (or coding phase).

This model is best suited for projects with clear and stable requirements and is particularly useful in industries where quality and reliability are critical. However, its inflexibility makes it less suitable for projects with evolving or uncertain requirements.
The DevOps model is a hybrid of Agile and Lean methodologies. It brings together development and operations teams to enhance collaboration and integration throughout the systems development process. DevOps aims to automate processes, integrate CI/CD, and accelerate the delivery of high-quality software.It focuses on small but frequent updates, allowing continuous feedback and process improvements. DevOps promotes a culture of shared responsibility, where all parties work together throughout the entire software development lifecycle. The DevOps methodology aims to shorten the systems development life cycle and provide continuous delivery with high software quality by integrating software development and IT operations. The DevOps movement began around 2008, driven by the need for rapid changes and cross-functional collaboration. This enables teams to learn from failures, iterate on processes, and encourage experimentation and innovation to enhance efficiency and quality.

DevOps is widely adopted in modern software development to support rapid innovation and scalability. However, it may introduce more security risks as it prioritizes speed over security.
To optimize the effectiveness of the software development lifecycle, it becomes imperative to leverage proven methodologies and strategic approaches throughout the comprehensive development trajectory. The following framework comprises essential strategies that facilitate teams in delivering superior software applications that meet organizational objectives and stakeholder expectations:
The foundation of successful software development initiatives comprises establishing a thorough understanding of project scope, objectives, and anticipated deliverables. Well-documented project requirements serve as the cornerstone that ensures all stakeholders involved in the software development process maintain alignment and coordinate efforts toward achieving unified objectives. This comprehensive approach facilitates seamless communication among cross-functional teams and minimizes potential misunderstandings that could compromise project outcomes.
The selection of an appropriate SDLC model constitutes a critical decision that should align with the project's complexity, scale, and specific requirements. Whether organizations opt for the Agile methodology to enhance flexibility and iterative development or choose the Waterfall model for implementing a more traditional and sequential software development approach, the strategic selection will significantly streamline the development lifecycle and optimize resource utilization across project phases.
Proactive identification of potential risks during the initial project phases represents a fundamental practice for maintaining project stability. Through systematic risk analysis implementation, development teams can formulate robust mitigation strategies that address potential issues before they adversely impact the software development lifecycle trajectory, thereby ensuring project continuity and maintaining predetermined timelines and quality standards.
The integration of quality assurance protocols and comprehensive testing procedures into each stage of the SDLC constitutes an essential practice for maintaining software excellence. Regular implementation of unit testing, integration testing, and system testing methodologies facilitates early defect detection and resolution, ensuring that the final software application meets the highest industry standards and organizational quality benchmarks.
Encouraging transparent communication channels and fostering collaborative teamwork among developers, business analysts, project managers, and stakeholders represents a cornerstone of successful software development initiatives. Effective collaboration frameworks ensure that stakeholder feedback is incorporated expeditiously and that the entire development process operates with optimal efficiency, facilitating knowledge transfer and reducing potential bottlenecks.
The automation of build, test, and deployment pipelines through continuous integration and continuous delivery (CI/CD) methodologies significantly enhances operational efficiency and reduces manual intervention requirements. This strategic approach minimizes human errors, accelerates release cycles, and facilitates rapid delivery of software updates to end-users, thereby improving overall system responsiveness and user satisfaction.
Systematic tracking of project progress against established project plans while maintaining readiness for adaptive modifications represents a critical success factor. Regular analysis of performance metrics and user feedback enables development teams to make informed adjustments and strategic decisions, ensuring that the software development lifecycle maintains optimal efficiency and effectiveness throughout the project duration.
Through the implementation of these comprehensive best practices, software development teams can systematically minimize operational risks, enhance quality assurance protocols, and deliver software applications that truly align with customer expectations and organizational objectives while maintaining competitive advantages in the marketplace.
Intelligent engineering management platform - It is used for gaining visibility, removing blockers, and maximizing developer effectiveness throughout the SDLC process. By providing visibility into the entire SDLC process, Typo enables transparency, efficiency, and better decision-making for software organizations. Through SDLC metrics, you can ensure alignment with business goals and prevent developer burnout. This tool can be integrated with the tech stack to deliver real-time insights. Git, Slack, Calendars, and CI/CD to name a few.
Typo Key Features:

Apart from the Software Development Life Cycle (SDLC) methodologies mentioned above, there are alternative methodologies and other software development models you can take note of. Each methodology or model follows a different approach to creating high-quality software, depending on factors such as project goals, complexity, team dynamics, and flexibility. Traditional models like Waterfall are often considered outdated, as many organizations have moved towards more flexible methodologies such as Agile, which have replaced or improved upon older practices.
Be sure to conduct your own research to determine the optimal approach for producing high-quality software that efficiently meets user needs.
The Software Development Life Cycle (SDLC) is a structured process that guides the development and maintenance of software applications.
The main phases of SDLC include:
The purpose of SDLC is to provide a systematic approach to software development by setting clear software development goals at the beginning of the process. This ensures that the final product meets user requirements, stays within budget, and is delivered on time. The SDLC also helps the project team manage risks, improve collaboration and communication, and maintain software quality throughout its lifecycle.
Yes, SDLC can be applied to various software projects, including web applications, mobile apps, enterprise software, and embedded systems. However, the choice of SDLC methodology depends on factors like project complexity, team size, budget, and flexibility needs.

Nowadays, software development teams face immense pressure to deliver high-quality products rapidly. To navigate this complexity, organizations must embrace data-driven decision-making. This is where software development metrics become crucial. By carefully selecting and tracking the right software KPIs, teams can gain valuable insights into their performance, identify areas for improvement, and ultimately achieve their goals.
Software metrics provide a wealth of information that can be used to:
Several software development metrics are considered critical for measuring team performance and driving success. These include:
To effectively leverage software development metrics, teams should:
Software metrics and measures in software architecture play a crucial role in evaluating the quality and maintainability of software systems. Key metrics include:
A comprehensive quality metrics in software engineering template should include:
Software development metrics examples can include:
By carefully selecting and tracking the right software engineering KPIs, teams can gain valuable insights into their performance, identify areas for improvement, and ultimately deliver higher-quality software more efficiently.
Platform engineering teams play a crucial role in enabling software development teams to deliver high-quality products faster. By providing self-service infrastructure, automating processes, and streamlining workflows, platform engineering teams empower developers to focus on building innovative solutions.
To effectively fulfill this mission, platform engineering teams must also leverage software development KPIs and software development lifecycle insights. Here are some key ways they do it:
By carefully analyzing different KPIs and SDLC insights, platform engineering teams can continuously improve their services, enhance developer productivity, and ultimately contribute to the overall success of the organization.
These tech giants heavily rely on tracking software development KPIs to drive continuous improvement and maintain their competitive edge. Here are some real-world examples:
By leveraging data-driven insights from these KPIs, these companies can continuously optimize their development processes, boost team productivity, improve product quality, and deliver exceptional user experiences.
By embracing best-practice KPI settings for software development and leveraging SEI tools you can unlock the full potential of the software engineering metrics for business success.
Thinking about what your engineering health metrics look like?
Get Started!

An engineering team at a tech company was asked to speed up feature releases. They optimized for deployment velocity. Pushed more weekly updates. But soon, bugs increased and stability suffered. The company started getting more complaints.
The team had hit the target but missed the point—quality had taken a backseat to speed.
In engineering teams, metrics guide performance. But if not chosen carefully, they can create inefficiencies.
Goodhart’s Law reminds us that engineering metrics should inform decisions, not dictate them. The idea behind Goodhart’s Law was first introduced by British economist Charles Goodhart.
And leaders must balance measurement with context to drive meaningful progress.
In this post, we’ll explore the idea behind Goodhart’s Law, its impact on engineering teams, and how to use metrics effectively without falling into the trap of metric manipulation.
Let’s dive right in!
Goodhart’s Law states: “When a metric becomes a target, it ceases to be a good metric.” This concept, named after economist Charles Goodhart, highlights how when a measure becomes a target, it often loses its value as an observed statistical regularity and can distort behavior. Campbell's law is a related concept, emphasizing similar pitfalls in measurement and evaluation.
In engineering, prioritizing numbers over impact can cause issues like the following examples, illustrating the concept in action:
These are all examples of Goodhart's Law in action, where the focus on a single metric leads to unintended and sometimes negative impacts.
A classic example of this is the cobra effect, which occurred under the British government in colonial India. The government offered bounties for every dead cobra to reduce the population of venomous cobras. However, cobra breeders began to breed cobras to claim the reward, and when the bounty was withdrawn, they released the now-worthless cobras, making the problem worse. This story illustrates how public policy, when based on poorly designed metrics, can backfire due to perverse incentives.
Choosing the right words to describe measures is crucial for clarity and effective communication. It is also essential to select the right measures—what makes a good measure is its ability to reflect true goals without being easily gamed. Poorly designed metrics can have negative impacts, such as encouraging counterproductive behaviors or masking real issues.
Understanding this law helps teams set better engineering metrics that drive real improvements. It also highlights the importance of not missing the true goal—teams should focus on true goals rather than just proxies. Using multiple metrics and multiple measures can help avoid the pitfalls of over-optimizing a single number. Accurate measurements and the use of quantitative data are vital for informed decision-making.
Researchers David Manheim and Scott Garrabrant have identified four categories of Goodhart's Law: regressional, causal Goodhart, adversarial Goodhart, and Goodhart due to a third factor. These categories help explain how metrics can go wrong, whether through mistaken causality, adversarial manipulation, or unaccounted-for variables.
In business and company management, a successful strategy and solution often involve identifying essential measures that align with company, customers, and employee goals. The right metrics are identified to support continuous improvement, and company management must consider other factors and values to ensure long-term success. Metrics are often used for control purposes, but it is important to measure outcomes accurately and recognize the limitations of focusing on one metric, as this can lead to optimizing for fewer people and missing broader objectives.
Metrics help track progress, identify bottlenecks, and improve engineering efficiency. Companies often use metrics to track progress and drive decision-making, but there are risks involved if these metrics are not carefully designed.
But poorly defined KPIs can lead to unintended consequences and negative impacts:
When teams chase numbers, they optimize for the metric, not the goal. It is crucial to measure outcomes accurately to ensure that metrics reflect true progress.
Engineers might cut corners to meet deadlines, inflate ticket closures, or ship unnecessary features just to hit targets. Over time, this leads to burnout and declining quality, negatively affecting employee motivation and well-being.
Strict metric-driven cultures also stifle innovation. Developers focus on short-term wins instead of solving real problems. Values should guide the design of metrics to ensure ethical behavior and long-term success.
Teams avoid risky but impactful projects because they don’t align with predefined KPIs.
Leaders must recognize that engineering metrics are tools, not objectives. Company management plays a key role in setting effective metrics that drive improvement without causing harm. Used wisely, they guide teams toward improvement. Misused, they create a toxic environment where numbers matter more than real progress.
Metrics don’t just influence performance—they shape behavior and mindset. When poorly designed, the outcome will be the opposite of why they were brought in in the first place. The concept of metric manipulation highlights the importance of understanding the theoretical framework behind measurement and evaluation. Using the right words to describe performance is crucial, as precise language helps differentiate between various types of metrics and outcomes. When organizations focus solely on metrics, they may overlook the need to measure outcomes accurately, leading to incomplete or misleading assessments. This can result in negative impacts, such as encouraging counterproductive behaviors or undermining employee well-being. Additionally, fostering a culture where values guide behavior ensures that measurement frameworks support ethical and sustainable practices. Here are some pitfalls of metric manipulation in software engineering:
When engineers are judged solely by metrics, the pressure to perform increases. This pressure can negatively affect employee well-being, leading to stress and dissatisfaction. If a team is expected to resolve a certain number of tickets per week, developers may prioritize speed over thoughtful problem-solving.
They take on easier, low-impact tasks just to keep numbers high. Over time, this leads to burnout, disengagement, and declining morale. The negative impacts of excessive pressure include reduced creativity, increased turnover, and a decline in overall team performance. Instead of building creativity, rigid KPIs create a high-stress work environment.
A culture that emphasizes values, such as ethical behavior and long-term sustainability, can help prevent burnout and support a healthier workplace.
Metrics distort decision-making. Availability bias makes teams focus on what’s easiest to measure rather than what truly matters. This reflects the concept of metric manipulation, where the theoretical framework behind measurement is overlooked, leading to unintended consequences.
If deployment frequency is tracked but long-term stability isn’t, engineers overemphasize shipping quickly while ignoring maintenance. Using the right words to describe performance is crucial, as precise terminology helps differentiate between short-term outputs and long-term outcomes.
Similarly, the anchoring effect traps teams into chasing arbitrary targets. If management sets an unrealistic uptime goal, engineers may hide system failures or delay reporting issues to meet it. To avoid these pitfalls, organizations must measure outcomes accurately, ensuring that metrics reflect true performance and support better decision-making.
Metrics can take decision-making power away from engineers. When success is defined by rigid KPIs, developers lose the freedom to explore better solutions. This can negatively impact employee motivation, as individuals may feel their contributions are reduced to numbers rather than meaningful work.
A team judged on code commit frequency may feel pressured to push unnecessary updates instead of focusing on impactful changes. This stifles innovation and job satisfaction. Maintaining a culture where values guide decisions helps preserve autonomy and ensures that ethical and long-term considerations are prioritized over short-term metrics.
Avoiding metric manipulation starts with thoughtful leadership. Organizations need a balanced approach to measurement and a culture of transparency. Finding a solution to metric manipulation is essential for maintaining integrity and driving meaningful results.
Here’s how teams can set up a system that drives real progress without encouraging gaming:
Leaders play a crucial role in defining metrics that align with business goals. Instead of just assigning numbers, they must communicate the purpose behind them.
The right metrics are identified by analyzing which measures most directly influence desired business outcomes. Among these, some metrics are essential for driving success and avoiding common pitfalls.
For example, if an engineering team is measured on uptime, they should understand it’s not just about hitting a number—it’s about ensuring a seamless user experience.
When teams understand why a metric matters, they focus on improving outcomes rather than just meeting a target.
Numbers alone don’t tell the full story. Blending quantitative and qualitative metrics ensures a more holistic approach. Incorporating quantitative data alongside qualitative insights provides a comprehensive understanding of performance.
Instead of only tracking deployment speed, consider code quality, customer feedback, and post-release stability. Using multiple metrics and multiple measures to evaluate success helps avoid the pitfalls of relying on a single indicator.
For example, a team measured only on monthly issue cycle time may rush to close smaller tickets faster, creating an illusion of efficiency. Accurate measurements are essential to ensure that performance is assessed correctly.
But comparing quarterly performance trends instead of month-to-month fluctuations provides a more realistic picture.
If issue resolution speed drops one month but leads to fewer reopened tickets in the following quarter, it’s a sign that higher-quality fixes are being implemented.
This approach prevents engineers from cutting corners to meet short-term targets.
Silos breed metric manipulation. Cross-functional collaboration helps teams stay focused on impact rather than isolated KPIs. Embedding values into the organizational culture further promotes transparency, ensuring that ethical considerations guide both decision-making and measurement.
There are project management tools available that can facilitate transparency by ensuring progress is measured holistically across teams.
Encouraging team-based goals instead of individual metrics also prevents engineers from prioritizing personal numbers over collective success. This approach positively impacts employee motivation, as individuals feel their contributions are recognized within the broader context of team achievement.
When teams work together toward meaningful objectives, there’s less temptation to game the system.
Static metrics become stale over time. Teams either get too comfortable optimizing for them or find ways to manipulate them.
Rotating key performance indicators every few months keeps teams engaged and discourages short-term gaming. It is essential to periodically review and update key measures to ensure they remain relevant and effective.
For example, a team initially measured on deployment speed might later be evaluated on post-release defect rates. This shifts focus to sustainable quality rather than just frequency.
Leaders should evaluate long-term trends rather than short-term fluctuations. If error rates spike briefly after a new rollout, that doesn’t mean the team is failing—it might indicate growing pains from scaling.
Accurate measurements taken consistently over time are essential for identifying meaningful trends and avoiding misinterpretation of short-term changes. Looking at patterns over time provides a more accurate picture of progress and reduces the pressure to manipulate short-term results.
By designing a thoughtful metric system, building transparency, and emphasizing long-term improvement, teams can use metrics as a tool for growth rather than a rigid scoreboard.
A leading SaaS company, known for its data-driven approach to metrics, wanted to improve incident response efficiency, so they set a key metric: Mean Time to Resolution (MTTR). The goal was to drive faster fixes and reduce downtime by accurately measuring outcomes. However, this well-intentioned target led to unintended behavior.
To keep MTTR low, engineers started prioritizing quick fixes over thorough solutions. Instead of addressing the root causes of outages, they applied temporary patches that resolved incidents on paper but led to recurring failures. Additionally, some incidents were reclassified or delayed in reporting to avoid negatively impacting the metric.
Recognizing the issue, leadership revised their approach. They introduced a composite measurement that combined MTTR with recurrence rates and post-mortem depth—incentivizing sustainable fixes instead of quick, superficial resolutions. The right metrics were identified by analyzing which inputs and outputs best reflected true system health. They also encouraged engineers to document long-term improvements rather than just resolving incidents reactively.
This shift led to fewer repeat incidents, a stronger culture of learning from failures, and ultimately, a more reliable system that improved customer satisfaction, rather than just an artificially improved MTTR.
To prevent MTTR from being gamed, the company deployed a software intelligence platform that provided a comprehensive solution for deeper insights beyond just resolution speed. It introduced a set of complementary metrics to ensure long-term reliability rather than just fast fixes.
Key metrics that helped balance MTTR:
Using multiple metrics to evaluate performance helped avoid the pitfalls of relying on a single measurement and provided a more accurate picture of system health.
By monitoring these additional metrics, leadership ensured that engineering teams prioritized quality and stability alongside speed. Accurate measurements were essential for tracking progress and identifying areas for improvement. The software intelligence tool provided real-time insights, automated anomaly detection, and historical trend analysis, helping the company move from a reactive to a proactive incident management strategy.
Company management played a crucial role in implementing these tools and fostering a culture that values comprehensive measurement and continuous improvement.
As a result, they saw:
✅ 50% reduction in repeat incidents within six months.
✅ Improved root cause resolution, leading to fewer emergency fixes.
✅ Healthier team workflows, reducing stress from unrealistic MTTR targets.
No single metric should dictate engineering success. Software intelligence tools provide a holistic view of system health, helping teams focus on real improvements instead of gaming the numbers. By leveraging multi-metric insights, engineering leaders can build resilient, high-performing teams that balance speed with reliability.
Engineering metrics should guide teams, not control them. When used correctly, they help track progress and improve efficiency. But when misused, they encourage manipulation, stress, and short-term thinking.
Striking the right balance between numbers and why these numbers are being monitored ensures teams focus on real impact. Otherwise, employees are bound to find ways to game the system.
For tech managers and CTOs, the key lies in finding hidden insights beyond surface-level numbers. This is where Typo comes in. With AI-powered SDLC insights, Typo helps you monitor efficiency, detect bottlenecks, and optimize development workflows—all while ensuring you ship faster without compromising quality.
Take control of your engineering metrics.

86% of software engineering projects face challenges—delays, budget overruns, or failure.
31.1% of software projects are cancelled before completion due to poor planning and unaddressed delivery risks.
Missed deadlines lead to cost escalations. Misaligned goals create wasted effort. And a lack of risk mitigation results in technical debt and unstable software.
But it doesn’t have to be this way. By identifying risks early and taking proactive steps, you can keep your projects on track.
Here are some simple (and not so simple) steps we follow:
The earlier you identify potential challenges, the fewer issues you'll face later. Software engineering projects often derail because risks are not anticipated at the start.
By proactively assessing risks, you can make better trade-off decisions and avoid costly setbacks.
Start by conducting cross-functional brainstorming sessions with engineers, product managers, and stakeholders. Different perspectives help identify risks related to architecture, scalability, dependencies, and team constraints.
You can also use risk categorization to classify potential threats—technical risks, resource constraints, timeline uncertainties, or external dependencies. Reviewing historical data from past projects can also show patterns of common failures and help in better planning.
Tools like Typo help track potential risks throughout development to ensure continuous risk assessment. Mind mapping tools can help visualize dependencies and create a structured product roadmap, while SWOT analysis can help evaluate strengths, weaknesses, opportunities, and threats before execution.
Not all risks carry the same weight. Some could completely derail your project, while others might cause minor delays. Prioritizing risks based on likelihood and impact ensures that engineering teams focus on what matters.
You can use a risk matrix to plot potential risks—assessing their probability against their business impact.

Applying the Pareto Principle (80/20 Rule) can further optimize software engineering risk management. Focus on the 20% of risks that could cause 80% of the problems.
If you look at the graph below for top five engineering efficiency challenges:
Following the Pareto Principle, focusing on these critical risks would address the majority of potential problems.

For engineering teams, tools like Typo’s code review platform can help analyze codebase & pull requests to find risks. It auto-generates fixes before you merge to master, helping you push the priority deliverables on time. This reduces long-term technical debt and improves project stability.
Ensuring software quality while maintaining delivery speed is a challenge. Test-Driven Development (TDD) is a widely adopted practice that improves software reliability, but testing alone can consume up to 25% of overall project time.
If testing delays occur frequently, it may indicate inefficiencies in the development process.

Testing is essential to ensure the final product meets expectations.
To prevent testing from becoming a bottleneck, teams should automate workflows and leverage AI-driven tools. Platforms like Typo’s code review tool streamline testing by detecting issues early in development, reducing rework.
Beyond automation, code reviews play a crucial role in risk mitigation. Establishing peer-review processes helps catch defects, enforce coding standards, and improve code maintainability.
Similarly, using version control effectively—through branching strategies like Git Flow ensures that changes are managed systematically.
Tracking project progress against defined milestones is essential for mitigating delivery risks. Measurable engineering metrics help teams stay on track and proactively address delays before they become major setbacks.
Note that sometimes numbers without context can lead to metric manipulation, which must be avoided.
Break down development into achievable goals and track progress using monitoring tools. Platforms like Smartsheet help manage milestone tracking and reporting, ensuring that deadlines and dependencies are visible to all stakeholders.
For deeper insights, engineering teams can use advanced software development analytics. Typo, a software development analytics platform, allows teams to track DORA metrics, sprint analysis, team performance insights, incidents, goals, and investment allocation. These insights help identify inefficiencies, improve velocity, and ensure that resources align with business objectives.
By continuously monitoring progress and making data-driven adjustments, engineering teams can maintain predictable software delivery.
Misalignment between engineering teams and stakeholders can lead to unrealistic expectations and missed deadlines.
Start by tailoring communication to your audience. Technical teams need detailed sprint updates, while engineering board meetings require high-level summaries. Use weekly reports and sprint reviews to keep everyone informed without overwhelming them with unnecessary details.
You should also use collaborative tools to streamline discussions and documentation. Platforms like Slack enable real-time messaging, Notion helps organize documentation and meeting notes.
Ensure transparency, alignment, and quick resolution of blockers.
Agile methodologies help teams stay flexible and respond effectively to changing priorities.
The idea is to deliver work in small, manageable increments instead of large, rigid releases. This approach allows teams to incorporate feedback early and pivot when needed, reducing the risk of costly rework.
You should also build a feedback-driven culture by:
Using the right tools enhances Agile project management. Platforms like Jira and ClickUp help teams manage sprints, track progress, and adjust priorities based on real-time insights.
The best engineering teams continuously learn and refine their processes to prevent recurring issues and enhance efficiency.
After every major release, conduct post-mortems to evaluate what worked, what failed, and what can be improved. These discussions should be blame-free and focused on systemic improvements.
Categorize insights into:
Retaining knowledge prevents teams from repeating mistakes. Use platforms like Notion or Confluence to document:
Software development evolves rapidly, and teams must stay updated. Encourage your engineers to:
Providing dedicated learning time and access to resources ensures that engineers stay ahead of technological and process-related risks.
By embedding learning into everyday workflows, teams build resilience and improve engineering efficiency.
Mitigating delivery risk in software engineering is crucial to prevent project delays and budget overruns.
Identifying risks early, implementing robust development practices, and maintaining clear communication can significantly improve project outcomes. Agile methodologies and continuous learning further enhance adaptability and efficiency.
With AI-powered tools like Typo that offer Software Development Analytics and Code Reviews, your teams can automate risk detection, improve code quality, and track key engineering metrics.


Professional service organizations within software companies maintain a delivery success rate hovering in the 70% range.
This percentage looks good. However, it hides significant inefficiencies given the substantial resources invested in modern software delivery lifecycles.
Even after investing extensive capital, talent, and time into development cycles, missing targets on every third of projects should not be acceptable.
After all, there’s a direct correlation between delivery effectiveness and organizational profitability.
To achieve better outcomes, it is essential to understand and optimize the entire software delivery process, ensuring efficiency, transparency, and collaboration across teams. Automation and modern practices help streamline processes, reducing bottlenecks and improving efficiency throughout the workflow. Continuous Integration (CI) automates the integration of code changes into a shared repository multiple times a day, enabling teams to detect and address issues early. Continuous Improvement emphasizes learning from metrics, past experiences, and near misses to improve work throughput and software reliability. Using retrospectives or the improvement kata model, teams can identify areas for enhancement and implement changes that lead to better outcomes. Feedback loops are crucial in enabling teams to identify issues early, improve software quality, and facilitate rapid delivery by shortening the cycle of feedback and supporting iterative learning. Frequent feedback also helps validate assumptions and hypotheses made during the software development process, ensuring that the team remains aligned with project goals and user needs.
Working in smaller batches lowers the effort spent on code integration and reduces the risk of introducing significant issues. Containerization technologies like Docker encapsulate applications and their dependencies into isolated, portable containers, further simplifying integration and deployment processes. This approach ensures consistency across environments and reduces the likelihood of errors during deployment.
However, the complexity of modern software development - with its complex dependencies and quality demands - makes consistent on-time, on-budget delivery persistently challenging.
This reality makes it critical to master effective software delivery. Improving software delivery performance by monitoring key metrics such as deployment frequency, lead time, and failure rates can drive organizational success.
The Software Delivery Lifecycle (SDLC), also known as the software development lifecycle, is a structured sequence of stages that guides software from initial concept to deployment and maintenance.
Consider Netflix’s continuous evolution: when transitioning from DVD rentals to streaming, they iteratively developed, tested, and refined their platform. All this while maintaining uninterrupted service to millions of users. The SDLC guides the delivery of software applications from concept to deployment, ensuring a systematic approach to quality and efficiency.
A typical SDLC is a structured development process with six phases:
Each phase builds upon the previous, creating a continuous loop of improvement.
Modern approaches often adopt Agile methodologies, which enable rapid iterations and frequent releases. Feedback loops are integral to Agile and CI/CD practices, allowing teams to learn iteratively, identify issues early, and respond quickly to user needs. Frequent feedback ensures that software development remains user-centered, tailoring products to meet evolving needs and preferences. These approaches are based on key principles such as transparency and continuous improvement. Agile methodologies encourage breaking down larger projects into smaller, manageable tasks or user stories. Modern practices like continuous deployment further enable rapid and reliable delivery to production environments. Agile encourages cross-functional teams, and DevOps extends this collaboration beyond development to operations, security, and other specialized roles. This also allows organizations to respond quickly to market demands while maintaining high-quality standards.
Streamlined software delivery leverages foundational principles that transform teams' capabilities toward enhanced efficiency, reliability, and continuous value optimization. Transparency revolutionizes stakeholder engagement, reshaping how developers, business leaders, and project teams gain comprehensive visibility into objectives, progress trajectories, and emerging challenges. This dynamic communication approach eliminates misunderstandings and aligns diverse stakeholders toward unified strategic goals.
Predictability serves as a transformative cornerstone, enabling teams to optimize release schedules and consistently deliver software solutions within projected timelines. By implementing robust processes and establishing realistic performance benchmarks, organizations can eliminate unexpected disruptions and enhance stakeholder confidence while building sustainable customer relationships.
Quality optimization is strategically integrated throughout the entire software development lifecycle, ensuring that every phase—from initial planning to final deployment—prioritizes the delivery of superior software solutions. This encompasses comprehensive testing protocols, rigorous code review processes, and adherence to industry best practices, all of which systematically prevent defects and maintain optimal performance standards. Standardizing the code review process ensures consistent quality and reduces lead times, enabling teams to deliver reliable software more efficiently.
Continuous improvement drives ongoing optimization of delivery methodologies and workflows. By systematically analyzing outcomes, leveraging stakeholder feedback, and implementing strategic incremental enhancements, teams can revolutionize their operational processes and adapt to evolving market requirements. Embracing these transformative principles empowers organizations to optimize their software delivery capabilities, deliver exceptional products rapidly, and maintain competitive advantages in today's dynamic digital landscape.
Software delivery models function as comprehensive frameworks that orchestrate organizations through the intricate journey of software development and deployment processes. These models establish the sequential flow of activities, define critical roles, and embed industry-proven best practices essential for delivering exceptional software solutions efficiently and with unwavering reliability. By establishing a detailed roadmap that spans from initial conceptualization through deployment and ongoing maintenance operations, software delivery models enable development teams to synchronize their collaborative efforts, optimize delivery workflows, and ensure customer satisfaction remains the paramount objective throughout the entire development lifecycle.
Selecting the optimal software delivery model proves crucial for maximizing software delivery efficiency and effectiveness. Whether organizations embrace traditional methodologies like the Waterfall model or adopt cutting-edge approaches such as Agile frameworks, DevOps practices, or Continuous Delivery pipelines, each model delivers distinctive advantages for managing architectural complexity, accelerating time-to-market velocity, and maintaining rigorous quality benchmarks. For instance, Agile software delivery methodologies emphasize iterative development cycles and continuous feedback mechanisms, empowering development teams to adapt dynamically to evolving requirements while delivering functional software increments at a sustainable development pace that prevents team burnout and technical debt accumulation.
Robust software development and delivery operations depend heavily on industry best practices seamlessly integrated within these delivery models, including continuous integration workflows, automated testing suites, comprehensive code review processes, and infrastructure as code implementations. These strategic practices not only enhance delivery frequency and deployment velocity but also significantly minimize the risk of production defects, security vulnerabilities, and technical debt accumulation that can compromise long-term system maintainability. By thoroughly understanding and strategically implementing the most appropriate software delivery model for their organizational context, teams can optimize their entire delivery pipeline architecture, strengthen collaboration between development and operations teams, and consistently deliver software products that meet or surpass customer expectations while maintaining competitive market positioning.
In summary, developing a comprehensive understanding of software delivery models empowers development teams to make data-driven decisions, streamline operational processes, and achieve consistent, high-quality software delivery outcomes—ultimately driving both organizational performance metrics and customer satisfaction levels while positioning the organization for sustained competitive advantage in rapidly evolving technology markets.
Even the best of software delivery processes can have leakages in terms of engineering resource allocation and technical management. Understanding the key aspects that influence software delivery performance—such as speed, stability, and reliability—is crucial for success. Vague, incomplete, or frequently changing requirements waste everyone's time and resources, leading to precious time spent clarifying, reworking, or even building a feature that may miss the mark or get scrapped altogether.
Before implementing best practices, it is important to track the four key metrics defined by DORA metrics. These metrics provide a standardized way to measure and improve software delivery performance. DORA metrics provide a holistic view into the entire software development lifecycle (SDLC), offering insights into both throughput and stability. High-performing teams increase throughput while improving stability, as indicated by DORA metrics.
By applying these software delivery best practices, you can achieve effectiveness:
Effective project management requires systematic control over development workflows while maintaining strategic alignment with business objectives. Scope creep can negatively impact the whole team, leading to disengagement and overwhelming all members involved in the project.
Modern software delivery requires precise distribution of resources, timelines, and deliverables.
Here’s what you should implement:
Quality assurance integration throughout the SDLC significantly reduces defect discovery costs.
Early detection and prevention strategies prove more effective than late-stage fixes. This ensures that your time is used for maximum potential helping you achieve engineering efficiency.
Some ways to set up robust a QA process:
Efficient collaboration accelerates software delivery cycles while reducing communication overhead. Agile teams, composed of cross-functional members, facilitate collaboration and rapid delivery by leveraging their diverse skills and working closely together. When all roles involved in software delivery and operations work together, they can streamline the needs of individual specialists. Creating a high trust and low blame culture makes it easier for everyone involved in software delivery to find ways to improve the process, tools, and outcomes, fostering an environment of continuous learning and innovation.
There are tools and practices available that facilitate seamless information flow across teams. It’s important to encourage developers to participate actively in collaborative practices, fostering a culture of ownership and continuous improvement. Establishing feedback loops within teams is essential, as they help identify issues early and support continuous improvement by enabling iterative learning and rapid response to challenges.
Here’s how you can ensure the collaboration is effective in your engineering team:
Security integration throughout development prevents vulnerabilities and ensures compliance. Instead of fixing for breaches, it’s more effective to take preventive measures. Automating secure coding standard checks, static and dynamic analysis, vulnerability assessments, and security testing reduces the risk of breaches. Implementing effective multi-cloud strategies can help address security, compliance, and vendor lock-in challenges by providing flexibility and reducing risk across cloud environments.
To implement strong security measures:
Scalable architectures directly impact software delivery effectiveness by enabling seamless growth and consistent performance even when the load increases.
Strategic implementation of scalable processes removes bottlenecks and supports rapid deployment cycles.
Here’s how you can build scalability into your processes:
CI/CD automation streamlines the deployment pipeline, which is an automated, staged process that transforms source code into production-ready software. Automation tools play a crucial role in streamlining the CI/CD process by handling build automation, deployment automation, environment setup, and monitoring. These practices help streamline processes by reducing bottlenecks and improving efficiency in software delivery. Integration with version control systems ensures consistent code quality and deployment readiness. Continuous deployment enables rapid and reliable releases by automating frequent software delivery to production environments. Minimizing manual intervention in the deployment pipeline leads to more reliable releases, reducing human error and ensuring high-quality, stable software updates. This means there are fewer delays and more effective software delivery.
Effective software delivery requires precise measurement through carefully selected metrics. These metrics provide actionable insights for process optimization and delivery enhancement. Tracking these metrics is essential for improving software delivery performance and can help organizations accelerate time to market by identifying bottlenecks and enabling faster, more reliable releases. Collecting and analyzing metrics, logs, and analytics data helps track key performance indicators (KPIs) and identify areas for improvement, ensuring that teams can make data-driven decisions to enhance their workflows and outcomes.
Here are some metrics to keep an eye on:
These metrics provide quantitative insights into delivery pipeline efficiency and help identify areas for continuous improvement. Maintaining a sustainable speed in software delivery is crucial to avoid burnout and ensure ongoing productivity over the long term. Adopting a sustainable pace helps balance speed with quality, supporting long-term team health and consistent delivery outcomes.
Continuous improvement comprises the foundational methodology that drives optimal software delivery performance across modern development ecosystems. This systematic approach facilitates comprehensive assessment protocols that enable development teams to regularly evaluate their delivery pipeline architectures, aggregate stakeholder feedback mechanisms, and implement strategic modifications that optimize operational outcomes. By establishing a culture of iterative enhancement, organizations can systematically identify performance bottlenecks, eliminate workflow inefficiencies, and elevate the overall quality metrics of their software products through data-driven optimization techniques.
This cyclical methodology involves leveraging stakeholder input aggregation systems, analyzing delivery pipeline performance metrics through comprehensive monitoring tools, and experimenting with emerging technologies and best practices frameworks. Each improvement iteration brings development teams closer to achieving unprecedented efficiency levels, enabling them to deliver high-quality software solutions with enhanced consistency while maintaining rapid response capabilities to evolving customer requirements and market dynamics.
Continuous improvement also facilitates innovation acceleration, as development teams are encouraged to explore novel methodological approaches and extract valuable insights from both successful implementations and failure scenarios. By embedding continuous improvement protocols into the fundamental architecture of software delivery workflows, organizations ensure their delivery processes remain agile, highly effective, and capable of meeting the demanding requirements of dynamic market conditions and technological advancements.
In today's highly competitive technological landscape, accelerating time to market represents a fundamental strategic imperative for software delivery teams operating within complex, multi-faceted development environments. The capability to deliver innovative features and critical updates with unprecedented velocity can fundamentally distinguish market leaders from organizations that lag behind in the rapidly evolving digital ecosystem. Streamlining software delivery processes emerges as the cornerstone of this transformation—this comprehensive approach encompasses reducing lead times through systematic optimization, increasing deployment frequency via automated orchestration, and ensuring that software products reach end-users with enhanced speed and reliability through advanced delivery mechanisms.
Adopting agile methodologies enables development teams to operate within short, iterative cycles that facilitate the delivery of working software incrementally while gathering valuable feedback early in the development lifecycle. Automation serves as a vital catalyst in this transformation; by implementing sophisticated automated testing frameworks and deployment orchestration through continuous integration and continuous delivery pipelines, teams can systematically eliminate manual bottlenecks, reduce human error, and ensure reliable, repeatable releases that maintain consistency across diverse deployment environments. These AI-driven automation tools analyze deployment patterns, predict potential failures, and optimize resource allocation to enhance overall pipeline efficiency.
Leveraging cloud-based infrastructure architectures further accelerates deployment capabilities, enabling rapid horizontal and vertical scaling while providing flexible resource allocation that adapts to dynamic workload demands. By focusing on continuous improvement methodologies and sustainable speed optimization strategies, organizations can consistently deliver high-quality software products that meet stringent performance criteria, drive exceptional customer satisfaction through enhanced user experiences, and maintain a robust competitive position in the market through technological excellence and operational efficiency.
Adopting a DevOps methodology fundamentally transforms software delivery mechanisms and establishes unprecedented collaboration paradigms between development and operations teams. DevOps dismantles conventional organizational boundaries, cultivating a comprehensive shared accountability framework where all team members actively contribute to architectural design, iterative development, systematic testing, and production deployment of software solutions. This transformative approach leverages advanced automation technologies that orchestrate continuous integration and continuous delivery pipelines, substantially reducing manual intervention requirements while dramatically increasing deployment frequency and operational efficiency.
This collaborative methodology leverages sophisticated automation frameworks that streamline continuous integration and continuous delivery workflows, significantly minimizing manual intervention dependencies and accelerating deployment cycles. DevOps methodologies promote continuous learning paradigms, enabling development teams to rapidly adapt to emerging technological challenges and innovative solutions. Machine learning algorithms and AI-driven tools analyze deployment patterns, predict potential bottlenecks, and automatically optimize resource allocation across development lifecycles, ensuring seamless integration between traditionally siloed operational domains.
Through implementing comprehensive DevOps strategies, organizations achieve substantial improvements in software product quality and system reliability, accelerate delivery timelines, and demonstrate enhanced responsiveness to evolving customer requirements and market demands. The outcome generates a high-performance operational environment where development and operations teams collaborate synergistically to deliver superior-quality software solutions rapidly and consistently. This integrated approach transforms traditional software development paradigms, establishing scalable frameworks that support continuous innovation while maintaining operational excellence across all deployment phases.
To truly optimize software delivery workflows and achieve sustainable development velocity, organizations must implement comprehensive measurement frameworks that analyze critical performance indicators. DORA metrics comprise a robust analytical framework for evaluating software delivery excellence, facilitating data-driven insights across four fundamental performance dimensions: deployment frequency patterns, lead time optimization for code changes, change failure rate analysis, and service restoration timeframes. Establishing a unified process for monitoring DORA metrics can be challenging due to differing internal procedures across teams. This methodology has reshaped how development teams assess their delivery capabilities and enables organizations to dive into performance bottlenecks with unprecedented precision.
Deployment frequency serves as a crucial indicator that tracks the cadence of software releases reaching production environments, directly reflecting the team's capability to deliver customer value through consistent iteration cycles. Lead time measurement captures the temporal efficiency from initial code commit through production deployment, highlighting process optimization opportunities and identifying workflow impediments that impact delivery velocity. Change failure rate analysis quantifies the percentage of production deployments that result in system failures or service degradations, functioning as a comprehensive reliability metric that ensures quality gates are maintained throughout the delivery pipeline. Time to restore service encompasses the organization's incident response capabilities, measuring how rapidly development and operations teams can remediate production issues and minimize customer-facing disruptions through effective monitoring and recovery procedures.
By continuously monitoring these performance metrics and implementing automated data collection mechanisms, organizations can systematically identify delivery bottlenecks, prioritize process improvements based on empirical evidence, and accelerate their time-to-market capabilities while maintaining quality standards. Leveraging DORA metrics facilitates evidence-based decision-making processes, enabling development teams to achieve sustainable delivery velocity, enhance customer satisfaction through reliable service delivery, and deploy high-quality software products with confidence while optimizing resource allocation across the entire software development lifecycle.
The SDLC has multiple technical challenges at each phase. Some of them include:
Visibility and transparency throughout the process are crucial for tracking progress and addressing these challenges. With clear visibility, teams can identify bottlenecks early and address issues proactively.
Teams grapple with requirement volatility leading to scope creep. API dependencies introduce integration uncertainties, while microservices architecture decisions significantly impact system complexity. Resource estimation becomes particularly challenging when accounting for potential technical debt.
Design phase complications are around system scalability requirements conflicting with performance constraints. Teams must carefully balance cloud infrastructure selections against cost-performance ratios. Database sharding strategies introduce data consistency challenges, while service mesh implementations add layers of operational complexity.
Development phase issues lead to code versioning conflicts across distributed teams. A well-defined software development process can help mitigate some of these challenges by providing structure and best practices for collaboration, automation, and quality delivery. Software engineers frequently face memory leaks in complex object lifecycles and race conditions in concurrent operations. Then there are rapid sprint cycles that often result in technical debt accumulation, while build pipeline failures occur from dependency conflicts.
Testing becomes increasingly complex as teams deal with coverage gaps in async operations and integration failures across microservices. Performance bottlenecks emerge during load testing, while environmental inconsistencies lead to flaky tests. API versioning introduces additional regression testing complications.
Deployment challenges revolve around container orchestration failures and blue-green deployment synchronization. Delays or issues in deployment can hinder the timely delivery of software updates, making it harder to keep applications current and responsive to user needs. Teams must manage database migration errors, SSL certificate expirations, and zero-downtime deployment complexities.
In the maintenance phase, teams face log aggregation challenges across distributed systems, along with memory utilization spikes during peak loads. Cache invalidation issues and service discovery failures in containerized environments require constant attention, while patch management across multiple environments demands careful orchestration.
These challenges compound through modern CI/CD pipelines, with Infrastructure as Code introducing additional failure points.
Effective monitoring and observability become crucial success factors in managing them.
Use software engineering intelligence tools like Typo to get visibility on precise performance of the teams, sprint delivery which helps you in optimizing resource allocation and reducing tech debt better.
Effective software delivery depends on precise performance measurement. Without visibility into resource allocation and workflow efficiency, optimization remains impossible. Continuous learning is essential for ongoing optimization, enabling teams to adapt and improve based on feedback and new insights. Emphasizing continuous learning ensures teams stay updated with new tools and best practices in software delivery.
Typo addresses this fundamental need. The platform delivers insights across development lifecycles - from code commit patterns to deployment metrics. AI-powered code analysis automates optimization, reducing technical debt while accelerating delivery. Real-time dashboards expose developer productivity trends, helping you with proactive resource allocation.
Transform your software delivery pipeline with Typo’s advanced analytics and AI capabilities, enabling rapid deployment of new features.

This guide is designed for engineering leaders and project managers seeking to master IT resource allocation for project success. We cover key concepts, challenges, strategies, and tools to optimize resource use in software engineering projects.
In theory, everyone knows that IT resource allocation acts as the anchor for project success—be it engineering or any business function.
But still, engineering teams are often misconstrued as cost centres. It can be because of many reasons:
And these are only the tip of the iceberg.
But how do we transform these cost centres into revenue-generating powerhouses? The answer lies in strategic resource allocation frameworks.
In this blog, we look into the complexity of resource allocation for engineering leaders—covering visibility into team capacity, cost structures, and optimisation strategies.
Let's dive right in!
Resource allocation is the strategic distribution and management of resources across organizational initiatives, portfolios, and departments.
Resource allocation in project management refers to the strategic assignment of available resources—such as time, budget, tools, and personnel—to tasks and objectives to ensure efficient project execution.
Resource allocation involves identifying resource types, availability, and constraints, as well as understanding the demand for IT services.
With tight timelines and complex deliverables, resource allocation becomes critical to meeting engineering project goals without compromising quality.
However, engineering teams often face challenges like resource overallocation, which leads to burnout and underutilisation, resulting in inefficiency. A lack of necessary skills within teams can further stall progress, while insufficient resource forecasting hampers the ability to adapt to changing project demands.
Project managers and engineering leaders play a crucial role in dealing with these challenges. By analysing workloads, ensuring team members have the right skill sets, and using tools for forecasting, they create an optimised allocation framework. Resource allocation software can automate many processes, including resource scheduling and workload management, while project management software with resource allocation functionality streamlines the resource allocation process from start to finish. Centralizing resource visibility through resource management software helps prevent double-booking in IT resource allocation.
This helps improve project outcomes and aligns engineering functions with overarching business goals, ensuring sustained value delivery. Effective resource allocation also requires continuous monitoring of resource usage and performance to address emerging issues and adjust the plan when conditions change.
Resource allocation is more than just an operational necessity—it’s a critical factor in maximizing value delivery. Strategic alignment in resource allocation ensures that resources are assigned in line with overall business goals, improving efficiency and project success.
Resource allocation is important because it directly impacts cost containment, productivity, employee satisfaction, and overall business performance, making it a key strategic element for organizations.
In software engineering, where success is measured by metrics like throughput, cycle time, and defect density, allocating resources effectively can dramatically influence these key performance indicators (KPIs). Efficient resource allocation improves profitability by ensuring projects are staffed appropriately without overspending, and helps organizations stay within budget by preventing unnecessary spending on unneeded licenses, hardware, or overstaffing.
Misaligned resources increase variance in these metrics, leading to unpredictable outcomes and lower ROI. Balancing workloads through effective allocation maintains high employee morale, protects staff from overutilization, and contributes to higher employee satisfaction and retention. Additionally, resource allocation enhances customer satisfaction by improving the quality and timely delivery of products or services, and contributes to better team morale by considering employees' workload and career goals.
Let’s see how precise resource allocation shapes engineering success:
Effective resource allocation ensures that engineering efforts directly align with project objectives, which helps reduce misdirection. Developing a resource allocation plan before task execution is crucial, as it helps inform resource allocation throughout the project lifecycle by providing a clear strategy for assigning and managing resources. The allocation process typically starts with business leaders and managers defining the project scope, including task details, budget, timelines, milestones, and key deliverables. By mapping resources to deliverables, teams can focus on priorities that drive value, meeting business and customer expectations.
Time and again, we have seen poor resource planning leading to bottlenecks. Common resource allocation challenges include unclear capacity, overallocation, and shifting priorities, all of which can disrupt well-established workflows and delay progress. Thoughtful resource allocation and proactive planning are essential to address these challenges and maintain project momentum. Resource allocation is a complex undertaking that requires visibility into resource availability and skills. Looking ahead at resource availability helps you spot and mitigate any resource risks that could pose a risk to delivery before they become a problem. Over-allocated resources, on the other hand, lead to employee burnout and diminished efficiency. Strategic allocation eliminates these pitfalls by balancing workloads and maintaining operational flow.
With a well-structured resource allocation framework, engineering teams can maintain a high level of productivity without compromising on quality. Good resource allocation is a strategic process that involves assigning the right skills and personnel to the appropriate tasks and project stages, which enhances quality, efficiency, and alignment with project demands. Effective resource management ensures visibility into resource availability, skills, and capacity, helping leaders allocate tasks efficiently and maintain both productivity and quality. The process to assign resources should be based on matching specific skills with deliverables, reviewing availability, and utilizing project management tools to facilitate assignments throughout the project lifecycle. Additionally, effective resource allocation practices protect your people from overutilization and consequently, reduced productivity and mental acuity. It enables leaders to identify skill gaps and equip teams with the right resources, fostering consistent output.
Resource allocation provides engineering leaders with a clear overview of team capacities, progress, and costs. Consolidating and managing resource data is essential to provide visibility for leaders and establish a solid foundation for workforce management and skills inventory. Resource allocation decisions should foster collaboration and communication among teams and stakeholders, emphasizing transparency and accountability. Team leaders play a key role in sharing the resource allocation plan with stakeholders to ensure clarity and provide ongoing updates. This transparency enables data-driven decisions, proactive adjustments, and alignment with the company’s strategic vision.
Improper resource allocation can lead to cascading issues, such as missed deadlines, inflated budgets, and fragmented coordination across teams. Resource conflicts occur when more than one project requires the same resources at the same time, which can further complicate project delivery. These challenges not only hinder project success but also erode stakeholder trust. Effective resource allocation requires continuous monitoring and adjustment to address emerging issues. Additionally, a robust resource allocation system increases flexibility and agility in responding to changing project conditions. This makes resource allocation a non-negotiable pillar of effective engineering project management.
Resource allocation typically revolves around five primary types of resources. Effective IT resource allocation is a multistep process that requires understanding the scope of work, estimating the types and number of resources required, and assessing the availability of the appropriate resources. It is crucial to estimate necessary resources by analyzing the project scope and objectives, identifying the skills and expertise required, and determining the availability and allocation of resources needed to accomplish tasks within budget constraints.
Defining and allocating specific resources—including human, financial, and technological assets—is essential for effective project execution and service delivery. Identifying and planning for critical resources, such as those affected by external dependencies like third-party vendors or regulatory requirements, helps prevent project delays and ensures smooth progress. Anticipating internal resource capacity constraints is also important to ensure project success.
Managing project resources throughout the project lifecycle requires flexible and responsive allocation strategies to adapt to project changes, dependencies, and team workload considerations. Predicting future resource demands through analytics and assessing current resource availability are key to ensuring that the right resources are in place when needed. Irrespective of which industry you cater to and what’s the scope of your engineering projects, you must consider allocating these effectively.
Assigning tasks to team members with the appropriate skill sets is fundamental. Effectively utilizing human resources is essential to ensure project success and client satisfaction. For example, a senior developer with expertise in microservices architecture should lead API design, while junior engineers can handle less critical feature development under supervision. Resource managers play a crucial role in identifying, allocating, and reassigning resources within project management processes, often collaborating with project managers and using dedicated software tools to optimize resource utilization. Training team members to cover multiple roles boosts developer productivity and increases the overall flexibility of the IT department. Balanced workloads prevent burnout and ensure consistent output, measured through velocity metrics in tools like Typo.
Deadlines should align with task complexity and team capacity. Developing a detailed project schedule—including milestones, deadlines, and task dependencies—is essential for effective planning and resource management. Managing project timelines is crucial to ensure projects stay on schedule, especially when dealing with external dependencies and ongoing monitoring. Scheduling resources by considering skills, availability, and capacity helps avoid financial risks and project delays. Additionally, resource leveling and prioritization involves ranking projects based on their importance to broader goals. For example, completing a feature that involves integrating a third-party payment gateway might require two sprints, accounting for development, testing, and debugging. Agile sprint planning and tools like Typo that help you analyze sprints and bring predictability to delivery can help maintain project momentum.
Cost allocation requires understanding resource rates and expected utilization. Effectively managing and distributing financial resources is essential to optimize organizational efficiency. For example, deploying a cloud-based CI/CD pipeline incurs ongoing costs that should be evaluated against in-house alternatives. When allocating resources and selecting team members, it is important to consider the project budget to ensure staffing and resource decisions align with financial constraints. Tracking project burn rates with cost management tools helps avoid budget overruns. As a best practice, allocating a reserve of 5-10% of the total IT budget helps manage unexpected incidents without disrupting ongoing projects.
Teams must have access to essential tools, software, and infrastructure, such as cloud environments, development frameworks, and collaboration platforms like GitHub or Slack. Effectively allocating technological resources is crucial for delivering IT services and optimizing organizational efficiency. For example, setting up Kubernetes clusters early ensures scalable deployments, avoiding bottlenecks during production scaling.
Real-time dashboards in tools like Typo offer insights into resource utilization, team capacity, and progress. Monitoring resource capacity and adjusting allocations is crucial to prevent overloads and accommodate changes in team availability or project priorities. Resource allocation tools provide real-time monitoring, scenario analysis, and workflow flexibility, helping leaders compare and select the best software solutions for effective resource planning. Increasingly, organizations rely on AI-powered forecasting and real-time monitoring tools in IT resource allocation to match resources to tasks more effectively. These systems allow leaders to identify bottlenecks, reallocate resources dynamically, and ensure alignment with overall project goals, enabling proactive decision-making.
When you have a bird’s eye view of your team’s activities, you can generate insights about the blockers that your team consistently faces and the patterns in delays and burnouts by going beyond traditional burndown charts. That said, let’s look at some strategies to optimize the cost of your software engineering projects.
Resource management platforms have transformed into mission-critical infrastructure for engineering teams navigating today's complex project landscapes. These sophisticated systems revolutionize resource allocation processes, ensuring optimal assignment of human capital, financial assets, and technological resources to specific project tasks with unprecedented precision and timing accuracy.
Optimal resource allocation serves as the cornerstone that drives successful project execution across engineering organizations. Resource management platforms deliver engineering leaders comprehensive real-time visibility into resource availability metrics, capacity utilization patterns, and consumption analytics. This enhanced transparency empowers project managers to execute data-driven decisions, rapidly identify emerging bottlenecks, and dynamically redistribute resources as project parameters evolve. By harnessing these advanced capabilities, teams eliminate common operational pitfalls including resource overcommitment, allocation conflicts, and deadline slippage scenarios.
Contemporary resource management platforms integrate dynamic scheduling engines, intelligent workload balancing algorithms, and predictive forecasting capabilities that reshape project planning methodologies. These advanced functionalities enable project managers to anticipate future resource requirements, implement proactive plan adjustments, and maximize resource utilization efficiency across concurrent project portfolios. Automated alerting systems and comprehensive dashboards ensure teams maintain continuous project progress monitoring, guaranteeing resource assignments align with defined project scope and strategic business objectives.
Resource management platforms support diverse allocation strategies spanning scenario planning frameworks to agile resource redistribution methodologies. Through comprehensive analysis of historical performance data and current project specifications, these tools empower engineering teams to execute effective resource allocation, adapt to shifting organizational priorities, and maintain strategic alignment with long-term business goals.
Integrating resource management platforms into engineering workflows enhances operational efficiency while cultivating continuous improvement cultures throughout organizations. With robust capabilities to track key performance indicators and analyze resource utilization trends, engineering leaders can systematically refine their allocation methodologies over time, driving superior outcomes for both team performance and organizational success.
Ultimately, implementing robust resource management platforms represents a strategic investment for engineering teams committed to optimizing resource allocation efficiency, maximizing productivity metrics, and achieving consistent project success across their entire portfolio.
Engineering projects management comes with a diverse set of requirements for resource allocation. Developing and communicating an allocation plan is crucial to manage resources effectively throughout the project lifecycle. It is important to manage resources by continuously monitoring and adjusting allocations as project conditions change. Using effective resource allocation strategies—such as planning, assessment, goal setting, and proactive risk management—can optimize resource use and improve service delivery. Continuous monitoring of resource utilization rates and service performance metrics is essential for effective resource allocation. Optimized resource allocation leads to enhanced efficiency by aligning supply and demand for project staffing. The combinations of all the resources required to achieve engineering efficiency can sometimes shoot the cost up. Here are some strategies to avoid the same:
Resource leveling focuses on distributing workloads evenly across the project timeline to prevent overallocation and downtime.
If a database engineer is required for two overlapping tasks, adjusting timelines to sequentially allocate their time ensures sustained productivity without overburdening them.
This approach avoids the costs of hiring temporary resources or the delays caused by burnout.
Techniques like critical path analysis and capacity planning tools can help achieve this balance, ensuring that resources are neither underutilized nor overextended. The critical path method is especially useful in resource allocation planning, as it identifies the most critical sequence of tasks that must be completed on time to meet project deadlines, helping teams align resource allocation with crucial project activities.
Automating routine tasks and using project management tools are key strategies for cost optimization.
Tools like Jira and Typo streamline task assignment, track progress, and provide visibility into resource utilization. Resource allocation software offers additional advantages, such as real-time tracking, scenario planning, and automation, which improve efficiency and coordination in project management compared to legacy systems like spreadsheets. Resource allocation software can also analyze historical data and project requirements to accurately forecast resource needs.
Automation in areas like testing (e.g., Selenium for automated UI tests) or deployment (e.g., Jenkins for CI/CD pipelines) reduces manual intervention and accelerates delivery timelines.
These tools enhance productivity and also provide detailed cost tracking, enabling data-driven decisions to cut unnecessary expenditures.
Cost optimization requires continuous evaluation of resource allocation. Weekly or bi-weekly reviews using metrics like sprint velocity, resource utilization rates, and progress against deliverables can reveal inefficiencies.
Relying on the same resources across multiple projects or tasks can create conflicts and delays, making it essential to monitor and adjust assignments regularly.
For example, if a developer consistently completes tasks ahead of schedule, their capacity can be reallocated to critical-path activities. This iterative process ensures that resources are used optimally throughout the project lifecycle.
Collaboration across teams and departments fosters alignment and identifies cost-saving opportunities. For example, early input from DevOps, QA, and product management can ensure that resource estimates are realistic and reflect the project’s actual needs. Using collaborative tools helps surface hidden dependencies or redundant tasks, reducing waste and improving resource efficiency. It is also essential to identify and plan for critical resources, including external dependencies such as third-party vendors or regulatory requirements, to prevent project delays and ensure smooth progress.
Scope creep is a common culprit in cost overruns. CTOs and engineering managers must establish clear boundaries and a robust change management process to handle new requests. It is essential to have a resource allocation plan in place and to adjust this plan as needed to accommodate changes that arise during the project lifecycle.
Resource allocation practices can vary significantly between organizations, but many include core processes such as assessing resource availability and creating a resource allocation plan.
For example, additional features can be assessed for their impact on timelines and budgets using a prioritization matrix.
Efficient resource allocation is the backbone of successful software engineering projects. It drives productivity, optimises cost, and aligns the project with business goals.
With strategic planning, automation, and collaboration, engineering leaders can increase value delivery.
Take the next step in optimizing your software engineering projects—explore advanced engineering productivity features of Typoapp.io

Imagine you are on a solo road trip with a set destination. You constantly check your map and fuel gauge to check whether you are on a track. Now, replace the road trip with an agile project and the map with a burndown chart.
Just like a map guides your journey, a burndown chart provides a clear picture of how much work has been completed and what remains.
Burndown charts are visual representations of the team’s progress used for agile project management. They are useful for scrum teams and agile project managers to assess whether the project is on track. Displaying burndown charts helps keep all team members on the same page regarding project progress and task status.
Burndown charts are generally of three types:
The product burndown chart focuses on the big picture and visualizes the entire project. It determines how many product goals the development team has achieved so far and the remaining work.
Sprint burndown charts focus on the ongoing sprints. A sprint burndown chart is typically used to monitor progress within a single sprint, helping teams stay focused on short-term goals. It indicates progress towards completing the sprint backlog.
This chart focuses on how your team performs against the work in the epic over time. Epic burndown charts are especially useful for tracking progress across multiple sprints, providing a comprehensive view of long-term deliverables. It helps to track the advancement of major deliverables within a project.
When it comes to agile project management, a burndown chart is a fundamental tool, and understanding its key components is crucial. Let’s break down what makes up a burndown chart and why each part is essential.
The horizontal axis, or X-axis, signifies the timeline for project completion. For projects following the scrum methodology, this axis often shows the series of sprints. Alternatively, it might detail the remaining days, allowing teams to track timelines against project milestones.
The vertical axis, known as the Y-axis, measures the effort still needed to reach project completion. This is often quantified using story points, a method that helps estimate the work complexity and the labor involved in finishing user stories or tasks.
The actual work remaining line is the key line on the chart that shows the real-time amount of work left in the project after each sprint or day. This actual work remaining line, sometimes called the actual work line or work line, reflects the actual work remaining at each point in time. It is often depicted as a red line on burndown charts, and the actual work line fluctuates above and below the ideal line as project progress changes. Since every project encounters unexpected obstacles or shifts in scope, this line is usually irregular, contrasting with the straight trajectory of planned efforts.
The ideal work remaining line, also called the ideal effort line, serves as the baseline for planned progress in a burndown chart. The ideal work line depends on the accuracy of initial time or effort estimates—if these estimates are off, the line may need adjustment to better reflect realistic expectations. This line is drawn assuming linear progress, meaning it represents a steady, consistent reduction in remaining work over time. The linear progress shown by this line serves as a benchmark, helping teams compare their actual performance against the expected, ideal trajectory.
Story points are a tool often used to put numbers to the effort needed for completing tasks or larger work units like epics. Story point estimates help quantify the amount of work remaining and are used to track progress on the burndown chart. They are plotted on the Y-axis of the burndown chart, while the X-axis aligns with time, such as the number of ongoing sprints.
A clear sprint goal serves as the specific objective for each sprint and is represented on the burndown chart by a target line. Even though actual progress might not always align with the sprint goal, having it illustrated on the chart helps maintain team focus, motivation, and provides a clear target for assessing whether the team is on track to complete their work within the sprint.
Incorporating these components into your burndown chart not only provides a visual representation of project progress but also serves as a guide for continual team alignment and focus.
A burndown chart shows the amount of work remaining (on the vertical axis) against time (on the horizontal axis). Teams use a burndown chart to track work and monitor progress throughout a project. It includes an ideal work completion line and the actual work progress line. As tasks are completed, the actual line “burns down” toward zero. This allows teams to identify if they are on track to complete their goals within the set timeline and spot deviations early. Burndown charts provide insight into team performance, workflow, and potential issues.
The ideal effort line begins at the farthest point on the burndown chart, representing the total estimated effort at the start of a sprint, and slopes downward to zero by the end. It acts as a benchmark to gauge your team’s progress and ensure your plan stays on course.
This line reflects your team’s real-world progress by showing the remaining effort for tasks at the end of each day. Each day, a new point is added to the actual effort line to accurately represent the team's progress. This process helps visualize the team's progress over time. Comparing it to the ideal line helps determine if you are ahead, on track, or falling behind, which is crucial for timely adjustments.
Significant deviations between the actual and ideal lines can signal issues. These deviations are identified by comparing the actual work remaining to what was originally predicted at the start of the sprint. If the actual line is above the ideal, delays are occurring. Conversely, if below, tasks are being completed ahead of schedule. Early detection of these deviations allows for prompt problem-solving and maintaining project momentum.
Look for trends in the actual effort line. A flat or slow decline might indicate bottlenecks or underestimated tasks, while a steep drop suggests increased productivity. Identifying these patterns can help refine your workflows and enhance team performance. Recognizing these trends also enables teams to find opportunities to improve team productivity.
Some burndown charts include a projection cone, predicting potential completion dates based on current performance. The projection cone can also help assess the team's likelihood of completing all work within the sprint duration. This cone, ranging from best-case to worst-case scenarios, helps assess project uncertainty and informs decisions on resource allocation and risk management.
By mastering these elements, you can effectively interpret burndown charts, ensuring your project management efforts lead to successful outcomes.
Burndown charts are invaluable tools for monitoring progress in project management. Development teams rely on burndown charts to monitor progress and ensure transparency throughout the project lifecycle. They provide a clear visualization of work completed versus the work remaining. By analyzing the chart, teams can gain insights into how the team works and identify areas for improvement.
By adopting these methods, teams can efficiently track their progress, ensuring that they meet their objectives within the desired timeframe. Analyzing the slope of the burndown chart regularly helps in making proactive adjustments as needed.
A burndown chart is a visual tool used by agile teams to track progress. Burndown charts are particularly valuable for tracking progress in agile projects, where flexibility and adaptability are essential. Here is a breakdown of its key functions:
Burndown charts allow agile teams to visualize the remaining work against time which helps to spot issues early from the expected progress. They can identify bottlenecks or obstacles early which enables them to proactive problem-solving before the issue escalates.
The clear graphical representation of work completed versus work remaining makes it easy for teams to see how much they have accomplished and how much is left to do within a sprint. This visualization helps maintain focus and alignment among team members.
The chart enables the team to see their tangible progress which significantly boosts their morale. As they observe the line trending downward, indicating completed tasks, it fosters a sense of achievement and motivates them to continue performing well.
After each sprint, teams can analyze the burndown chart to evaluate their estimation accuracy regarding task completion times. This retrospective analysis helps refine future estimates and improves planning for upcoming sprints.
Additionally, teams can use an efficiency factor to adjust future estimates, allowing them to correct for variability and improve the accuracy of their burndown charts.
Estimating effort for a burndown chart involves determining the amount of work needed to complete a sprint within a specific timeframe. Here’s a step-by-step approach to getting this estimation right:
After the first iteration, teams can recalibrate their estimates based on actual performance, which helps improve the accuracy of future sprint planning.
Start by identifying the total amount of work you expect to accomplish in the sprint. This requires knowing your team's productivity levels and the sprint duration. For instance, if your sprint lasts 5 days and your team can handle 80 hours in total, your baseline is 16 hours per day.
Next, divide the work into manageable chunks. List tasks or activities with their respective estimated hours. This helps in visualizing the workload and setting realistic daily goals.
With your total hours known, distribute these hours across the sprint days. Begin by plotting your starting effort on a graph, like 80 hours on the first day, and then reduce it daily as work progresses.
As the sprint moves forward, track the actual hours spent versus the estimated ones. This allows you to adjust and manage any deviations promptly.
By following these steps, you ensure that your burndown chart accurately reflects your team's workflow and helps in making informed decisions throughout the sprint.
A burndown chart is a vital tool in project management, serving as a visual representation of work remaining versus time. Although it might not capture every aspect of a project’s trajectory, it plays a key role in preventing scope creep.
Burndown charts are especially important for managing scope in a Scrum project, where they help track progress across sprints and epics by visually displaying estimated effort and work completed.
Firstly, a burndown chart provides a clear overview of how much work has been completed and what remains, ensuring that project teams stay focused on the goal. By continuously tracking progress, teams can quickly identify any deviation from the planned trajectory, which is often an early signal of scope creep.
However, a burndown chart doesn’t operate in isolation. It is most effective when used alongside other project management tools:
By consistently monitoring the relationship between time and completed work, project managers can maintain control and make informed decisions quickly. This proactive approach helps teams stay aligned with the project’s original vision, thus minimizing the risk of scope creep.
Both burndown and burnup charts are essential tools for managing projects, especially in agile environments. They provide visual insights into project progress, but they do so in different ways, each offering unique advantages.
A burndown chart focuses on recording how much work remains over time. It’s a straightforward way to monitor project progress by showing the decline of remaining tasks. Burndown charts are particularly effective for tracking progress during short iterations, such as sprints in Agile methodologies. The chart typically features:
This type of chart is particularly useful for spotting bottlenecks, as any deviation from the ideal line can indicate a pace that’s too slow to meet the deadline.
In contrast, a burnup chart highlights the work that has been completed, alongside the total work scope. Burnup charts are designed to show the amount of complete work over time, providing a cumulative view of progress. Its approach includes:
The key advantage of a burnup chart is its ability to display scope changes clearly. This is ideal when accommodating new requirements or adjusting deliverables, as it shows both progress and scope alterations without losing clarity.
While both charts are vital for tracking project dynamics, their perspectives differ. Burndown charts excel at displaying how rapidly teams are clearing tasks, while burnup charts provide a broader view by also accounting for changes in project scope. Using them together offers a comprehensive picture of both time management and scope management within a project.

Open a new sheet in Excel and create a new table that includes 3 columns.
The first column should include the dates of each sprint, the second column have the ideal burndown i.e. ideal rate at which work will be completed and the last column should have the actual burndown i.e. updating them as story points get completed.
Now, fill in the data accordingly. This includes the dates of your sprints and numbers in the Ideal Burndown column indicating the desired number of tasks remaining after each day throughout the let's say, 10-day sprint.
As you complete tasks each day, update the spreadsheet to document the number of tasks you can finish under the ‘Actual Burndown' column.

Now, it's time to convert the data into a graph. To create a chart, follow these steps: Select the three columns > Click ‘Insert' on the menu bar > Select the ‘Line chart' icon, and generate a line graph to visualize the different data points you have in your chart.


Compiling the final dataset for a burndown chart is an essential step in monitoring project progress. This process involves a few key actions that help translate raw data into a clear visual representation of your work schedule.
By compiling your own burndown chart, you can tailor the visualization to your team's unique workflow and project needs.
Start by gathering your initial effort estimates. These estimates outline the anticipated time or resources required for each task. Then, access your actual work logs, which you should have been maintaining consistently. By comparing these figures, you'll be able to assess where your project stands in relation to your original forecasts.
Ensure that your logged work data is kept in a centralized and accessible location. This strategy fosters team collaboration and transparency, allowing team members to view and update logs as necessary. It also makes it easier to pull together data when you're ready to update your burndown chart.
Once your data is compiled, the next step is to plot it on your burndown chart. This graph will visually represent your team’s progress, comparing estimated efforts against actual performance over time. Using project management software can simplify this step significantly, as many tools offer features to automate chart updates, streamlining both creation and maintenance efforts.
By following these steps, you’ll be equipped to create an accurate and insightful burndown chart, providing a clear snapshot of project progress and helping to ensure timelines are met efficiently. Burndown charts can also be used to monitor progress toward a specific release, helping teams align their efforts with key delivery milestones.
A Burndown chart mainly tracks the amount of work remaining, measured in story points or hours. This one-dimensional view does not offer insights into the complexity or nature of the tasks, hence, oversimplifying project progress.
Burndown charts fail to account for quality issues or the accommodation of technical debt. Agile teams might complete tasks on time but compromise on quality. This further leads to long-term challenges that remain invisible in the chart.
The burndown chart does not capture team dynamics or collaboration patterns. It fails to show how team members are working together, which is vital for understanding productivity and identifying areas for improvement.
The problems might go unnoticed related to story estimation and sprint planning. When a team consistently underestimates tasks, the chart may still show a downward trend. This masks deeper issues that need to be addressed.
Another disadvantage of burndown charts is that they do not reflect changes in scope or interruptions that occur during a sprint. If new tasks are added or priorities shift, the chart may give a misleading impression of progress.
The chart does not provide insights into how work is distributed among team members or highlight bottlenecks in the workflow. This lack of detail can hinder efforts to optimize team performance and resource allocation.
Burndown charts are great tools for tracking progress in a sprint. However, they don't provide a full picture of sprint performance as they lack the following dimensions:
For additional insights on measuring and improving Scrum team performance, consider leveraging DORA DevOps Metrics.
Typo’s sprint analysis feature allows engineering leaders to track and analyze their team’s progress throughout a sprint. It uses data from Git and the issue management tool to provide insights into getting insights on how much work has been completed, how much work is still in progress, and how much time is left in the sprint hence, identifying any potential problems early on and taking corrective action.
Scrum masters can use Typo's sprint analysis features to enhance transparency and communication within their teams, supporting agile project management practices.
Sprint analysis in Typo with burndown chart

Burndown charts offer a clear and concise visualization of progress over time. Many agile teams rely on burndown charts to monitor progress and drive continuous improvement. While they excel at tracking remaining work, they are not without limitations, especially when it comes to addressing quality, team dynamics, or changes in scope.
Integrating advanced metrics and tools like Typo, teams can achieve a more holistic view of their sprint performance and ensure continuous improvement.

Your engineering team is the biggest asset of your organization. They work tirelessly on software projects, despite the tight deadlines.
However, there could be times when bottlenecks arise unexpectedly, and you struggle to get a clear picture of how resources are being utilized. Businesses that utilize project management software experience fewer delays and reduced project failure rates, resulting in a 2.5 times higher success rate on average. Companies using project management practices report a 92% success rate in meeting project objectives.
This is where an Engineering Management Platform (EMP) comes into play. EMPs are used by agile teams, development teams, and software development teams to manage workflows and enhance collaboration. They are designed to handle complex projects and can manage the intricacies of a complex system.
An EMP acts as a central hub for engineering teams. It transforms chaos into clarity by offering actionable insights and aligning engineering efforts with broader business goals.
EMPs are particularly valuable for engineering firms and professional services firms due to their industry-specific needs.
In this blog, we’ll discuss the essentials of EMPs and how to choose the best one for your team.
Engineering Management Platforms (EMPs) are comprehensive tools and project management platform that enhance the visibility and efficiency of engineering teams. They serve as a bridge between engineering processes and project management, enabling teams to optimize workflows, manage project schedules and team capacity, track how they allocate their time and resources, perform task tracking, track performance metrics, assess progress on key deliverables, and make informed decisions based on data-driven insights. The right engineering management software should provide actionable insights based on the performance metrics of your team. This further helps in identifying bottlenecks, streamlining processes, and improving the developer experience (DX). Businesses that utilize engineering management software experience fewer delays and reduced project failure rates, so they're 2.5 times more successful on average.
One main functionality of EMP is transforming raw data into actionable insights, serving as a software engineering intelligence tool that provides data-driven insights into team productivity and performance. This is done by analyzing performance metrics to identify trends, inefficiencies, and potential bottlenecks in the software delivery process.
The Engineering Management Platform helps risk management by identifying potential vulnerabilities in the codebase, monitoring technical debt, and assessing the impact of changes in real time.
These platforms foster collaboration between cross-functional teams (Developers, testers, product managers, etc). They can be integrated with team collaboration tools like Slack, JIRA, and MS Teams. EMPs can also facilitate client management by streamlining communication and workflows with clients, ensuring that contracts and operational processes are efficiently handled within the project lifecycle. It promotes knowledge sharing and reduces silos through shared insights and transparent reporting. Communication tools in an engineering management platform should include features like discussion threads and integrations with messaging apps for seamless communication.
EMPs provide metrics to track performance against predefined benchmarks and allow organizations to assess development process effectiveness. By measuring KPIs, engineering leaders can identify areas of improvement and optimize workflows for better efficiency. Additionally, EMPs help monitor and enhance project performance by offering detailed metrics and analysis, enabling teams to track progress, allocate resources effectively, and improve overall project outcomes.
Developer Experience refers to how easily developers can perform their tasks. When the right tools are available, the process is streamlined and DX leads to an increase in productivity and job satisfaction. Engineering Management Platforms (EMPs) are specifically designed to improve developer productivity by providing the right tools and insights that help teams work more efficiently.
Key aspects include:
Engineering Velocity can be defined as the team's speed and efficiency during software delivery. To track it, the engineering leader must have a bird's-eye view of the team's performance and areas of bottlenecks.
Key aspects include:
Engineering Management Software must align with broader business goals to help move in the right direction. This alignment is necessary for maximizing the impact of engineering work on organizational goals.
Key aspects include:
The engineering management platform offers end-to-end visibility into developer workload, processes, and potential bottlenecks. It provides centralized tools for the software engineering team to communicate and coordinate seamlessly by integrating with platforms like Slack or MS Teams. It also allows engineering leaders and developers to have data-driven and sufficient context around 1:1.
Engineering software offers 360-degree visibility into engineering workflows to understand project statuses, deadlines, and risks for all stakeholders. This helps identify blockers and monitor progress in real-time. It also provides engineering managers with actionable data to guide and supervise engineering teams.
EMPs allow developers to adapt quickly to changes based on project demands or market conditions. They foster post-mortems and continuous learning and enable team members to retrospectively learn from successes and failures.
EMPs provide real-time visibility into developers' workloads that allow engineering managers to understand where team members' time is being invested. This allows them to know their developers' schedule and maintain a flow state, hence, reducing developer burnout and workload management.
Engineering project management software provides actionable insights into a team's performance and complex engineering projects. It further allows the development team to prioritize tasks effectively and engage in strategic discussions with stakeholders.
The first and foremost point is to assess your team's pain points. Identify the current challenges such as tracking progress, communication gaps, or workload management. Also, consider Team Size and Structure such as whether your team is small or large, distributed or co-located, as this will influence the type of platform you need.
Be clear about what you want the platform to achieve, for example: improving efficiency, streamlining processes, or enhancing collaboration.
When choosing the right EMP for your team, consider assessing the following categories: features, scalability, integration capabilities, user experience, pricing, and security. Additionally, having a responsive support team is crucial for timely assistance and effective implementation, ensuring your team can address issues quickly and make the most of the software. Consider the user experience when selecting engineering management software to ensure it is intuitive for all team members.
Most teams are adopting AI coding tools faster than they’re measuring their effects. That gap is where engineering management platforms matter. The useful ones don’t just show “how much AI was used.” They track acceptance rates, review rework, time-to-merge shifts, and whether AI-generated code actually improves throughput without dragging maintainability. Adoption without this level of measurement is guesswork. With it, you can see where AI is helping, where it’s creating silent complexity, and how it’s reshaping the real cost and pace of delivery.
A good EMP must evaluate how well the platform supports efficient workflows and provides a multidimensional picture of team health including team well-being, collaboration, and productivity.
The Engineering Management Platform must have an intuitive and user-friendly interface for both tech and non-tech users. It should also include customization of dashboards, repositories, and metrics that cater to specific needs and workflow.
The right platform helps in assessing resource allocation across various projects and tasks such as time spent on different activities, identifying over or under-utilization of resources, and quantifying the value delivered by the engineering team. Resource management software should help managers allocate personnel and equipment effectively and track utilization rates.
Strong integrations centralize the workflow, reduce fragmentation, and improve efficiency. These platforms must integrate seamlessly with existing tools, such as project management software, communication platforms, and CRMs. Robust security measures and compliance with industry standards are crucial features of an engineering management platform due to the sensitive nature of engineering data.
The platform must offer reliable customer support through multiple channels such as chat, email, or phone. You can also take note of extensive self-help resources like FAQs, tutorials, and forums.
Research various EMPs available in the market. Now based on your key needs, narrow down platforms that fit your requirements. Use resources like reviews, comparisons, and recommendations from industry peers to understand real-world experiences. You can also schedule demos with shortlisted providers to know the features and usability in detail.
Opt for a free trial or pilot phase to test the platform with a small group of users to get a hands-on feel. Afterward, Gather feedback from your team to evaluate how well the tool fits into their workflows.
Finally, choose the EMP that best meets your requirements based on the above-mentioned categories and feedback provided by the team members.
Typo is an effective engineering management platform that offers SDLC visibility, developer insights, and workflow automation to build better programs faster. It can seamlessly integrate into tech tool stacks such as GIT versioning, issue tracker, and CI/CD tools.
It also offers comprehensive insights into the deployment process through key metrics such as change failure rate, time to build, and deployment frequency. Moreover, its automated code tool helps identify issues in the code and auto-fixes them before you merge to master.
Typo has an effective sprint analysis feature that tracks and analyzes the team's progress throughout a sprint. Besides this, It also provides 360 views of the developer experience i.e. captures qualitative insights and provides an in-depth view of the real issues.
Successfully deploying an engineering management platform begins with comprehensive analysis of your engineering team's existing workflows and the technological stack already integrated within your development ecosystem. Engineering leaders should dive into mapping current toolchains and processes to identify API integration points and leverage optimization opportunities across the software development lifecycle. Automated workflow transitions help reduce lead time in software development. Engaging key stakeholders—including project managers, software engineers, and cross-functional team members—early in the deployment process ensures that diverse requirements and technical constraints are addressed from the initial phase.
A phased implementation strategy leverages iterative deployment methodologies, enabling engineering teams to gradually adapt to the new management platform without disrupting ongoing development sprints and project delivery pipelines. This approach also facilitates continuous feedback loops and real-time adjustments, ensuring seamless integration across distributed teams and microservices architectures. Comprehensive onboarding sessions and continuous support mechanisms are critical for accelerating user adoption and maximizing the platform's transformative capabilities.
By strategically orchestrating the deployment process and providing necessary technical resources, organizations can rapidly enhance resource optimization, streamline cross-team collaboration, and gain unprecedented visibility into project velocity and delivery metrics. This data-driven approach not only minimizes change resistance but also accelerates time-to-value realization from the new management infrastructure.
Advanced engineering management algorithms serve as the foundational framework for orchestrating complex engineering project ecosystems that align with strategic business objectives. Engineering managers and technical leaders must implement comprehensive project planning architectures that systematically define deliverables, establish milestone checkpoints, and map inter-dependencies across development workflows. Implementing data-driven timeline optimization algorithms and ensuring precision resource allocation through machine learning-powered capacity planning are critical components for maintaining project trajectory alignment and budget constraint adherence.
Deploying sophisticated task management platforms—including Gantt chart visualization systems, agile board orchestration tools, and Kanban workflow engines—enables development teams to monitor real-time progress metrics, optimize workload distribution algorithms, and proactively identify potential bottleneck scenarios through predictive analytics. Continuously analyzing performance indicators through automated monitoring systems—encompassing developer productivity coefficients, technical debt accumulation patterns, and project profitability optimization models—empowers engineering management frameworks to execute data-driven decision algorithms and implement automated corrective action protocols.
Establishing continuous improvement architectures through cultural transformation algorithms proves equally critical for organizational optimization. Implementing feedback collection mechanisms, deploying achievement recognition frameworks, and supporting professional development pathways through machine learning-driven career progression models contribute to enhanced job satisfaction metrics among software engineering personnel. Through adopting these algorithmic best practices and leveraging integrated engineering management platforms, organizations can amplify operational efficiency coefficients, support strategic initiative execution, and ensure successful delivery optimization across multiple project pipelines. This comprehensive systematic approach not only enhances project outcome metrics but also strengthens team health indicators and long-term business performance optimization.
An Engineering Management Platform (EMP) not only streamlines workflow but transforms the way teams operate. These platforms foster collaboration, reduce bottlenecks, and provide real-time visibility into progress and performance.

Maintaining a balance between speed and code quality is a challenge for every developer.
Deadlines and fast-paced projects often push teams to prioritize rapid delivery, leading to compromises in code quality. This can result in bad code, which negatively impacts maintainability, increases technical debt, and can ultimately jeopardize project outcomes.
The hidden costs of poor code quality are real, impacting everything from development cycles to team morale. Poor quality can lead to unreliable products and additional strain on teams. This blog delves into the real impact of low code quality on software projects, its common causes, and actionable solutions tailored to developers looking to elevate their code standards.
Code quality goes beyond writing functional code. Good code stands in contrast to low quality code by being more maintainable, reliable, and easier to work with, leading to fewer issues and better long-term outcomes. High-quality code is characterized by readability, maintainability, scalability, and reliability. Ensuring these aspects helps the software evolve efficiently without causing long-term issues for developers. Writing code that follows best practices is essential for the long-term success of any project.
Low code quality can significantly impact various facets of software development. Developers often struggle with poor quality code, which introduces challenges such as increased bugs, maintenance difficulties, and unreliable software. Poor software quality can also lead to broader negative outcomes, including delayed releases, higher costs, and reduced customer satisfaction. When tracing bugs or implementing new features, the quality of the source code directly affects how efficiently these tasks can be completed. Below are key issues developers face when working with substandard code, including how low code quality makes it harder for other developers to understand, maintain, and contribute to the project:
Low-quality code often involves unclear logic and inconsistent practices, making it difficult for developers to trace bugs or implement new features. This can turn straightforward tasks into hours of frustrating work, delaying project milestones and adding stress to sprints.
Technical debt accrues when suboptimal code is written to meet short-term goals. While it may offer an immediate solution, it complicates future updates. Developers need to spend significant time refactoring or rewriting code, which detracts from new development and wastes resources.
Substandard code tends to harbor hidden bugs that may not surface until they affect end-users. These bugs can be challenging to isolate and fix, leading to patchwork solutions that degrade the codebase further over time.
When multiple developers contribute to a project, low code quality can cause misalignment and confusion. Developers might spend more time deciphering each other's work than contributing to new development, leading to decreased team efficiency and a lower-quality product.
A codebase that doesn't follow proper architectural principles will struggle when scaling. For instance, tightly coupled components make it hard to isolate and upgrade parts of the system, leading to performance issues and reduced flexibility.
Constantly working with poorly structured code is taxing. The mental effort needed to debug or refactor a convoluted codebase can demoralize even the most passionate developers, leading to frustration, reduced job satisfaction, and burnout.
Code readability and maintainability serve as foundational pillars for delivering high-quality software solutions and ensuring sustainable SDLC success across development organizations. Readable codebases enable development teams to rapidly comprehend business logic and architectural patterns behind existing functionality, streamlining debugging workflows, feature extensions, and technical debt reduction without introducing regressions or compromising system integrity. When code adheres to established design patterns and coding standards, teams can efficiently adapt to evolving requirements and deploy robust features with confidence.
Poor code quality, conversely, generates convoluted, legacy codebases that significantly impact development velocity and organizational resources. This deterioration triggers increased development cycles, elevated operational costs, and mounting frustration across engineering teams. Complex implementations featuring deeply nested logic structures, inconsistent formatting patterns, or inadequate documentation can severely bottleneck CI/CD pipelines, transforming routine modifications into high-risk, resource-intensive operations. Over time, these technical challenges erode developer productivity metrics, reduce team satisfaction scores, and contribute to elevated turnover rates within engineering organizations.
Implementing comprehensive code review processes and enforcing strict adherence to established coding standards represents essential practices for maintaining software quality. Robust peer review workflows help identify code smells, security vulnerabilities, and architectural anti-patterns early within the SDLC, ensuring codebases remain maintainable and scalable. Developing comprehensive unit test suites and engaging in pair programming methodologies further promote modular architectures while encouraging developers to apply critical thinking to their technical solutions, minimizing the introduction of complex logic paths or technical debt accumulation.
Conducting regular refactoring initiatives represents another critical practice for sustaining high-quality software architecture. By simplifying complex algorithmic implementations and eliminating accumulated technical debt, development teams can enhance code readability while building more resilient systems capable of handling future requirements changes. Consistent coding standards, often derived from proven design patterns like Singleton, Factory, or Observer patterns, establish unified development approaches that help new team members quickly understand architectural patterns and contribute effectively to project deliverables.
Automated analysis tools, including static code analyzers, linters, and security scanning solutions, play vital roles in maintaining comprehensive code quality across development environments. These tools can detect code smells, identify potential security vulnerabilities, and flag performance bottlenecks before they escalate to production environments, enabling teams to address technical issues proactively within their development workflows. Automated testing frameworks further reinforce these quality assurance efforts by catching regressions and ensuring code modifications don't compromise existing application functionality.
Prioritizing code readability and maintainability standards reduces dependency on emergency hotfixes and patch deployments while fostering continuous improvement culture across development organizations. Maintainable and well-documented codebases facilitate effective knowledge transfer processes, enabling developers to understand complex business logic with minimal cognitive overhead and ensuring seamless onboarding experiences for new engineering team members.
Ultimately, investing in comprehensive code quality improvement initiatives—including automated code review processes, robust testing frameworks, and systematic refactoring practices—empowers development teams to focus on delivering high-quality software solutions that generate measurable business value. By implementing these industry best practices, organizations can accelerate development velocity, drive technical innovation, and achieve sustainable success within competitive software markets.
Understanding the reasons behind low code quality helps in developing practical solutions. Poor coding practices can result in net negative work, where developer effort leads to no progress or even additional problems. Here are some of the main causes:
Manual processes, such as code reviews done without automation, are often time-consuming and susceptible to human error, which can negatively impact code quality.
Tight project deadlines often push developers to prioritize quick delivery over thorough, well-thought-out code. While this may solve immediate business needs, it sacrifices code quality and introduces problems that require significant time and resources to fix later.
Without established coding standards, developers may approach problems in inconsistent ways. This lack of uniformity leads to a codebase that's difficult to maintain, read, and extend. Coding standards help enforce best practices and maintain consistent formatting and documentation.
Skipping code reviews means missing opportunities to catch errors, bad practices, or code smells before they enter the main codebase. Peer reviews help maintain quality, share knowledge, and align the team on best practices.
A codebase without sufficient testing coverage is bound to have undetected errors. Tests, especially automated ones, help identify issues early and ensure that any code changes do not break existing features.
Low-code platforms offer rapid development but often generate code that isn't optimized for long-term use. This code can be bloated, inefficient, and difficult to debug or extend, causing problems when the project scales or requires custom functionality.
Addressing low code quality requires deliberate, consistent effort. Enhancing code quality is a key goal of the solutions provided below, as it leads to more sustainable and secure software development. Maintaining high code quality is essential for long-term software success, stability, and protecting your projects from bugs and crashes. Here are expanded solutions with practical tips to help developers maintain and improve code standards:
Code reviews should be an integral part of the development process. They serve as a quality checkpoint to catch issues such as inefficient algorithms, missing documentation, or security vulnerabilities. To make code reviews effective:
Linters help maintain consistent formatting and detect common errors automatically. Tools like ESLint (JavaScript), RuboCop (Ruby), and Pylint (Python) check your code for syntax issues and adherence to coding standards. Static analysis tools go a step further by analyzing code for complex logic, performance issues, and potential vulnerabilities. To optimize their use:
Adopt a multi-layered testing strategy to ensure that code is reliable and bug-free:
Refactoring helps improve code structure without changing its behavior. Regularly refactoring prevents code rot and keeps the codebase maintainable. Practical strategies include:
Having a shared set of coding standards ensures that everyone on the team writes code with consistent formatting and practices. To create effective standards:
Typo can be a game-changer for teams looking to automate code quality checks and streamline reviews. It offers a range of features:
Keeping the team informed on best practices and industry trends strengthens overall code quality. To foster continuous learning:
Low-code tools should be leveraged for non-critical components or rapid prototyping, but ensure that the code generated is thoroughly reviewed and optimized. For more complex or business-critical parts of a project:
Improving code quality is a continuous process that requires commitment, collaboration, and the right tools. Developers should assess current practices, adopt new ones gradually, and leverage automated tools like Typo to streamline quality checks.
By incorporating these strategies, teams can create a strong foundation for building maintainable, scalable, and high-quality software. Investing in code quality now paves the way for sustainable development, better project outcomes, and a healthier, more productive team.
Sign up for a quick demo with Typo to learn more!

In today's fast-paced and rapidly evolving software development landscape, effective project management is crucial for engineering teams striving to meet deadlines, deliver quality products, and maintain customer satisfaction. Project management not only ensures that tasks are completed on time but also optimizes resource allocation enhances team collaboration, and improves communication across all stakeholders. A key tool that has gained prominence in this domain is JIRA, which is widely recognized for its robust features tailored for agile project management.
However, while JIRA offers numerous advantages, such as customizable workflows, detailed reporting, and integration capabilities with other tools, it also comes with limitations that can hinder its effectiveness. For instance, teams relying solely on JIRA dashboard gadget may find themselves missing critical contextual data from the development process. They may obtain a snapshot of project statuses but fail to appreciate the underlying issues impacting progress. Understanding both the strengths and weaknesses of JIRA dashboard gadget is vital for engineering managers to make informed decisions about their project management strategies.
JIRA dashboard gadgets primarily focus on issue tracking and project management, often missing critical contextual data from the development process. While JIRA can show the status of tasks and issues, it does not provide insights into the actual code changes, commits, or branch activities that contribute to those tasks. This lack of context can lead to misunderstandings about project progress and team performance. For example, a task may be marked as "in progress," but without visibility into the associated Git commits, managers may not know if the team is encountering blockers or if significant progress has been made. This disconnect can result in misaligned expectations and hinder effective decision-making.
JIRA dashboards having road map gadget or sprint burndown gadget can sometimes present a static view of project progress, which may not reflect real-time changes in the development process. For instance, while a JIRA road map gadget or sprint burndown gadget may indicate that a task is "done," it does not account for any recent changes or updates made in the codebase. This static nature can hinder proactive decision-making, as managers may not have access to the most current information about the project's health. Additionally, relying on historical data can create a lag in response to emerging issues in issue statistics gadget. In a rapidly changing development environment, the ability to react quickly to new information is crucial for maintaining project momentum hence we need to move beyond default chart gadget like road map gadget or burndown chart gadget.
Collaboration is essential in software development, yet JIRA dashboards often do not capture the collaborative efforts of the team. Metrics such as code reviews, pull requests, and team discussions are crucial for understanding how well the team is working together. Without this information, managers may overlook opportunities for improvement in team dynamics and communication. For example, if a team is actively engaged in code reviews but this activity is not reflected in JIRA gadgets or sprint burndown gadget, managers may mistakenly assume that collaboration is lacking. This oversight can lead to missed opportunities to foster a more cohesive team environment and improve overall productivity.
JIRA dashboard or other copy dashboard can sometimes encourage a focus on individual performance metrics rather than team outcomes. This can foster an environment of unhealthy competition, where developers prioritize personal achievements over collaborative success. Such an approach can undermine team cohesion and lead to burnout. When individual metrics are emphasized, developers may feel pressured to complete tasks quickly, potentially sacrificing code quality and collaboration. This focus on personal performance can create a culture where teamwork and knowledge sharing are undervalued, ultimately hindering project success.
JIRA dashboard layout often rely on predefined metrics and reports, which may not align with the unique needs of every project or team. This inflexibility can result in a lack of relevant insights that are critical for effective project management. For example, a team working on a highly innovative project may require different metrics than a team maintaining legacy software. The inability to customize reports can lead to frustration and a sense of disconnect from the data being presented.
Integrating Git data with JIRA provides a more holistic view of project performance and developer productivity. Here’s how this integration can enhance insights:
By connecting Git repositories with JIRA, engineering managers can gain real-time visibility into commits, branches, and pull requests associated with JIRA issues & issue statistics. This integration allows teams to see the actual development work being done, providing context to the status of tasks on the JIRA dashboard gadet. For instance, if a developer submits a pull request that relates to a specific JIRA ticket, the project manager instantly knows that work is ongoing, fostering transparency. Additionally, automated notifications for changes in the codebase linked to JIRA issues keep everyone updated without having to dig through multiple tools. This integrated approach ensures that management has a clear understanding of actual progress rather than relying on static task statuses.
Integrating Git data with JIRA facilitates better collaboration among team members. Developers can reference JIRA issues in their commit messages, making it easier for the team to track changes related to specific tasks. This transparency fosters a culture of collaboration, as everyone can see how their work contributes to the overall project goals. Moreover, by having a clear link between code changes and JIRA issues, team members can engage in more meaningful discussions during stand-ups and retrospectives. This enhanced communication can lead to improved problem-solving and a stronger sense of shared ownership over the project.
With integrated Git and JIRA data, engineering managers can identify potential risks more effectively. By monitoring commit activity and pull requests alongside JIRA issue statuses, managers can spot trends and anomalies that may indicate project delays or technical challenges. For example, if there is a sudden decrease in commit activity for a specific task, it may signal that the team is facing challenges or blockers. This proactive approach allows teams to address issues before they escalate, ultimately improving project outcomes and reducing the likelihood of last-minute crises.
The combination of JIRA and Git data enables more comprehensive reporting and analytics. Engineering managers can analyze not only task completion rates but also the underlying development activity that drives those metrics. This deeper understanding can inform better decision-making and strategic planning for future projects. For instance, by analyzing commit patterns and pull request activity, managers can identify trends in team performance and areas for improvement. This data-driven approach allows for more informed resource allocation and project planning, ultimately leading to more successful outcomes.
To maximize the benefits of integrating Git data with JIRA, engineering managers should consider the following best practices:
Choose integration tools that fit your team's specific needs. Tools like Typo can facilitate the connection between Git and JIRA smoothly. Additionally, JIRA integrates directly with several source control systems, allowing for automatic updates and real-time visibility.

If you’re ready to enhance your project delivery speed and predictability, consider integrating Git data with your JIRA dashboards. Explore Typo! We can help you do this in a few clicks & make it one of your favorite dashboards.
Encourage your team to adopt consistent commit message guidelines. Including JIRA issue keys in commit messages will create a direct link between the code change and the JIRA issue. This practice not only enhances traceability but also aids in generating meaningful reports and insights. For example, a commit message like 'JIRA-123: Fixed the login issue' can help managers quickly identify relevant commits related to specific tasks.
Leverage automation features available in both JIRA and Git platforms to streamline the integration process. For instance, set up automated triggers that update JIRA issues based on events in Git, such as moving a JIRA issue to 'In Review' once a pull request is submitted in Git. This reduces manual updates and alleviates the administrative burden on the team.
Providing adequate training to your team ensures everyone understands the integration process and how to effectively use both tools together. Conduct workshops or create user guides that outline the key benefits of integrating Git and JIRA, along with tips on how to leverage their combined functionalities for improved workflows.
Implement regular check-ins to assess the effectiveness of the integration. Gather feedback from team members on how well the integration is functioning and identify any pain points. This ongoing feedback loop allows you to make incremental improvements, ensuring the integration continues to meet the needs of the team.
Create comprehensive dashboards that visually represent combined metrics from both Git and JIRA. Tools like JIRA dashboards, Confluence, or custom-built data visualization platforms can provide a clearer picture of project health. Metrics can include the number of active pull requests, average time in code review, or commit activity relevant to JIRA task completion.
With the changes being reflected in JIRA, create a culture around regular code reviews linked to specific JIRA tasks. This practice encourages collaboration among team members, ensures code quality, and keeps everyone aligned with project objectives. Regular code reviews also lead to knowledge sharing, which strengthens the team's overall skill set.
To illustrate the benefits of integrating Git data with JIRA, let’s consider a case study of a software development team at a company called Trackso.
Trackso, a remote monitoring platform for Solar energy, was developing a new SaaS platform that consisted of a diverse team of developers, designers, and project managers. The team relied heavily on JIRA for tracking project statuses, but they found their productivity hampered by several issues:
In 2022, Trackso's engineering manager decided to integrate Git data with JIRA. They chose GitHub for version control, given its robust collaborative features. The team set up automatic links between their JIRA tickets and corresponding GitHub pull requests and standardized their commit messages to include JIRA issue keys.
After implementing the integration, Trackso experienced significant improvements within three months:
Despite these successes, Trackso faced challenges during the integration process:
While JIRA dashboards are valuable tools for project management, they are insufficient on their own for engineering managers seeking to improve project delivery speed and predictability. By integrating Git data with JIRA, teams can gain richer insights into development activity, enhance collaboration, and manage risks more effectively. This holistic approach empowers engineering leaders to make informed decisions and drive continuous improvement in their software development processes. Embracing this integration will ultimately lead to better project outcomes and a more productive engineering culture. As the software development landscape continues to evolve, leveraging the power of both JIRA and Git data will be essential for teams looking to stay competitive and deliver high-quality products efficiently.

As platform engineering continues to evolve, it brings both promising opportunities and potential challenges.
As we look to the future, what changes lie ahead for Platform Engineering? In this blog, we will explore the future landscape of platform engineering and strategize how organizations can stay at the forefront of innovation.
Platform Engineering is an emerging technology approach that enables software developers with all the required resources. It acts as a bridge between development and infrastructure which helps in simplifying the complex tasks and enhancing development velocity. The primary goal is to improve developer experience, operational efficiency, and the overall speed of software delivery.
The rise in Platform Engineering will enhance developer experience by creating standard toolchains and workflow. In the coming time, the platform engineering team will work closely with developers to understand what they need to be productive. Moreover, the platform tool will be integrated and closely monitored through DevEx and reports. This will enable developers to work efficiently and focus on the core tasks by automating repetitive tasks, further improving their productivity and satisfaction.
Platform engineering is closely associated with the development of IDP. In today’s times, organizations are striving for efficiency, hence, the creation and adoption of internal development platforms will rise. This will streamline operations, provide a standardized way of deploying and managing applications, and reduce cognitive load. Hence, reducing time to market for new features and products, allowing developers to focus on delivering high-quality products more efficiently rather than managing infrastructure.
Modern software development demands rapid iteration. The ephemeral environments, temporary, ideal environments, will be an effective way to test new features and bugs before they are merged into the main codebase. These environments will prioritize speed, flexibility, and cost efficiency. Since they are created on-demand and short-lived, they will align perfectly with modern development practices.
As times are changing, AI-driven tools become more prevalent. These Generative AI tools such as GitHub Copilot and Google Gemini will enhance capabilities such as infrastructure as code, governance as code, and security as code. This will not only automate manual tasks but also support smoother operations and improved documentation processes. Hence, driving innovation and automating dev workflow.
Platform engineering is a natural extension of DevOps. In the future, the platform engineers will work alongside DevOps rather than replacing it to address its complexities and scalability challenges. This will provide a standardized and automated approach to software development and deployment leading to faster project initialization, reduced lead time, and increased productivity.
Software organizations are now shifting from project project-centric model towards product product-centric funding model. When platforms are fully-fledged products, they serve internal customers and require a thoughtful and user-centric approach in their ongoing development. It also aligns well with the product lifecycle that is ongoing and continuous which enhances innovation and reduces operational friction. It will also decentralize decision making which allows platform engineering leaders to make and adjust funding decisions for their teams.
Typo is an effective software engineering intelligence platform that offers SDLC visibility, developer insights, and workflow automation to build better programs faster. It can seamlessly integrate into tech tool stacks such as GIT versioning, issue tracker, and CI/CD tools.
It also offers comprehensive insights into the deployment process through key metrics such as change failure rate, time to build, and deployment frequency. Moreover, its automated code tool helps identify issues in the code and auto-fixes them before you merge to master.
Typo has an effective sprint analysis feature that tracks and analyzes the team’s progress throughout a sprint. Besides this, It also provides 360 views of the developer experience i.e. captures qualitative insights and provides an in-depth view of the real issues.


The future of platform engineering is both exciting and dynamic. As this field continues to evolve, staying ahead of these developments is crucial for organizations aiming to maintain a competitive edge. By embracing these predictions and proactively adapting to changes, platform engineering teams can drive innovation, improve efficiency, and deliver high-quality products that meet the demands of an ever-changing tech landscape.

Clean code principles are essential guidelines for software developers, engineers, and tech teams who want to write code that is simple, readable, and maintainable. In this guide, we’ll cover the most important clean code principles—including the Single Responsibility Principle (SRP), DRY (Don’t Repeat Yourself), YAGNI, KISS, the Boy Scout Rule, Fail Fast, the Open/Closed Principle, Consistency, Composition over Inheritance, Avoiding Hard-Coded Numbers, Abstraction, and Cohesion. Understanding and applying these clean code principles matters because it leads to higher-quality software, easier collaboration, and more sustainable development practices.
Robert C. Martin introduced the concept of ‘Clean Code’ in his book ‘Clean Code: A Handbook of Agile Software Craftsmanship’ (2008), defining it as:
“A code that has been taken care of. Someone has taken the time to keep it simple and orderly. They have laid appropriate attention to details. They have cared.”
Clean code is read more often than it is written, so readability and maintainability are crucial. Clean code is well-structured, free of unnecessary complexity, code smells, and anti-patterns. This guide will explain what clean code is, what its core characteristics look like in practice, and how applying clean code principles can help you write better code.
Clean code enables faster development and debugging, fosters collaboration among team members, reduces the likelihood of introducing bugs, improves onboarding for new developers, and reduces technical debt. By following clean code principles, teams can:
Transition: Now that we’ve defined clean code and why it’s important, let’s explore the key characteristics that set clean code apart.
Clean code is distinguished by several core characteristics that make it easier to read, maintain, and extend. Below, we break down these characteristics into specific, actionable qualities.
Transition: With these characteristics in mind, let’s dive into the specific clean code principles that help you achieve them.
Clean code principles focus on reducing complexity and enhancing readability for developers. By applying these principles, you can write code that is easier to understand, maintain, and extend.
Definition: Functions should follow the Single Responsibility Principle (SRP): each function should have one responsibility.
This principle states that each module or function should have a defined responsibility and one reason to change. Otherwise, it can result in bloated and hard-to-maintain code.
How to Apply:
Example:
javascript class User { constructor(name, email, password) { this.name = name; this.email = email; this.password = password; } }
class Authentication { login(user, password) { // ... login logic } register(user, password) { // ... registration logic } }
class EmailService { sendVerificationEmail(email) { // ... email sending logic } }
Definition: Follow the DRY (Don't Repeat Yourself) principle to reduce redundancy.
The DRY Principle states that unnecessary code duplication must be avoided. Instead, abstract common functionality into reusable functions, classes, or modules.
How to Apply:
Example:
javascript function formatGreeting(name, message) { return message + ", " + name + "!"; }
function greetUser(name) { console.log(formatGreeting(name, "Hello")); }
function sayGoodbye(name) { console.log(formatGreeting(name, "Goodbye")); }
Definition: YAGNI is an extreme programming practice that states, “Always implement things when you actually need them, never when you just foresee that you need them.”
How to Apply:
Definition: KISS stands for Keep It Simple, Stupid and prioritizes simple solutions over complexity.
This principle encourages direct and clear code, making it easier to understand and maintain.
How to Apply:
Example:
python def calculate_area(length, width): return length * width
Definition: Always leave the code in a better state than you found it.
This principle encourages continuous, small enhancements whenever engaging with the codebase, whether adding a feature or fixing a bug.
How to Apply:
Example:
Before:python def factorial(n): if n == 0: return 1 else: return n * factorial(n - 1)
result = factorial(5) print(result)
After:python def factorial(n): return 1 if n == 0 else n * factorial(n - 1)
print(factorial(5))
Definition: The code must fail as early as possible to limit bugs and address errors promptly.
How to Apply:
Definition: Software entities should be open to extension but closed to modification.
This means you can add new functionalities without changing existing code.
How to Apply:
Example:
Without Open/Closed Principle:python def calculate_salary(employee_type): if employee_type == "regular": return base_salary elif employee_type == "manager": return base_salary * 1.5 elif employee_type == "executive": return base_salary * 2 else: raise ValueError("Invalid employee type")
With Open/Closed Principle:python class Employee: def calculate_salary(self): raise NotImplementedError()
class RegularEmployee(Employee): def calculate_salary(self): return base_salary
class Manager(Employee): def calculate_salary(self): return base_salary * 1.5
class Executive(Employee): def calculate_salary(self): return base_salary * 2
Definition: Use established coding standards for consistency.
Consistency in naming conventions, coding styles, and formatting makes code easier to read and maintain.
How to Apply:
Definition: Prefer ‘has-a’ relationships (composition) over ‘is-a’ relationships (inheritance) for flexibility and maintainability.
How to Apply:
Example:
python class Engine: def start(self): pass
class Car: def init(self, engine): self.engine = engine
class SportsCar(Car): def init(self, engine, spoiler): super().init(engine) self.spoiler = spoiler
Definition: Avoid hard-coded numbers; use named constants instead.
Hard-coded numbers make code harder to read and maintain. Named constants clarify intent and simplify future changes.
How to Apply:
Example:python
discount_rate = 0.2
DISCOUNT_RATE = 0.2
Definition: Abstraction hides complex realities behind simple interfaces.
How to Apply:
Definition: Cohesion measures how closely related a module's responsibilities are.
How to Apply:
Transition: By applying these clean code principles, you can ensure your codebase remains robust, maintainable, and easy to work with as your project grows.
Typo's automated code review tool enables developers to catch issues related to code quality, detect code smells and potential bugs promptly, and improve code quality through continuous checks, similar to other leading code review tools for development teams.
With automated code reviews, auto-generated fixes, and highlighted hotspots, Typo streamlines the process of merging clean, secure, and high-quality code by bringing AI into the code review process. It automatically scans your codebase and pull requests for issues, generating safe fixes before merging to master, similar to other AI code review tools that improve development workflow. This strengthens clean code practices and helps maintain consistent standards across the codebase. Even output from AI assistants such as Claude Code still needs review to keep it clean and safe, underscoring how AI-powered review workflows should augment, not replace, human judgment. Hence, ensuring your code stays efficient and error-free.

Writing clean code isn't just a crucial skill for software developers—it is an important way to sustain software development projects.
By following the above-mentioned key clean code principles, you can develop a habit to write clean code by reducing complexity, improving readability for developers, and supporting collaboration among team members. It will take time but it will be worth it in the end.
Maintaining clean code throughout the software development lifecycle improves long-term code maintainability.

Platform engineering best practices are crucial for modern software development, as they play a key role in improving efficiency, security, and scalability within contemporary development practices.
Platform engineering is a relatively new and evolving field in the tech industry. To make the most of Platform Engineering, there are several best practices you should be aware of.
This guide is for platform engineers, software architects, and technical leaders seeking to implement best practices in platform engineering.
Adopting these best practices is essential for organizations aiming to improve developer productivity, ensure security, and scale efficiently.
In this blog, we explore these practices in detail and provide insights into how you can effectively implement them to optimize your development processes and foster innovation.
This article serves as a comprehensive guide to platform engineering, offering actionable best practices for organizations looking to successfully adopt and scale their platform engineering initiatives.
Leveraging internal platforms has fundamentally reshaped how organizations approach software development, deployment, and management. These centralized systems dive deep into streamlining essential workflows by consolidating critical tools, services, and development processes that empower teams to efficiently build, test, and deploy applications without unnecessary cross-team dependencies. The core objective centers on optimizing platform engineering through comprehensive automation and intelligent resource management, significantly reducing the cognitive burden that developers face daily. This transformation enables development teams to focus their energy on delivering innovative solutions and creating genuine business value, rather than getting bogged down in complex infrastructure management tasks that traditionally consume valuable development cycles.
The robust self-service capabilities embedded within modern internal platforms facilitate unprecedented developer autonomy, allowing teams to provision infrastructure resources, deploy applications, and manage critical services independently across various environments. This architectural approach not only accelerates development cycles through automated workflows and intelligent resource allocation, but also dramatically enhances overall developer productivity and experience by eliminating bottlenecks that typically slow down software delivery. By systematically minimizing operational overhead and automating routine, time-consuming tasks, these internal platforms ensure that developers can concentrate their expertise on innovation, complex problem-solving, and feature development, while dedicated platform teams manage the underlying infrastructure complexities and ensure seamless, reliable operations across the entire development ecosystem.
With this foundation, let's explore what platform engineering entails and why it is essential for modern organizations.
Platform Engineering, an emerging technology approach, is the practice of designing and managing the infrastructure, tools, and tech stack (the collection of technologies, tools, and frameworks used by platform teams) that support software development and deployment. Platform engineering treats the platform as a product, focusing on the needs of internal developer customers. This is to help them perform end-to-end operations of software development lifecycle automation. Platform engineering addresses the problem space of managing complex infrastructure, including cloud infrastructure as a critical component—especially for cost management and enabling self-service capabilities—and development workflows, ensuring that teams can overcome challenges related to scalability, reliability, and adoption. The aim is to reduce overall cognitive load, increase operational efficiency, and remove process bottlenecks by providing a reliable and scalable platform for building, deploying, and managing applications.
Identifying key areas where Infrastructure as Code (IaC) can be applied is vital for achieving scalable, reliable, and secure infrastructure.
With a clear understanding of the importance of platform engineering, let's examine how a developer-centric approach can further enhance platform effectiveness.
Always treat your platform engineering team as paying customers. This allows you to understand developers’ pain points, preferences, and requirements and focus on making the development process easier and more efficient.
Some of the key points that are taken into consideration:
It is also important to provide each application or system with its own setup—standardized and maintainable configurations that improve onboarding, development velocity, and system reliability.
Providing ‘golden paths’—standardized, best-practice workflows—helps guide developers through common tasks and project setups, making the platform more intuitive and efficient. Adopting a 'one platform' approach, where a unified interface consolidates tools and services, further streamlines developer workflows and reduces context switching.
When the above-mentioned needs and requirements are met, end-users are likely to adopt this platform enthusiastically. Hence, making the platform more effective and productive.
With a developer-centric mindset established, let's explore the benefits that internal developer platforms bring to organizations.
Internal developer platforms (IDPs) unleash a transformative wave of capabilities that fundamentally reshapes how organizations orchestrate their software development endeavors.
By establishing a centralized ecosystem equipped with sophisticated self-service functionality, IDPs empower developers to seamlessly access an extensive arsenal of tools, services, and streamlined workflows without becoming entangled in the intricate complexities of underlying infrastructure architectures.
This unprecedented level of streamlined access dramatically minimizes repetitive operational burdens and eliminates human error vectors. As a result, development teams can channel their expertise toward crafting and deploying exceptional, high-caliber applications with remarkable efficiency.
Automation emerges as a cornerstone advantage within IDP ecosystems. These intelligent systems masterfully orchestrate routine processes including resource provisioning, application deployment, and dynamic scaling operations. This substantially amplifies deployment frequency while ensuring unwavering consistency across diverse development teams.
Advanced security frameworks and granular access control mechanisms are seamlessly woven into the platform's fabric, guaranteeing that exclusively authorized personnel can access sensitive resources and critical system components.
Furthermore, robust disaster recovery capabilities are intricately integrated to safeguard applications and valuable data assets. This creates an additional layer of resilience that significantly fortifies the platform's overall reliability and operational continuity.
Through the strategic elimination of manual intervention requirements and substantial reduction of operational overhead burdens, internal developer platforms deliver unprecedented improvements in developer productivity, foster an environment of accelerated innovation, and enable organizations to propel new features to market with remarkable speed while maintaining enhanced security postures that protect both development processes and end-user experiences.
With these benefits in mind, the next step is to understand how standardized workflows, such as golden paths, further drive efficiency and consistency.
Golden paths represent standardized, meticulously optimized workflows that systematically guide development teams through the most efficient methodologies for building, testing, and deploying applications across diverse technological landscapes. Golden Paths are pre-approved, low-friction workflows that streamline the use of the platform. Through the establishment of these comprehensive best practices, organizations can dramatically reduce the cognitive overhead burden on developers, enabling them to strategically focus their efforts on delivering innovative features and solving complex business challenges rather than grappling with infrastructure complexities or wrestling with process inconsistencies that often plague modern software development environments.
These standardized approaches leverage historical data analysis and proven methodologies to create repeatable, reliable pathways that minimize decision fatigue and eliminate common pitfalls encountered during the development lifecycle.
Golden paths characteristically automate repetitive, resource-intensive tasks while embedding sophisticated self-service capabilities that facilitate seamless adoption of proven methodologies for software development and deployment across heterogeneous environments. This comprehensive approach not only ensures unwavering consistency and operational reliability across diverse projects and teams but also significantly accelerates delivery timelines by systematically removing unnecessary friction points from the development process.
The automation capabilities inherent in these golden paths analyze patterns in development workflows, predict potential bottlenecks, and proactively address common integration challenges before they impact productivity. Furthermore, these self-service mechanisms empower developers to independently access necessary resources, configure environments, and implement deployment strategies without requiring extensive coordination with external teams or specialized infrastructure knowledge.
Through the strategic embrace of golden paths, organizations systematically create an operational environment where established best practices become the default methodology, operational efficiency reaches optimal levels, and development teams can confidently deploy applications at enterprise scale with minimal risk exposure.
This transformative approach fundamentally reshapes the software development landscape by establishing clear guidelines that reduce variability, improve predictability, and enhance overall team performance. The resulting ecosystem enables organizations to achieve higher throughput, maintain superior quality standards, and foster a more satisfying developer experience that promotes innovation while ensuring adherence to organizational standards and compliance requirements.
Having established the importance of standardized workflows, we now turn to the tools and portals that enable these efficiencies.
An internal developer portal comprises a comprehensive technological ecosystem that serves as the centralized operational hub for development teams, facilitating unprecedented unified access to sophisticated toolchains, microservices architectures, and automated workflows essential for building, testing, and deploying enterprise-grade applications.
This strategically designed centralized platform leverages advanced service catalog methodologies, continuously updated technical documentation repositories, and meticulously crafted step-by-step implementation guides that enable developers to navigate complex internal platform infrastructures with optimal efficiency and minimal friction.
The internal developer portal simultaneously facilitates a culture of continuous improvement and operational excellence by incorporating sophisticated feedback loop mechanisms and data-driven enhancement protocols, enabling development teams to analyze their experiences comprehensively and suggest strategic optimizations that drive organizational transformation.
By streamlining access to critical development resources and eliminating operational confusion through intelligent automation, the portal significantly enhances the developer experience paradigm, accelerates productivity metrics across development lifecycles, and ensures that cross-functional teams can rapidly locate and leverage essential resources to maintain project momentum and meet aggressive delivery timelines.
Ultimately, an effectively implemented internal developer portal represents an indispensable strategic asset for maximizing the organizational value proposition of your internal platform infrastructure, providing comprehensive support for developers throughout every phase of the software development lifecycle continuum, and driving unprecedented organizational success through enhanced operational efficiency, reduced time-to-market metrics, and optimized resource allocation across enterprise development initiatives.
With a robust portal in place, it's vital to ensure that security is embedded at every layer of the platform.
Implement security controls at every layer of the platform. Integrate built-in security measures from the beginning, emphasizing automation, compliance standards, and proactive security management to ensure robust protection and streamline compliance efforts.
To adopt security best practices, follow these steps:
With security best practices in place, continuous improvement and feedback loops become the next focus for evolving your platform.
Continuous improvement must be one of the core principles to allow the platform to evolve according to technical trends. Integrate feedback mechanisms with the internal developer platform to gather insights from the software development lifecycle. Regularly review and improve the platform based on feedback from development teams. This enables rapid responses to any impediments developers face.
As your platform evolves, fostering a culture of collaboration ensures all stakeholders are aligned and engaged.
Foster communication and knowledge sharing among platform engineers, ensuring they work closely with other stakeholders to achieve shared goals. Align them with common goals and objects and recognize their collaborative efforts. This helps teams to understand how their work contributes to the overall success of the platform which further, fosters a sense of unity and purpose. It also ensures that all stakeholders understand how to effectively use the platform and contribute to its continuous improvement.
Collaboration is most effective when the platform team adopts a product mindset, focusing on delivering value to internal customers.
View your internal platform as a product that requires management and ongoing development, including identifying the key elements that define the platform's value proposition and objectives. The platform team must be driven by a product mindset that includes publishing roadmaps, gathering user feedback, and fostering a customer-centric approach. They must focus on what offers real value to their internal customers and app developers based on the feedback, so it addresses the pain points quickly.
A product mindset is best supported by a strong DevOps culture, which we discuss next.
Emphasize the importance of a DevOps culture that prioritizes collaboration between development and operations teams, highlighting how adopting devops practices fosters collaboration and streamlines processes. It is crucial to foster an environment where platform engineering can thrive and foster a shared responsibility for the software lifecycle.
With a DevOps culture in place, executive buy-in becomes the next critical factor for platform engineering success.
Securing executive buy-in and organizational support serves as the foundational cornerstone for the long-term success and sustainable scalability of any internal platform engineering initiative. When senior leadership comprehensively understands the strategic value proposition of platform engineering—encompassing enhanced developer velocity metrics, accelerated time-to-market for feature deployments, and reinforced security postures through standardized infrastructure patterns—they demonstrate significantly higher propensity to allocate requisite financial resources, technical infrastructure, and human capital investments essential for platform ecosystem maturation and operational excellence.
Executive sponsorship facilitates seamless alignment of internal platform architectures with broader organizational strategic requirements and technological roadmaps, ensuring that platform capabilities continuously evolve to address dynamic development team workflows and enterprise business objectives. Through active championing of platform adoption initiatives and driving cross-functional organizational integration, executives establish critical pathways for fostering innovation-centric cultures that prioritize operational efficiency, automated workflow optimization, and continuous improvement methodologies across development lifecycles. This leadership-driven approach enables comprehensive stakeholder engagement and eliminates traditional organizational silos that typically impede platform transformation initiatives.
With robust executive backing and strategic leadership commitment, platform engineering teams gain the organizational mandate to confidently invest in next-generation capabilities, implement scalable infrastructure solutions, and deliver comprehensive platform ecosystems that fundamentally empower developer productivity while accelerating measurable business outcomes. This executive alignment creates the necessary organizational framework for platform teams to establish best practices, implement standardized toolchains, and drive enterprise-wide digital transformation initiatives that directly contribute to competitive advantage and market responsiveness.
With executive support secured, it's important to be aware of common pitfalls and challenges that can hinder platform adoption.
While internal developer platforms deliver substantial value propositions through standardized workflows and infrastructure abstractions, enterprises frequently encounter critical implementation anti-patterns that can severely compromise platform adoption metrics and developer experience (DevX). Insufficient API documentation, inadequate onboarding processes, and absence of continuous platform support mechanisms leave engineering teams experiencing friction and decelerate organizational platform adoption velocity. Overly complex architectural patterns or rigid governance frameworks may inhibit innovation cycles and generate user resistance, fundamentally undermining the platform's strategic objectives around developer productivity optimization and operational efficiency gains.
To circumvent these implementation challenges, organizations must adhere to platform engineering best practices including establishing clear success metrics and key performance indicators (KPIs), implementing comprehensive documentation strategies with automated API reference generation, and delivering continuous support mechanisms through dedicated platform teams. Systematically evaluating platform performance through developer satisfaction surveys, usage analytics, and feedback loops ensures the platform architecture evolves in alignment with organizational scaling requirements while maintaining optimal user experience and minimizing cognitive load for consuming development teams.
As Charity Majors, a recognized thought leader in the observability and platform engineering space, emphasizes, organizations must develop deep domain expertise around their specific problem landscapes and architect solutions that strategically align with enterprise architectural objectives and developer workflow optimization. By maintaining focus on developer experience optimization and organizational scalability goals, engineering leadership can construct internal developer platforms that genuinely accelerate team velocity, reduce operational overhead, and drive sustained competitive advantage through enhanced development lifecycle efficiency.
Understanding these challenges, the next step is to measure success and productivity to ensure continuous improvement.
Measuring the success and productivity of your platform engineering team has fundamentally reshaped how organizations approach internal developer platforms and their operational excellence. By systematically tracking the right metrics and establishing comprehensive feedback loops, platform teams can continuously refine their methodologies, enhance developer experience, and support the rapid delivery of innovative features in contemporary software development ecosystems.
Let’s explore how strategic measurement transforms platform engineering effectiveness and highlight must-have metrics for optimizing internal developer platform performance.
Understanding how effectively your platform supports software development requires focusing on metrics that reflect both operational efficiency and developer productivity across multiple dimensions. DORA and SPACE metrics are widely recognized frameworks for tracking platform engineering performance and should be incorporated to provide a holistic view of team effectiveness:
For a deeper understanding of these and other DevOps metrics, explore how tracking them can identify bottlenecks, boost efficiency, and accelerate software delivery.
Monitoring should be built into your platform from the start to ensure visibility into application performance and resource usage. Observability practices require centralized logging, metrics, tracing, and dashboards to monitor system health and quickly identify issues.
Reducing the cognitive burden on developers represents a fundamental principle of platform engineering that directly impacts organizational velocity. By systematically automating repetitive tasks—such as provisioning infrastructure resources, managing complex access controls, or configuring multi-cloud environments—platform teams empower developers to concentrate on building innovative application code rather than managing underlying infrastructure complexities.
Infrastructure as Code tools, such as Terraform or OpenTofu, are essential for automated, version-controlled infrastructure provisioning.
Advanced platform implementations track quantitative metrics including time saved through self-service tools, reduction in support ticket volume, and developer satisfaction scores to provide comprehensive insights into platform impact on productivity. Organizations typically observe 30-50% reductions in infrastructure-related developer overhead when implementing effective platform engineering practices.
Infrastructure as Code tools, such as Terraform or OpenTofu, are essential for automated, version-controlled infrastructure provisioning, enabling consistent and repeatable environments that support measurement and automation goals.
The operational success of an internal platform correlates directly with its adoption rates among software teams and overall user satisfaction metrics. Comprehensive monitoring encompasses usage analytics such as active user counts, services provisioned through platform APIs, deployment volumes, and feature utilization patterns across different development teams.
Regularly gathering qualitative feedback from development teams via structured surveys, in-depth interviews, and continuous feedback loops enables platform teams to assess satisfaction levels and identify specific areas requiring improvement. High adoption rates combined with positive feedback scores serve as strong indicators that your platform effectively meets user requirements and delivers tangible value to development workflows.
Effective platform engineering implementations require vigilant cost optimization and strict adherence to security policies across all operational dimensions. Organizations must implement comprehensive monitoring systems that track resource utilization and resource usage across cloud platforms and existing infrastructure components, ensuring efficient resource allocation while minimizing operational waste and unnecessary expenditure. Preventative cost controls can be implemented as pre-deployment gates to manage budget limits effectively and avoid overspending.
Regular security scanning protocols, granular access controls, automated compliance auditing, and continuous vulnerability assessments help maintain secure and compliant operational environments. These practices reduce the risk of human error while ensuring the platform architecture evolves in alignment with organizational security requirements and regulatory compliance standards.
To ensure your platform engineering initiatives align with business objectives and continuously improve operational effectiveness, organizations should implement these comprehensive best practices:
By systematically measuring success and productivity across these multiple dimensions, platform teams can optimize platform engineering effectiveness, drive organizational innovation, and ensure their internal developer platforms remain the foundational infrastructure for efficient, secure, and scalable software development practices. This comprehensive measurement approach not only enhances developer experience but also supports broader organizational objectives, ensuring your platform infrastructure continues to evolve and deliver measurable value as organizational requirements mature and expand.
Below is a summary of the most important platform engineering best practices, each supported by industry-proven facts:
Typo is an effective platform engineering tool that offers SDLC visibility, developer insights, and workflow automation to build better programs faster. It can seamlessly integrate into tech tool stacks such as GIT versioning, issue tracker, and CI/CD tools.
It also offers comprehensive insights into the deployment process through key metrics such as change failure rate, time to build, and deployment frequency. Moreover, its automated code tool helps identify issues in the code and auto-fixes them before you merge to master.

Platform Engineering is reshaping how we approach software development by identifying and implementing the best platforms to optimize performance and efficiency, streamlining infrastructure management, and improving operational efficiency.
Adhering to best practices allows organizations to harness the full potential of their platforms. As a platform matures, it should evolve towards a self-service model that empowers application teams while maintaining governance and control.
Embracing these principles will optimize your development processes, drive innovation, and ensure a stable foundation for future growth.

DevOps for startups is a way of working that brings software development and IT operations together to ship products faster, improve collaboration, raise release quality, and use limited engineering resources more efficiently. This article is designed for startup founders, IT leaders, development teams, and DevOps practitioners who want to understand and implement effective DevOps strategies tailored for startups. We will cover the core principles of DevOps, its importance for startups, key benefits, and actionable practices such as automation with CI/CD tools, continuous integration and delivery, infrastructure as code, containerization, monitoring, security integration, leveraging software engineering intelligence platforms, fostering collaboration, encouraging continuous learning, and establishing clear standards and documentation.
DevOps is especially important for startups because it enables rapid product delivery, efficient use of resources, and the ability to adapt quickly to market changes. DevOps practices help startups avoid unnecessary technical debt early on, ensuring that teams can scale efficiently and maintain focus on business goals. For startups, where speed to market, reliability, and customer experience directly affect whether a product can compete, adopting DevOps is a strategic advantage.
DevOps is a methodology that merges software development (Dev) with IT operations (Ops) to shorten the development lifecycle while maintaining high software quality. Collaboration between development and operations is essential in DevOps. Creating a DevOps culture promotes collaboration, which is essential for continuous delivery. IT operations and development teams share ideas and provide prompt feedback, accelerating the application launch cycle.
Transition: Now that we've defined DevOps and its collaborative nature, let's examine why it is particularly crucial for startups.
In the competitive startup environment, time equates to money. Delayed product launches risk competitors beating you to market. Even with an early market entry, inefficient development processes can hinder timely feature rollouts that customers need. DevOps practices help startups avoid unnecessary technical debt early on.
Startups should implement DevOps early for better agility, and adopting DevOps with CI/CD practices helps achieve faster time-to-market while staying aligned with business goals. Startups frequently lose sight of their business goals during DevOps implementation, so it is important to stay focused on priorities. This also helps teams keep pace with industry leaders without losing sight of priorities as they implement DevOps.
Transition: Understanding the importance, let's look at the foundational principles that drive DevOps success in startups.
The foundation of DevOps rests on the principles of culture, automation, measurement, and sharing (CAMS). DevOps principles emphasize collaboration, automation, and continuous feedback. These core DevOps principles drive continuous improvement and innovation in startups, and successful adoption depends on a collaborative culture across developers and operations teams throughout the organization.
Transition: With these principles in mind, let's explore the key benefits DevOps brings to startups.
Startups using DevOps can deliver products faster and more reliably.
DevOps accelerates development and release processes through automated workflows and continuous feedback integration, enabling startups to deploy multiple changes a day with short lead times through continuous workflows.
DevOps enhances workflow efficiency and productivity by automating repetitive DevOps tasks, reducing manual operational work, and minimizing manual errors.
DevOps ensures code changes are continuously tested and validated so high-quality code is deployed more reliably, reducing failure risks.
Transition: Having seen the benefits, let's move on to the practical DevOps strategies and practices that startups can implement for success.
Below are actionable DevOps strategies and practices tailored for startups. These are organized from general to more specific practices for clarity and ease of implementation.
Automation tools are essential for accelerating the software delivery process. Startups should use CI/CD tools to automate testing, integration, and deployment for reliability while reducing manual overhead across their DevOps processes for the development team. Well-structured pipelines also help avoid unnecessary technical debt.
Recommended tools:
Implementing DevOps practices with CI/CD helps startups deliver faster by triggering automated builds and tests and supporting frequent integration. Frequent integration helps identify issues early in development, and automating CI/CD can cut build times by 90%.
Key steps:
IaC allows startups to manage infrastructure through code, creating consistent environments, reducing human error, and enabling more efficient infrastructure management as teams scale, while also supporting scalability for growing teams.
Recommended tools:
Containerization simplifies deployment and improves resource utilization.
Recommended tools:
Implement robust monitoring tools to monitor production performance and service uptime. Key DevOps and DORA metrics help the company measure software delivery effectiveness, while proactive monitoring catches issues early so teams can focus on uptime.
Recommended tools:
Incorporate security practices into the DevOps pipeline using a shift left approach, integrating security checks into the development cycle to help prevent vulnerabilities and reduce risk. Neglecting security best practices can also lead to costly fines, especially as a startup grows.
Recommended tools:
SEI platforms provide critical insights into the engineering processes, enhancing decision-making and efficiency.
Key features:
Utilize collaborative tools to enhance communication among team members. A strong DevOps culture also helps attract job-seeking engineers by signaling quality and maturity to prospective employees.
Recommended tools:
Promote a culture of continuous learning through:
Create a repository for documentation and coding standards. Most startups should keep standards light at first, since one of the common challenges is that startups often over-engineer their DevOps processes and workflows before the organization needs them.
Recommended tools:
Transition: With these practices in place, let's see how Typo can further support DevOps teams in startups.
Typo is a powerful tool designed specifically for tracking and analyzing DevOps metrics. It provides an efficient solution for dev and ops teams seeking precision in their performance measurement.
Implementing the DevOps methodology helps many startups balance rapid innovation with stability as they grow. DevOps helps startups balance rapid innovation with stability.
By integrating continuous integration and deployment, leveraging infrastructure as code, employing automated testing, and maintaining continuous monitoring, startups can effectively tackle issues like limited resources and skill shortages.
Moreover, fostering a cooperative culture is essential for successful DevOps adoption. By adopting these strategies, startups can create durable, scalable solutions for end users and secure long-term success in a competitive landscape, provided implementation stays tied to business goals rather than process for its own sake.

This guide is for engineering leaders, DevOps professionals, and software teams interested in optimizing continuous delivery using DORA metrics. DORA metrics—deployment frequency, lead time for changes, change failure rate, and mean time to recover (MTTR)—are four key performance indicators that measure software delivery performance. We will cover what DORA metrics are, their pros and cons for continuous delivery, and best practices for implementation.
DORA metrics offer a valuable, data-driven framework for assessing software delivery performance throughout the software delivery lifecycle. As a standard set of DevOps metrics used for evaluating process performance and maturity, DORA metrics are based on extensive research conducted by Google's DevOps Research and Assessment team. They provide organizations with insights to improve software delivery, help prove the business value of DevOps, and are linked to higher organizational performance targets. Measuring DORA key metrics allows engineering leaders to identify bottlenecks, improve efficiency, and enhance software quality, directly impacting customer satisfaction. These metrics are also a key indicator for measuring the effectiveness of continuous delivery pipelines.
DORA metrics are four key performance indicators that measure software delivery performance: deployment frequency, lead time for changes, change failure rate, and mean time to recover (MTTR). They provide a data-driven framework for measuring and improving software delivery performance, helping teams identify bottlenecks, improve processes, and deliver software faster and more reliably. By balancing speed and quality, DORA metrics enable teams to optimize their software delivery processes. As a standard set of DevOps metrics, they are widely used for evaluating process performance and maturity, making them essential for organizations aiming to achieve high-performing, reliable, and efficient software delivery.
Continuous delivery (CD) is a primary aspect of modern software development that automatically prepares code changes for release to a production environment. It is combined with continuous integration (CI), and together, these two practices are known as CI/CD. CD pipelines hold significant importance compared to traditional waterfall-style development, enabling faster, more reliable, and more frequent releases. This foundational context is essential for understanding how DORA metrics are applied to optimize continuous delivery.
Now that we have established the basics of continuous delivery and CI/CD, let's explore what DORA metrics are and how they fit into this framework.
DORA metrics were developed by the DevOps Research and Assessment (DORA) team at Google Cloud, founded by Gene Kim, Jez Humble, and Dr. Nicole Forsgren. DORA metrics are a standard set of DevOps metrics used for evaluating process performance and maturity. The four DORA metrics—deployment frequency, lead time for changes, change failure rate, and mean time to recover (MTTR)—are key performance indicators that assess the effectiveness and efficiency of the software delivery process. These metrics focus on aspects like velocity and stability to evaluate the efficiency and reliability of the development process. Objective benchmarking with DORA metrics categorizes teams into performance tiers based on multi-year research, highlighting significant performance differences among tiers and providing a data-driven approach to evaluate the impact of operational practices on software delivery performance.
In the next section, we will define each of the four key DORA metrics and explain their significance in measuring software delivery performance.
DORA metrics are four key performance indicators that measure software delivery performance: deployment frequency, lead time for changes, change failure rate, and mean time to recover (MTTR). Here are the definitions and significance of each:
In 2021, the DORA Team added Reliability as a fifth metric, based on how well user expectations are met, such as availability and performance. Other DORA metrics, such as Rework Rate, provide additional insight into system stability and quality. Rework Rate, introduced as a newer stability metric in 2024-2025, measures unplanned work compared to total deployments.
Defining what constitutes a deployment or a failure can be challenging across multiple systems, especially in organizations with legacy systems. Tracking DORA metrics requires integration across the DevOps toolchain for effective data collection, and organizations with legacy systems may face time-consuming manual processes.
With a clear understanding of the four key DORA metrics, let's examine how they impact continuous delivery and the benefits they bring to modern software development practices.
Continuous Delivery allows more frequent releases, enabling new features, improvements, and bug fixes to be delivered to end-users more quickly. Elite performers aim for continuous deployment, with elite teams deploying code multiple times per day and achieving Lead Time for Changes in less than one hour. Elite DevOps teams achieve this through mature CI/CD pipelines. Deployment frequency can vary on a team-by-team basis, with some teams releasing multiple times daily and others less frequently. This provides a competitive advantage by keeping the product up-to-date and responsive to user needs, enhancing customer satisfaction.
Quality assurance practices, such as automated testing and staging, play a crucial role in improving reliability by catching bugs and issues early. Automated testing and consistent deployment processes not only improve the overall quality and reliability of the software but also reduce the chances of defects reaching production. A high change failure rate signals problems with code quality or insufficient testing, highlighting the importance of robust quality assurance. Tracking how much developer time is spent on non-value-adding tasks can help identify inefficiencies and reduce failure-related disruptions.
When updates are smaller and more frequent, especially in the context of production deployment, it reduces the complexity and risk associated with each deployment. Smaller, more frequent production deployments help minimize the potential impact of any single change. If an issue does arise, it becomes easier to pinpoint the problem and roll back the changes. Monitoring for production failures and implementing automated testing can further reduce the risk of failed deployments, ensuring that issues are caught early before reaching the live environment.
CD practices can be scaled to accommodate growing development teams and more complex applications. It helps to manage the increasing demands of modern software development.
Continuous delivery allows teams to experiment with new ideas and features efficiently. This encourages innovation by allowing quick feedback and iteration cycles.
Establishing baselines for DORA metrics is crucial for measuring improvement over time.
Implementing DORA metrics encourages teams to streamline their processes, reducing bottlenecks and inefficiencies in the delivery pipeline. Tracking teams' cycle time helps assess delivery velocity and identify workflow bottlenecks, providing clear insights into how long it takes for code changes to move from commit to production. As teams' DORA metrics improve, value stream management and overall efficiency increase, enabling cross-functional teams to deliver value to customers more effectively. Organizations can track the flow of value through value stream management, using DORA metrics to identify precise bottlenecks and track the impact of DevOps investments. It also allows the team to regularly measure and analyze these metrics, fostering a culture of continuous improvement. As a result, teams are motivated to identify and resolve inefficiencies.
Tracking DORA metrics encourages collaboration between DevOps and other stakeholders, fostering a more integrated and cooperative approach to software delivery. It further provides objective data that teams can use to make informed decisions, prioritize work, and align their efforts with business goals.
Continuous Delivery relies heavily on automated testing to catch defects early. DORA metrics help software teams track the testing processes' effectiveness, ensuring higher software quality. Faster deployment cycles and lower lead times enable quicker feedback from end-users, allowing software development teams to address issues and improve the product more swiftly.
Reliability and stability are two critical aspects of software delivery measured by DORA metrics. Software teams can ensure that their deployments are more reliable and less prone to issues by monitoring and aiming to reduce the change failure rate. A low MTTR demonstrates a team’s capability to quickly recover from failures, minimizing downtime and its impact on users. High-performing teams that excel in DORA metrics do not sacrifice stability for speed, but balance both for optimal results. Hence, this increases the reliability and stability of the software.
Incident management is an integral part of CD as it helps quickly address and resolve any issues that arise. This aligns with the DORA metric for Time to Restore Service as it ensures that any disruptions are quickly addressed, minimizing downtime, and maintaining service reliability.
With a comprehensive understanding of the benefits, let's now explore the potential drawbacks and challenges associated with implementing DORA metrics for continuous delivery.
The process of setting up the necessary software to measure DORA metrics accurately can be complex and time-consuming. Inaccurate or incomplete data can lead to misleading metrics, which can affect decision-making and process improvements.
Implementing and maintaining the necessary infrastructure to track DORA metrics can be resource-intensive. It potentially diverts resources from other important areas and increases the risk of disproportionately allocating resources to high-performing teams or projects to improve metrics.
DORA metrics focus on specific aspects of the delivery process and may not capture other crucial factors including security, compliance, or user satisfaction. Including other DORA metrics, such as reliability and rework rate, can provide a more comprehensive understanding of DevOps performance by capturing additional dimensions like system stability and quality. It is also not universally applicable as the relevance and effectiveness of DORA metrics can vary across different types of projects, teams, and organizations. What works well for one team may not be suitable for another.
Implementing DORA DevOps metrics requires changes in culture and mindset, which can be met with resistance from teams that are accustomed to traditional methods. Engineering and DevOps leaders play a crucial role in communicating that DORA metrics are intended to improve team performance, not to evaluate individuals. Ensuring that DORA metrics align with broader business goals and are understood by all stakeholders can also be challenging.
While DORA Metrics are quantitative in nature, their interpretation and application can be highly subjective. The definition and measurement of metrics like ‘Lead Time for Changes' or ‘MTTR' can vary significantly across teams, resulting in inconsistencies in how these metrics are understood and applied.
Understanding these challenges is essential for successful adoption. Next, we’ll discuss best practices to maximize the value of DORA metrics in your organization.
Implementing DORA metrics transforms how organizations approach software delivery performance and drives continuous improvement across the entire software delivery ecosystem. By leveraging these powerful metrics, teams unlock unprecedented insights into their development workflows and operational efficiency.
Let's explore the essential best practices that maximize the impact of DORA metrics and revolutionize your software delivery approach.
Organizations that consistently measure deployment frequency, lead time for changes, change failure rate, and time to restore service gain a comprehensive understanding of their software delivery capabilities. This holistic approach enables engineering teams to identify patterns, correlations, and opportunities that single-metric monitoring simply cannot reveal. Teams discover that monitoring all four key metrics creates a balanced scorecard that illuminates both velocity and stability aspects of their delivery process, fostering data-driven decision making across the entire development lifecycle.
Successful teams analyze their performance against industry benchmarks to establish achievable yet ambitious targets that motivate development teams. This strategic approach ensures that organizations maintain focus on continuous improvement while avoiding unrealistic expectations that can demoralize teams. By comparing against high-performing organizations and elite performers, teams understand where they stand in the industry landscape and create roadmaps for achieving superior software delivery throughput and reliability.
Advanced analysis of DORA metrics uncovers bottlenecks in the development process that traditional monitoring approaches often miss. When teams dive deep into their metrics, they identify specific stages where delays accumulate, failures cluster, or inefficiencies persist. This analytical approach supports development teams in optimizing workflows by addressing root causes rather than symptoms, ultimately increasing overall delivery performance and reducing waste throughout the value stream.
Teams that regularly review DORA metrics track progress, identify emerging trends, and make informed, data-driven decisions that keep them ahead of potential issues. This ongoing review process helps DevOps teams maintain agility and responsiveness, enabling them to adjust strategies proactively rather than reactively. Organizations discover that consistent metric review creates a rhythm of improvement that becomes embedded in their culture, fostering continuous learning and adaptation.
High-performing teams understand that deployment frequency and lead time for changes must harmonize with production stability metrics to achieve sustainable success. These organizations prioritize both velocity and reliability, ensuring that their pursuit of speed never compromises software quality or customer experience. Teams learn that balancing these aspects requires sophisticated monitoring, automated testing, and robust deployment practices that support rapid, reliable software delivery without sacrificing system stability.
Forward-thinking organizations encourage engineering leaders and teams to use DORA metrics as a foundation for ongoing enhancement and innovation. This cultural transformation involves fostering an environment that values experimentation, learning from failures, and celebrating incremental improvements. Teams discover that when DORA metrics become part of their improvement DNA, they naturally drive organizational performance and innovation through iterative enhancement and knowledge sharing.
Organizations leverage DORA metrics to inform strategic value stream management decisions that optimize the entire software delivery pipeline. This integration ensures that teams focus on delivering software that meets customer needs efficiently while maintaining operational excellence. By analyzing the complete value stream through the lens of DORA metrics, organizations identify opportunities to streamline processes, reduce waste, and accelerate value delivery to end users.
Robust monitoring tools that automatically collect and analyze DORA metrics eliminate manual effort while providing real-time insights that empower teams to focus on improvement rather than data gathering. Automation ensures consistency, accuracy, and timeliness in metric collection, enabling teams to respond quickly to emerging patterns or issues. Organizations discover that automated DORA metric collection creates a foundation for advanced analytics, machine learning applications, and predictive insights that enhance decision-making capabilities.
Successful organizations recognize that engineering teams define success differently based on their unique contexts, goals, and constraints. Tailoring DORA metrics to align with each team's specific objectives makes the metrics relevant and actionable for diverse engineering and DevOps teams. This customized approach ensures that metrics drive meaningful improvements rather than creating one-size-fits-all solutions that may not address individual team needs or circumstances.
Teams understand that DORA metrics support development teams and foster collaboration rather than evaluating individual performance. Focusing on team-level metrics encourages knowledge sharing, collective problem-solving, and continuous improvement across multiple teams and systems. Organizations that embrace this philosophy create environments where DORA metrics become tools for empowerment and growth rather than instruments of judgment or comparison.
By implementing these comprehensive best practices, organizations harness the transformative potential of DORA metrics to enhance software delivery performance, optimize DevOps capabilities, and cultivate a thriving culture of continuous improvement throughout their entire software development lifecycle. Teams discover that DORA metrics become catalysts for organizational transformation, driving innovation and excellence across all aspects of software delivery.
With best practices in mind, let's look at how Typo can help organizations overcome the limitations of DORA metrics and achieve even greater software delivery outcomes.
As the tech landscape is evolving, there is a need for diverse evaluation tools in software development. Relying solely on DORA metrics can result in a narrow understanding of performance and progress. Hence, software development organizations necessitate a multifaceted evaluation approach.
And that’s why, Typo is here at your rescue!
Typo is an effective software engineering intelligence platform that offers SDLC visibility, developer insights, and workflow automation to build better programs faster. It can seamlessly integrate into tech tool stacks such as GIT versioning, issue tracker, and CI/CD tools. It also offers comprehensive insights into the deployment process through key metrics such as change failure rate, time to build, and deployment frequency. Its automated code tool helps identify issues in the code and auto-fixes them before you merge to master.


While DORA metrics offer valuable insights into software delivery performance, they have their limitations. Typo provides a robust platform that complements DORA metrics by offering deeper insights into developer productivity and workflow efficiency, helping engineering teams achieve the best possible software delivery outcomes.

DevOps and Platform Engineering are complementary approaches to modern software delivery. DevOps focuses on cultural shifts and collaboration between development and IT operations teams to improve release speed and quality, emphasizing shared responsibility and streamlined communication. In contrast, platform engineering builds internal platforms—known as Internal Developer Platforms (IDPs)—for developer self-service, treating the platform as an internal product with developers as its customers. This foundational difference means DevOps is about how teams work together, while platform engineering is about providing the tools and environments that empower those teams.
For software engineers, IT professionals, platform engineers, DevOps teams, and leaders shaping delivery practices, this article defines both disciplines and compares their principles, technical foundations, architectures, toolchains, workflows, and operational impact. Understanding where they overlap and where they differ helps organizations improve software quality, delivery speed, and day-to-day developer experience as engineering demands continue to evolve.
DevOps is a cultural and technical movement aimed at unifying software development (Dev) and IT operations (Ops) to improve collaboration, streamline processes, and enhance the speed and quality of software delivery. The primary goal of DevOps is to create a more cohesive, continuous workflow from development through to production. DevOps focuses on cultural shifts and collaboration between teams, breaking down silos and fostering a shared sense of ownership across the software lifecycle.
Platform engineering is the practice of designing and building toolchains and workflows that enable self-service capabilities for software engineering organizations in the cloud-native era. Platform engineering focuses on reducing cognitive load for developers by creating an internal developer platform (IDP).
Internal Developer Platform (IDP) Defined:
An Internal Developer Platform (IDP) is an internal product built by platform engineering teams to simplify development processes. The IDP provides standardized environments, tools, and services that developers can access through self-service interfaces. By treating the platform as an internal product and developers as its customers, platform engineering ensures that the platform evolves to meet developer needs, reduces friction, and increases productivity. In essence, platform engineering builds internal platforms for developer self-service, making it easier for teams to build, test, and deploy software efficiently.

By 2026, 80% of large organizations are expected to have platform engineering teams. In platform engineering vs. DevOps, DevOps is the delivery culture, while platform engineering provides the enabling platform layer.

Site reliability engineering extends reliability engineering with automation and monitoring for production systems. It also brings site reliability to devops and platform engineering by keeping underlying infrastructure and services dependable, and its success often depends on the human side of DevOps and aligned team goals.

A platform team builds internal platforms and a central platform, abstracting infrastructure complexity for developers. A robust platform also helps standardize production environments across engineering teams.

Platform engineering tools and automation tools sit in the technology layer to support DevOps workflows across teams. That layer often includes container orchestration on cloud platforms to standardize deployment and operations, drawing on a range of top platform engineering tools. Developer portals and service catalogs give software developers self-service access to cloud resources and performance metrics.

Platform engineering streamlines DevOps workflows with a self-service platform that gives teams reusable tooling and infrastructure. It also creates golden paths so common setup and deployment work stays consistent and fast. An internal developer portal, or a self-service portal, helps teams deliver software faster across the software development lifecycle and the entire software development lifecycle. Key benefits include:

The platform engineering approach increases business value with streamlined workflows and improved reliability, particularly when combined with top developer experience tools that enhance day-to-day workflows.
A platform team treats development and operations groups as internal customers, and user research helps a dedicated platform engineering team align platform engineering work with the primary focus of the IT organization and the entire organization.
While DevOps teams and DevOps engineers apply DevOps practices across the development process, teams focus differently:
DevOps and Platform Engineering offer different yet complementary approaches to enhancing software development and delivery. DevOps focuses on cultural integration and automation, while Platform Engineering emphasizes providing a robust, scalable infrastructure platform. By understanding these technical distinctions, organizations can make informed decisions to optimize their software development processes and achieve their operational goals.

Platform engineering is a relatively new and evolving field in the tech industry. While it offers many opportunities, certain aspects are often overlooked.
In this blog, we discuss effective strategies for becoming a successful platform engineer and identify common pitfalls to avoid.
Platform Engineering, an emerging technology approach, enables the software engineering team with all the required resources. This is to help them perform end-to-end operations of software development lifecycle automation. The goal is to reduce overall cognitive load, enhance operational efficiency, and remove process bottlenecks by providing a reliable and scalable platform for building, deploying, and managing applications.
One important tip to becoming a great platform engineer is informing the entire engineering organization about platform team initiatives. This fosters transparency, alignment, and cross-team collaboration, ensuring everyone is on the same page. When everyone is aware of what’s happening in the platform team, it allows them to plan tasks effectively, offer feedback, raise concerns early, and minimize duplication of efforts. As a result, providing everyone a shared understanding of the platform, goals, and challenges.
When everyone on the platform engineering team has varied skill sets, it brings a variety of perspectives and expertise to the table. This further helps in solving problems creatively and approaching challenges from multiple angles.
It also lets the team handle a wide range of tasks such as architecture design and maintenance effectively. Furthermore, team members can also learn from each other (and so do you!) which helps in better collaboration and understanding and addressing user needs comprehensively.
Pull Requests and code reviews, when done manually, take a lot of the team’s time and effort. Hence, this gives you an important reason why to use automation tools. Moreover, it allows you to focus on more strategic and high-value tasks and lets you handle an increased workload. This further helps in accelerating development cycles and time to market for new features and updates which optimizes resource utilization and reduces operational costs over time.
Platform engineering isn’t all about building the underlying tools, it also signifies maintaining a DevOps culture. You must partner with development, security, and operations teams to improve efficiency and performance. This allows for having the right conversation for discovering bottlenecks, and flexibility in tool choices, and reinforces positive collaboration among teams.
Moreover, it encourages a feedback-driven culture, where teams can continuously learn and improve. As a result, aligning the team’s efforts closely with customer requirements and business objectives.
To be a successful platform engineer, it's important to stay current with the latest trends and technologies. Attending tech workshops, webinars, and conferences is an excellent way to keep up with industry developments. besides these offline methods, you can read blogs, follow tech influencers, listen to podcasts, and join online discussions to improve your knowledge and stay ahead of industry trends.
Moreover, collaborating with a team that possesses diverse skill sets can help you identify areas that require upskilling and introduce you to new tools, frameworks, and best practices. This combined approach enables you to better anticipate and meet customer needs and expectations.
Beyond DevOps metrics, consider factors like security improvements, cost optimization, and consistency across the organization. This holistic approach prevents overemphasis on a single area and helps identify potential risks and issues that might be overlooked when focusing solely on individual metrics. Additionally, it highlights areas for improvement and drives ongoing optimized efficiencies across all dimensions of the platform.
First things first, understand who your customers are. When platform teams prioritize features or improvements that don't meet software developers' needs, it negatively impacts their user experience. This can lead to poor user interfaces, inadequate documentation, and missing functionalities, directly affecting customers' productivity.
Therefore, it's essential to identify the target audience, understand their key requirements, and align with their requests. Ignoring this in the long run can result in low usage rates and a gradual erosion of customer trust.
One of the common mistakes that platform engineers make is not giving engineering teams enough tooling or ownership. This makes it difficult for them to diagnose and fix issues in their code. It increases the likelihood of errors and downtime as teams may struggle to thoroughly test and monitor code. Not only this, they may also struggle to spend more time on manual processes and troubleshooting which slows down the development time cycle.
Hence, it is always advisable to provide your team with enough tooling. Discuss with them what tooling they need, whether the existing ones are working fine, and what requirements they have.
When a lot of time is spent on planning, it results in analysis paralysis i.e. thinking too much of potential features and improvements rather than implementation and testing. This further results in delays in deliveries, hence, slowing down the development process and feedback loops.
Early and frequent shipping creates the right feedback loops that can enhance the user experience and improve the platform continuously. These feature releases must be prioritized based on how often certain deployment proceedings are performed. Make sure to involve the software developers as well to discover more effective solutions.
The documentation process is often underestimated. Platform engineers believe that the process is self-explanatory but this isn’t true. Everything around code, feature releases, and related to the platform must be comprehensively documented. This is critical for onboarding, troubleshooting, and knowledge transfer.
Well-written documents also help in establishing and maintaining consistent practices and standards across the team. It also allows an understanding of the system’s architecture, dependencies, and known issues.
Platform engineers must take full ownership of security issues. Lack of accountability can result in increased security risks and vulnerabilities specific to the platform. The limited understanding of unique risks and vulnerabilities can affect the system.
But that doesn’t mean that platform engineers must stop using third-party tools. They must leverage them however, they need to be complemented by internal processes or knowledge and need to be integrated into the design, development, and deployment phases of platform engineering.
Typo is an effective platform engineering tool that offers SDLC visibility, developer insights, and workflow automation to build better programs faster. It can seamlessly integrate into tech tool stacks such as GIT versioning, issue tracker, and CI/CD tools.
It also offers comprehensive insights into the deployment process through key metrics such as change failure rate, time to build, and deployment frequency. Moreover, its automated code tool helps identify issues in the code and auto-fixes them before you merge to master.
Typo has an effective sprint analysis feature that tracks and analyzes the team’s progress throughout a sprint. Besides this, It also provides 360 views of the developer experience i.e. captures qualitative insights and provides an in-depth view of the real issues.
Implementing these strategies will improve your success as a platform engineer. By prioritizing transparency, diverse skill sets, automation, and a DevOps culture, you can build a robust platform that meets evolving needs efficiently. Staying updated with industry trends and taking a holistic approach to success metrics ensures continuous improvement.
Ensure to avoid the common pitfalls as well. By addressing these challenges, you create a responsive, secure, and innovative platform environment.
Hope this helps. All the best! :)

Efficiency is a fundamental aspect of successful software development, influencing productivity, cost-effectiveness, and customer satisfaction. DORA Metrics and the SPACE framework are leading developer productivity frameworks, widely recognized for measuring and improving developer productivity. These frameworks serve as standardized benchmarks to assess and enhance software delivery performance across various dimensions.
The SPACE framework evaluates software development teams across five dimensions: Satisfaction and well-being, Performance, Activity, Communication and collaboration, and Efficiency and flow. By leveraging these five dimensions, organizations gain a holistic view of team productivity that goes beyond traditional activity metrics. Both DORA and SPACE frameworks help organizations track progress and identify bottlenecks in the software development process, enabling continuous improvement and more effective workflow management.
This paper aims to explore the quantitative impact of these developer productivity frameworks on SPACE efficiency and their correlation with key business metrics, providing insights into how organizations can optimize their software development process for competitive advantage. Delivering high-quality software is a key outcome of using these frameworks. Both DORA metrics and the SPACE framework are evidence-based approaches grounded in research, focusing on continuous improvement and outcomes over individual performance.
Previous research has highlighted the significance of DORA Metrics in improving software delivery performance and organizational agility (Forsgren et al., 2020). Industry reports such as the State of DevOps Report provide valuable insights into software delivery performance, helping organizations benchmark and enhance their processes. However, many engineering leaders face challenges in adopting and implementing these frameworks due to their complexity and the expertise required.
A comprehensive analysis should include measuring productivity at different organizational levels, as the SPACE framework suggests selecting separate metrics for each level to obtain a complete view of organizational performance and identify specific areas for improvement. Detailed empirical studies demonstrating the specific impact of these frameworks on SPACE efficiency and business metrics remain limited, warranting further evaluation and calculation-based research. A deeper understanding of both technical and human factors is necessary for effective measurement.
Operational performance is a crucial aspect of software delivery success, as high software delivery performance alone is insufficient without strong system reliability and stability. The SPACE framework helps identify the root causes of low performance and the best actions to improve, ensuring organizations can address both delivery and operational challenges effectively.
Selection Criteria: A leading SaaS company based in the US, was chosen for this case study due to its scale and complexity in software development operations. With over 120 engineers distributed across various teams, the customer faced challenges related to deployment efficiency, reliability, and customer satisfaction.
Data Collection: Utilized the customer’s internal metrics and tools, including deployment logs, incident reports, customer feedback surveys, and performance dashboards. The team deploys code as part of their regular DevOps practices, emphasizing continuous integration and frequent deployment to improve delivery performance. The study focused on a period of 12 months to capture seasonal variations and long-term trends in software delivery performance.
Contextual Insights: Gathered qualitative insights through interviews with the customer’s development and operations teams. These interviews provided valuable context on existing challenges, process bottlenecks, and strategic goals for improving software delivery efficiency.
Deployment Frequency: Calculated as the number of deployments per unit time (e.g., per day).
Example: They increased their deployment frequency from 3 deployments per week to 15 deployments per week during the study period.
Calculation:

Insight: Higher deployment frequency facilitated faster feature delivery and responsiveness to market demands.
Lead Time for Changes: Measured from code commit to deployment completion.
Example: Lead time reduced from 7 days to 1 day due to process optimizations and automation efforts.
Calculation:

Insight: Shorter lead times enabled TYPO’s customer to swiftly adapt to customer feedback and market changes.
MTTR (Mean Time to Recover): Calculated as the average time taken to restore service after an incident.
Example: MTTR decreased from 4 hours to 30 minutes through improved incident response protocols and automated recovery mechanisms.
Calculation:

Insight: Reduced MTTR enhanced system reliability and minimized service disruptions.
Change Failure Rate: Determined by dividing the number of failed deployments by the total number of deployments.
Example: Change failure rate decreased from 8% to 1% due to enhanced testing protocols and deployment automation.

Insight: Lower change failure rate improved product stability and customer satisfaction.
Measuring individual and team performance has revolutionized how engineering leaders drive developer productivity and achieve breakthrough business objectives in today’s software development landscape. Both software engineering teams and software development teams benefit from these frameworks, as organizations seek to optimize their software delivery processes. Relying on traditional metrics—such as lines of code or commit counts—no longer delivers the comprehensive insights needed for peak performance. Instead, powerful frameworks like DORA metrics and the SPACE framework provide a transformative and actionable approach that reshapes how we understand developer effectiveness.
DORA metrics focus on four game-changing indicators: deployment frequency, lead time for changes, change failure rate, and time to restore service. These metrics empower engineering teams to track meaningful progress in their software delivery performance, pinpoint critical bottlenecks in development pipelines, and quantify the real impact of process improvements. By actively monitoring these essential metrics, engineering managers gain unprecedented insights into how efficiently their teams deploy code, respond to incidents, and deliver exceptional value to customers.
The SPACE framework complements DORA by delivering a comprehensive view of developer productivity across five crucial dimensions: satisfaction and well-being, performance, activity, communication and collaboration, and efficiency and flow. SPACE metrics help engineering leaders understand not just operational team performance, but also the fundamental aspects of developer experience that fuel long-term success—including psychological safety, job satisfaction, and dynamic knowledge sharing. This broader perspective enables organizations to cultivate a thriving culture of continuous improvement and exceptional software delivery.
To measure developer productivity effectively, engineering leaders must evaluate both individual and team contributions within the broader context of the entire development ecosystem. Organizations should actively encourage knowledge sharing, foster collaboration, and implement continuous integration practices that empower teams to innovate and adapt rapidly. Value stream mapping serves as a powerful analytical tool in this transformation, helping teams visualize their complete development pipeline, identify performance inefficiencies, and optimize work flow from initial concept to final deployment.
By strategically combining DORA and SPACE metrics, software engineering teams and software development teams can transcend traditional individual performance evaluation and focus on team effectiveness, operational excellence, and exceptional value delivery. This integrated approach supports continuous monitoring and improvement initiatives, enabling organizations to align their software development efforts with business outcomes and evolving customer needs while driving sustainable productivity gains. Leveraging these metrics fosters a culture of continuous improvement and shared responsibility among teams.
Revenue Growth: TYPO’s customer achieved a 25% increase in revenue attributed to faster time-to-market and improved customer satisfaction. A key insight from the analysis is that improvements in deployment frequency and lead time—two specific metrics from the DORA space metrics framework—were directly linked to these business outcomes.
Customer Satisfaction: Improved Net Promoter Score (NPS) from 8 to 9, indicating higher customer loyalty and retention rates.
Employee Productivity: Increased by 30% as teams spent less time on firefighting and more on innovation and feature development.
The findings from our customer case study illustrate a clear correlation between improved DORA Metrics, enhanced SPACE efficiency, and positive business outcomes. By optimizing Deployment Frequency, Lead Time for Changes, MTTR, and Change Failure Rate, organizations can achieve significant improvements in operational efficiency, customer satisfaction, and financial performance. These results contribute to a holistic view of engineering productivity by demonstrating how multiple dimensions—such as system metrics and developer experience—work together to drive success.
These results underscore the importance of data-driven decision-making and continuous improvement practices in software development. However, organizations should not focus solely on speed or output; instead, they should consider multiple dimensions of productivity, including collaboration, perception-based data, and context-specific factors, to ensure a comprehensive understanding of team performance.
Typo is an intelligent engineering management platform used for gaining visibility, removing blockers, and maximizing developer effectiveness. Typo’s user-friendly interface and cutting-edge capabilities set it apart in the competitive landscape. Users can tailor the DORA metrics dashboard to their specific needs, providing a personalized and efficient monitoring experience. It provides a user-friendly interface and integrates with DevOps tools to ensure a smooth data flow for accurate metric representation. The space framework offers a comprehensive approach to monitoring team effectiveness, and Typo also tracks code quality as part of its performance monitoring features.
In conclusion, leveraging DORA Metrics, especially when combined with the DORA and SPACE frameworks, within software development processes enables organisations to streamline operations, accelerate innovation, and maintain a competitive edge in the market. By aligning these metrics with business objectives and systematically improving their deployment practices, companies can achieve sustainable growth and strategic advantages. Future research should continue to explore the ongoing evolution of DevOps practices and their implications for optimizing software delivery performance.
Moving forward, Typo and similar organizations consider the following next steps based on the insights gained from this study:

Although we are somewhat late in presenting this summary, the insights from the 2023 State of DevOps Report remain highly relevant and valuable for the industry. The DevOps Research and Assessment (DORA) program has significantly influenced software development practices over the past decade. Each year, the State of DevOps Report provides a detailed analysis of the practices and capabilities that drive success in software delivery, offering benchmarks that teams can use to evaluate their own performance. This blog summarizes the key findings from the 2023 report, incorporates additional data and insights from industry developments, and introduces the role of the Software Engineering Institute (SEI) platform as highlighted by Gartner in 2024.

The 2023 State of DevOps Report draws from responses provided by over 36,000 professionals across various industries and organizational sizes. This year’s research emphasizes three primary outcomes:
Additionally, the report examines two key performance measures:
The 2023 report highlights the crucial role of culture in developing technical capabilities and driving performance. Teams with a generative culture — characterized by high levels of trust, autonomy, open information flow, and a focus on learning from failures rather than assigning blame — achieve, on average, 30% higher organizational performance. This type of culture is essential for fostering innovation, collaboration, and continuous improvement.
Building a successful organizational culture requires a combination of everyday practices and strategic leadership. Practitioners shape culture through their daily actions, promoting collaboration and trust. Transformational leadership is also vital, emphasizing the importance of a supportive environment that encourages experimentation and autonomy.
A significant finding in this year’s report is that a user-centric approach to software development is a strong predictor of organizational performance. Teams with a strong focus on user needs show 40% higher organizational performance and a 20% increase in job satisfaction. Leaders can foster an environment that prioritizes user value by creating incentive structures that reward teams for delivering meaningful user value rather than merely producing features.
An intriguing insight from the report is that the use of Generative AI, such as coding assistants, has not yet shown a significant impact on performance. This is likely because larger enterprises are slower to adopt emerging technologies. However, as adoption increases and more data becomes available, this trend is expected to evolve.
Investing in technical capabilities like continuous integration and delivery, trunk-based development, and loosely coupled architectures leads to substantial improvements in performance. For example, reducing code review times can improve software delivery performance by up to 50%. High-quality documentation further enhances these technical practices, with trunk-based development showing a 12.8x greater impact on organizational performance when supported by quality documentation.
Leveraging cloud platforms significantly enhances flexibility and, consequently, performance. Using a public cloud platform increases infrastructure flexibility by 22% compared to other environments. While multi-cloud strategies also improve flexibility, they can introduce complexity in managing governance, compliance, and risk. To maximize the benefits of cloud computing, organizations should modernize and refactor workloads to exploit the cloud’s flexibility rather than simply migrating existing infrastructure.
The report indicates that individuals from underrepresented groups, including women and those who self-describe their gender, experience higher levels of burnout and are more likely to engage in repetitive work. Implementing formal processes to distribute work evenly can help reduce burnout. However, further efforts are needed to extend these benefits to all underrepresented groups.
The Covid-19 pandemic has reshaped working arrangements, with many employees working remotely. About 33% of respondents in this year’s survey work exclusively from home, while 63% work from home more often than an office. Although there is no conclusive evidence that remote work impacts team or organizational performance, flexibility in work arrangements correlates with increased value delivered to users and improved employee well-being. This flexibility also applies to new hires, with no observable increase in performance linked to office-based onboarding.
The 2023 report highlights several key practices that are driving success in DevOps:
Implementing CI/CD pipelines is essential for automating the integration and delivery process. This practice allows teams to detect issues early, reduce integration problems, and deliver updates more frequently and reliably.
This approach involves developers integrating their changes into a shared trunk frequently, reducing the complexity of merging code and improving collaboration. Trunk-based development is linked to faster delivery cycles and higher quality outputs.
Designing systems as loosely coupled services or microservices helps teams develop, deploy, and scale components independently. This architecture enhances system resilience and flexibility, enabling faster and more reliable updates.
Automated testing is critical for maintaining high-quality code and ensuring that new changes do not introduce defects. This practice supports continuous delivery by providing immediate feedback on code quality.
Implementing robust monitoring and observability practices allows teams to gain insights into system performance and user behavior. These practices help in quickly identifying and resolving issues, improving system reliability and user satisfaction.
Using IaC enables teams to manage and provision infrastructure through code, making the process more efficient, repeatable, and less prone to human error. IaC practices contribute to faster, more consistent deployment of infrastructure resources.
Metrics are vital for guiding teams and driving continuous improvement. However, they should be used to inform and guide rather than set rigid targets, in accordance with Goodhart’s law. Here’s why metrics are crucial:
The Software Engineering Intelligence(SEI) platforms like Typo , as highlighted in Gartner’s research, plays a pivotal role in advancing DevOps practices. The SEI platform provides tools and frameworks that help organizations assess their software engineering capabilities and identify areas for improvement. This platform emphasizes the importance of integrating DevOps principles into the entire software development lifecycle, from initial planning to deployment and maintenance.
Gartner’s analysis indicates that organizations leveraging the SEI platform see significant improvements in their DevOps maturity, leading to enhanced performance, reduced time to market, and increased customer satisfaction. The platform’s comprehensive approach ensures that DevOps practices are not just implemented but are continuously optimized to meet evolving business needs.
The State of DevOps Report 2023 by DORA offers critical insights into the current state of DevOps, emphasizing the importance of culture, user focus, technical capabilities, cloud flexibility, and equitable work distribution.
For those interested in delving deeper into the State of DevOps Report 2023 and related topics, here are some recommended resources:
These resources provide extensive insights into DevOps principles and practices, offering practical guidance for organizations aiming to enhance their DevOps capabilities and achieve greater success in their software delivery processes.

Developed by Atlassian, JIRA is widely used by organizations across the world. Integrating it with Typo, an intelligence engineering platform, can help organizations gain deeper insights into the development process and make informed decisions.
In Scrum, the sprint review is a collaborative meeting and a key scrum event typically held at the end of each sprint. It is the second to last event—the last event before the sprint retrospective—in the Scrum process. According to the Scrum Guide, the sprint review serves as a working session where the agile team—including developers, the Scrum Master, Product Owner, and key stakeholders—attendees collaborate to inspect progress, showcase progress, and collect feedback on the product increment developed during the sprint. As a core part of the agile development process, the sprint review fosters adaptability, continuous improvement, and stakeholder collaboration to ensure the team is aligned and responsive to change.
The sprint review agenda includes having team members demonstrate their own work, with developers' work being central to achieving the sprint goal. During the session, the team discusses completed user stories, reviews how the completed work aligns with the sprint's work, and considers the product's potential capabilities for future releases. If any deliverables remain unfinished, partial progress is also reviewed. This approach fosters transparency, as stakeholders review the sprint's work and provide valuable input, which the Product Owner incorporates into the product backlog to determine future adaptations and inform the next sprint planning meeting.
The sprint review is timeboxed to a maximum of four hours for a one month sprint, with shorter sprints having proportionally shorter reviews. Unlike the sprint retrospective—which is a team-only event focused on improving agile practices—the sprint review is open to stakeholders, making it essential for driving an iterative feedback loop, effective sprint reviews, and the product’s success. The focus is on outcomes, business value, and the definition of done for each product increment, rather than just a status update. To avoid limiting the session to just presentations, teams are encouraged to facilitate open discussion and use business-friendly language, avoiding technical jargon to ensure stakeholder understanding. Celebrating small wins during the sprint review can boost team morale and reinforce the value of the work completed. By fostering transparency and encouraging open collaboration, teams can inspect progress, adapt to changing priorities, and plan upcoming sprints based on stakeholder feedback and the results of the previous sprint. This process helps ensure the team is moving in the right direction, supports continuous improvement, and contributes to the product's success.
Agile development represents a revolutionary, iteration-driven paradigm for architecting sophisticated software solutions that leverages adaptive methodologies, cross-functional collaboration, and perpetual optimization cycles. Anchored in the foundational principles of the Agile Manifesto, this transformative framework prioritizes human-centric interactions, functional software deliverables, stakeholder engagement protocols, and dynamic responsiveness to evolving requirements. Within the Agile development ecosystem, engineering teams operate through compressed, high-intensity iteration cycles designated as sprints. Each sprint culminates in a comprehensive sprint retrospective, where the scrum team demonstrates the implemented functionality and deliverables achieved during the sprint iteration to critical business stakeholders. This retrospective serves as a fundamental cornerstone of the Agile development pipeline, facilitating opportunities for teams to showcase operational software solutions, harvest strategic feedback inputs, and validate that project trajectories align with predetermined objectives. Through systematic evaluation of completed deliverables and continuous stakeholder feedback integration, Agile teams cultivate perpetual enhancement cycles and maintain development process synchronization with strategic business imperatives.
Launched in 2002, JIRA is a software development tool agile teams use to plan, track, and release software projects. This tool empowers them to move quickly while staying connected to business goals by managing tasks, bugs, and other issues. It supports multiple languages including English and French.
P.S: You can get JIRA from Atlassian Marketplace.
Integrate JIRA with Typo to get a detailed visualization of projects/sprints/bugs. It can be further synced with development teams' data to streamline and fasten delivery. Integrating also helps in enhancing productivity, efficiency, and decision-making capabilities for better project outcomes and overall organizational performance.
Below are a few benefits of integrating JIRA with Typo:
Within the Scrum framework, a comprehensive suite of structured ceremonies and artifacts streamlines Agile teams through each development cycle, delivering unprecedented transparency, alignment, and continuous optimization. The core Scrum ceremonies—Sprint Planning, Daily Scrum, Sprint Review, Sprint Retrospective, and the Sprint itself—create a transformative rhythm that enables teams to strategically plan, execute, inspect, and adapt their workflows with remarkable precision. Artifacts such as the Product Backlog, Sprint Backlog, and Increment function as the definitive sources of truth for work to be accomplished, work progressing, and deliverables completed, revolutionizing how teams manage their development pipeline.
The Sprint Review emerges as a pivotal ceremony where the entire scrum team showcases the work accomplished during the sprint to key stakeholders, reshaping collaborative engagement. This dynamic review cultivates open communication channels, empowering stakeholders to provide valuable feedback and thoroughly examine the product increment with enhanced clarity. The actionable insights captured during the sprint review drive future adaptations, optimize the product backlog, and strategically inform the upcoming sprint planning session. By making the review laser-focused on outcomes and business value delivery, teams can ensure that their development process remains transparent and perfectly aligned with organizational objectives. Effective sprint reviews are absolutely essential for accelerating continuous improvement and guaranteeing the product's long-term success in the marketplace.
Leveraging the Agile development framework, the Product Owner facilitates value optimization through strategic backlog stewardship and stakeholder alignment. Acting as the primary architect of product prioritization, the Product Owner analyzes user stories and feature sets based on business impact metrics, customer requirements analysis, and strategic roadmap objectives. Throughout sprint review cycles, the Product Owner drives progress discussions toward product goal achievement, ensuring development team deliverables align with stakeholder expectations and performance benchmarks. By actively facilitating cross-functional collaboration between stakeholders and development teams during review sessions, the Product Owner captures critical feedback data that optimizes future sprint planning cycles and enhances product backlog refinement processes. This iterative engagement methodology ensures the development workflow remains strategically focused on value delivery while adapting to evolving requirement specifications and market dynamics.
The best part about JIRA is that it is highly flexible. Hence, it doesn't require any additional change to the configuration or existing workflow:
Incidents refer to unexpected events or disruptions that occur during the development process or within the software application. These incidents can include system failures, bugs, errors, outages, security breaches, or any other issues that negatively impact the development workflow or user experience.

A few JIRA best practices:
The Sprint analysis feature allows you to track and analyze your team's progress throughout a sprint. It uses data from Git and issue management tool to provide insights into how your team is working. You can see how long tasks are taking, how often they're being blocked, and where bottlenecks are occurring.

A few JIRA best practices are:
It reflects the measure of Planned vs Completed tasks in the given period. For a given time range, Typo considers the total number of issues created and assigned to the members of the selected team in the ‘To Do' state and divides them by the total number of issues completed out of them in the ‘Done' state.
A few JIRA best practices are:
The inspect and adapt methodology represents a fundamental architectural component within the Scrum framework ecosystem, enabling Agile development teams to optimize performance and deliver value in rapidly evolving technological landscapes. During sprint review ceremonies, the scrum team collaborates with key stakeholders to systematically evaluate the latest product increment, leveraging comprehensive feedback mechanisms and real-time data analysis to adapt strategic roadmaps based on emerging requirements, market intelligence, and evolving business priorities. This continuous feedback optimization loop serves as a critical quality assurance mechanism that ensures development efforts maintain precise alignment with stakeholder expectations and dynamic market conditions while facilitating data-driven decision-making processes.
Through strategic implementation of the inspect and adapt paradigm, development teams can efficiently identify performance bottlenecks, proactively address technical debt before it escalates into critical issues, and dynamically reprioritize feature backlogs to maximize business value delivery. This methodology not only ensures the deployment of robust, functional software solutions that address authentic user requirements but also strengthens collaborative partnerships between cross-functional teams and organizational stakeholders through enhanced communication protocols and shared accountability frameworks. Ultimately, the inspect and adapt process optimization during sprint review cycles drives sustainable product success metrics and supports the continuous evolution of development methodologies, creating a self-improving ecosystem that adapts to technological advancements and organizational growth patterns.
Leveraging effective collaboration methodologies and implementing transparent communication frameworks constitutes the foundational architecture for high-performing Agile development ecosystems. The comprehensive scrum framework—encompassing the cross-functional development team, Product Owner stakeholder, and Scrum Master facilitator—operates synergistically to optimize sprint deliverable achievement through strategic alignment and coordinated execution. The sprint review ceremony serves as a pivotal collaborative touchpoint where the development team demonstrates completed user stories and functional increments to key stakeholders while systematically gathering actionable feedback for iterative enhancement. The Scrum Master orchestrates and facilitates these sprint review sessions, ensuring discussion transparency and implementing inclusive participation protocols that amplify diverse stakeholder perspectives across the review process. Through the cultivation of an open communication ecosystem, the scrum team can rapidly identify and address impediments, establish priority alignment matrices, and ensure unified progression toward shared sprint objectives and product vision. This collaborative methodology not only optimizes the quality and value of delivered increments but also strengthens stakeholder engagement and reinforces the symbiotic relationship between cross-functional teams and business stakeholders throughout the development lifecycle.
Real-time dashboards and comprehensive reporting frameworks constitute transformative technological solutions for Agile development teams seeking to optimize the efficacy and strategic impact of their sprint review methodologies. Through the strategic implementation of advanced analytics platforms such as Typo, development teams can systematically demonstrate progression toward predefined sprint objectives, showcase completed deliverables with comprehensive traceability, and facilitate stakeholder feedback collection mechanisms—all orchestrated through transparent, data-driven operational frameworks. These sophisticated dashboard architectures provide instantaneous visibility into development workflow processes, enabling teams to systematically track progression metrics, identify operational bottlenecks with precision, and effectively highlight achievement milestones across development cycles.
Throughout the sprint review execution phase, real-time reporting capabilities empower development teams to present current, accurate project intelligence, substantially reducing dependencies on manual status update procedures while ensuring that collaborative discussions are anchored in verified, precise data analytics. This comprehensive transparency framework not only facilitates the systematic collection of actionable stakeholder feedback but also serves as a foundational element for informing future adaptation strategies and supporting continuous improvement methodologies across development lifecycles. Through the strategic integration of real-time dashboard technologies into sprint review processes, development teams can effectively streamline operational workflows while maintaining focused delivery of high-quality software products that systematically align with stakeholder requirements and organizational objectives.
AI-driven automation tools for sprint review documentation have fundamentally transformed how agile teams capture, analyze, and leverage meeting insights throughout the software development lifecycle. These sophisticated systems seamlessly extract key discussion points, critical decisions, and actionable next steps through natural language processing and machine learning algorithms, ensuring comprehensive coverage and eliminating human oversight gaps. By implementing intelligent documentation workflows, development teams can significantly reduce administrative overhead while optimizing their focus on high-value activities such as stakeholder engagement, feedback analysis, and iterative improvement strategies during sprint review sessions.
Machine learning-enhanced tracking systems for action items and follow-up activities enable teams to establish robust accountability frameworks while streamlining progress monitoring and blocker resolution processes. These AI-powered platforms analyze historical sprint data to predict potential bottlenecks, recommend optimal resource allocation strategies, and facilitate data-driven adaptation decisions that enhance overall project velocity. Furthermore, automated documentation systems create comprehensive audit trails that support retrospective analysis, performance benchmarking, and continuous process optimization, ultimately establishing a foundation for sustainable agile practices that drive organizational efficiency and deliver superior software development outcomes.
Streamlined backlog prioritization fundamentally transforms how scrum teams deliver maximum value to stakeholders by revolutionizing the entire development workflow. Throughout the sprint review process, the product owner strategically orchestrates comprehensive discussions around the current product backlog state, systematically incorporating diverse stakeholder feedback and emerging insights to dynamically refine and optimize priorities. Through the strategic implementation of automated tools and sophisticated real-time dashboards, development teams can dramatically enhance the prioritization workflow, eliminate resource-intensive manual processes, and maintain seamless alignment between the evolving backlog and rapidly changing business objectives.
Optimized backlog prioritization empowers scrum teams to concentrate their development efforts on delivering robust, functional software that systematically addresses the most critical priority items, ensuring that valuable stakeholder feedback undergoes rapid transformation into concrete, actionable development initiatives. This comprehensive approach not only strengthens the product owner's capacity for making strategic, data-driven decisions but also maintains team cohesion and sustained motivation across all development phases. By continuously optimizing and refining the product backlog through systematic analysis of sprint review outcomes and performance metrics, teams can seamlessly adapt to market changes, deliver exponentially greater value propositions, and accelerate the product's trajectory toward sustained long-term success in competitive environments.
Below are other common JIRA best practices that you and your development team must follow:
Follow the steps mentioned below:
Typo dashboard > Settings > Dev Analytics > Integrations > Click on JIRA
Give access to your Atlassian account
Select the projects you want to give access to Typo or select all the projects to get insights into all the projects & teams in one go.
And it's done! Get all your sprint and issue-related insights in your dashboard now.
As enterprises expand their digital transformation initiatives, scaling Agile methodologies becomes critical to maintain operational efficiency and strategic alignment across distributed development teams. The Scrum framework provides a robust foundation for enterprise-scale implementations, with AI-enhanced practices such as sprint review optimization, sprint retrospective analytics, and daily Scrum automation enabling teams to inspect and adapt throughout iterative development cycles. In a scaled Agile environment, each development team conducts its own sprint review sessions, but cross-functional coordination mechanisms ensure that all stakeholders remain synchronized and aligned on delivery pipelines and strategic objectives. This approach supports continuous improvement methodologies and helps teams respond dynamically to evolving business requirements and market trajectories. By leveraging the core principles of the Scrum framework and maintaining focus on collaborative workflows and transparency protocols, organizations can scale Agile practices to deliver consistent value streams, even as team topologies and project complexity matrices increase exponentially.
Implement these best practices to streamline Jira usage, and improve development processes, and engineering operations. These can further help teams achieve better results in their software development endeavors.

Sprint Review Meetings are a cornerstone of Agile and Scrum methodologies, serving as a crucial touchpoint for teams to showcase their progress, gather feedback, and align on the next steps. A sprint review is a working session held at the end of each sprint, providing an opportunity to evaluate progress and plan ahead. However, many teams struggle to make the most of these meetings. This blog will explore how to enhance your Sprint Review Meetings to ensure they are effective, engaging, and productive.
The Sprint Review Meetings are meant to evaluate the progress made during a sprint, review the completed work, collect stakeholder feedback, and discuss the upcoming sprints. The purpose of the sprint is to deliver value and achieve specific goals, and understanding the intended purpose of the Sprint Review helps align the team and stakeholders toward maximizing product value. Sprint reviews help ensure that short-term work is still serving the bigger product vision, keeping the team aligned with long-term objectives. Setting clear expectations for the meeting ensures that all participants understand what is to be achieved and helps keep the discussion focused. Key participants include the Scrum team, the Product Owner, key stakeholders, senior stakeholders—whose involvement is valuable because they can provide strategic feedback and influence project direction—and occasionally the Scrum Master. It is important to explain the objectives and expectations at the start of the meeting so everyone is aligned.
It’s important to differentiate Sprint Reviews from Sprint Retrospectives. While the former focuses on what was achieved and gathering feedback, the latter centers on process improvements and team dynamics.
Preparation can make or break a Sprint Review Meeting. Ensuring that the team is ready involves several steps. Holding a dry run or practice session before the actual sprint review can help ensure that everything runs smoothly and all participants are comfortable with their roles during the meeting.
Encouraging direct collaboration between stakeholders and teams is essential for the success of any project. Fostering interactive conversations and stakeholder engagement ensures that all perspectives are heard and valued throughout the process.
This means avoiding the use of excessive technical jargon, which can make non-technical stakeholders feel excluded. Instead, strive to facilitate clear and transparent communication that allows all voices to be heard and valued. Discussing outcomes and product performance through collaborative conversation helps drive continuous improvement. Providing a platform for open and honest feedback will ensure that everyone’s perspectives are considered, leading to a more inclusive and effective collaborative process.
It is crucial to have a clearly defined agenda for a productive Sprint Review. This includes sharing the agenda well in advance of the meeting, and clearly outlining the main topics of discussion. Clarifying expectations for the meeting at this stage helps ensure all participants are aligned and understand the objectives. Setting clear expectations and time boxes for each segment of the sprint review helps keep discussions focused and prevents the meeting from running overtime. It’s also important to allocate specific time slots for each segment of the meeting to ensure that the review remains efficient.
The agenda should include discussions on completed work, work that was not completed, and the next steps to be taken. It should also cover reviewing progress and providing a clear overview of the product's status to enhance transparency and stakeholder understanding. Discussing challenges and risks transparently during sprint reviews allows stakeholders to understand the team's landscape and how they can assist. This level of detail and structure helps to ensure that the Sprint Review is focused and productive.
When you present completed work, it’s important to ensure that the demonstration is engaging and interactive. To achieve this, consider the following best practices:
By following these best practices, you can ensure that the demonstration of completed work is not only informative but also compelling and impactful for stakeholders.
Effective feedback collection is crucial for continuous improvement:
The Sprint Review Meeting is an important collaborative meeting where team members, engineering leaders, and stakeholders can review previous and discuss key pointers. Below are a few questions that need to be asked during this review meeting:
Use collaborative tools to improve the review process:
Using collaborative tools can also save time by streamlining the review process and making it easier for everyone to participate and stay informed.
Typo is a collaborative tool designed to enhance the efficiency and effectiveness of team meetings, including Sprint Review Meetings. The review becomes a working session that benefits from real-time data. Our sprint analysis feature uses data from Git and issue management tools to provide insights into how your team is working. You can see how long tasks take, how often they’re blocked, and where bottlenecks occur. It allows to track and analyze the team’s progress throughout a sprint and provides valuable insights into work progress, work breakup, team velocity, developer workload, and issue cycle time. This information can help you identify areas for improvement and ensure your team is on track to meet their goals.
Teams can adapt their use of tools and processes based on feedback and evolving needs to continuously improve the sprint review process.
Work progress represents the percentage breakdown of issue tickets or story points in the selected sprint according to their current workflow status.
Planning Accuracy measures how closely a sprint follows its original plan. It reflects the percentage of story points or issues that were planned before the sprint began versus those that were added or removed after the sprint started.
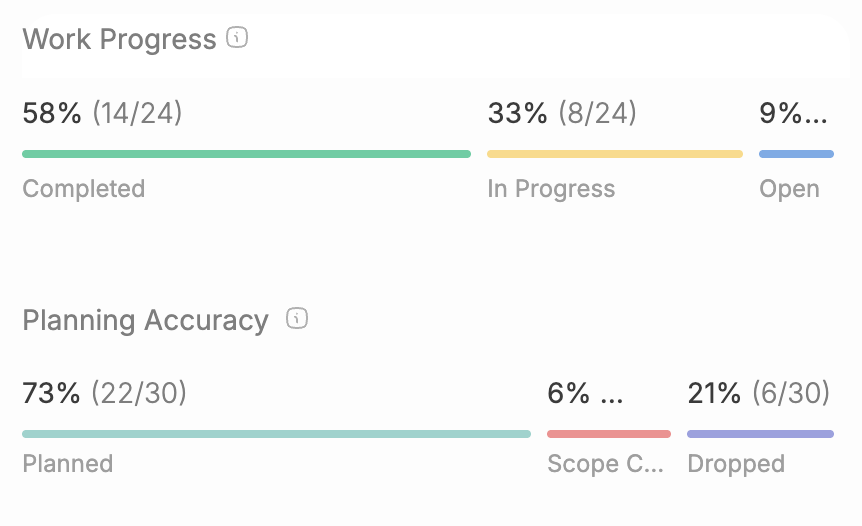
Team Velocity represents the average number of completed issue tickets or story points across each sprint.

Developer workload represents the count of issue tickets or story points completed by each developer against the total issue tickets/story points assigned to them in the current sprint.
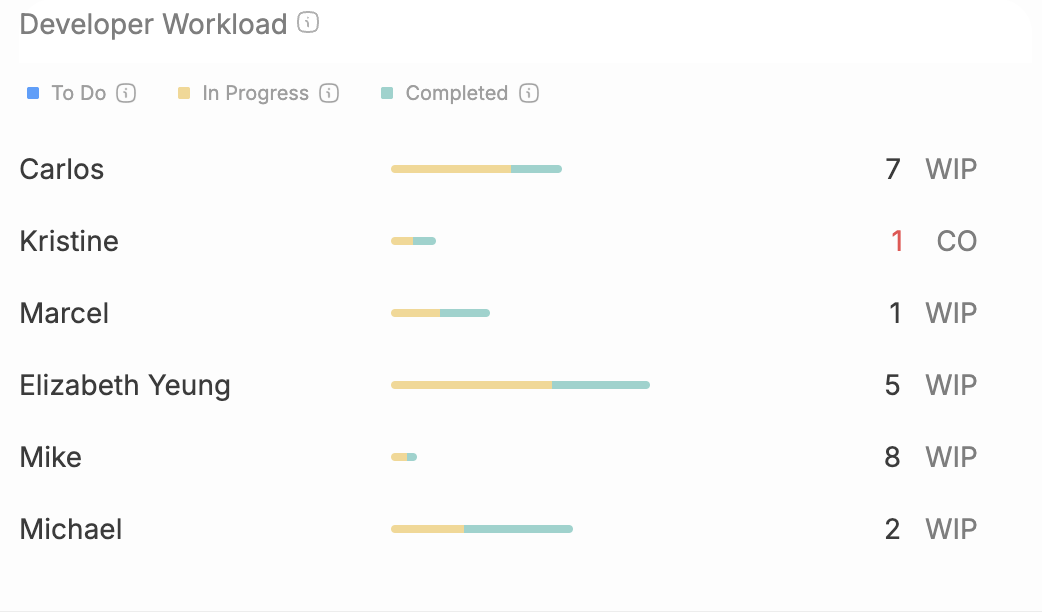
It represents how many tickets are stuck at what stages and their ageing graphs.
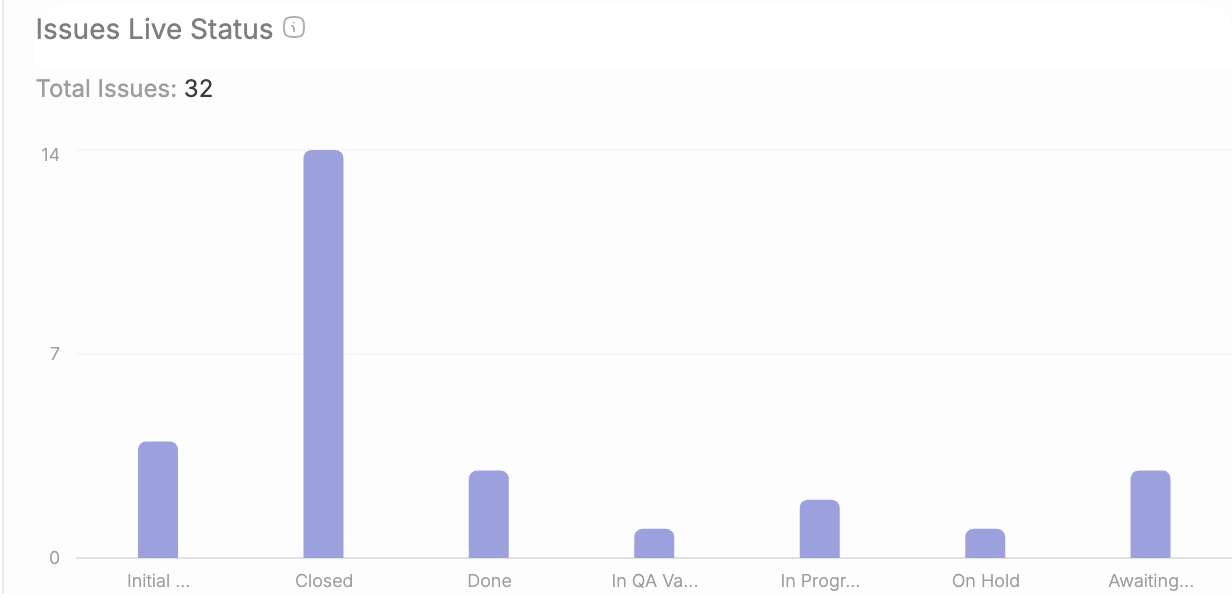
A Burndown Chart shows the actual and estimated amount of work to be done in a sprint. The horizontal x-axis in a Burndown Chart indicates time, and the vertical y-axis indicates story points.
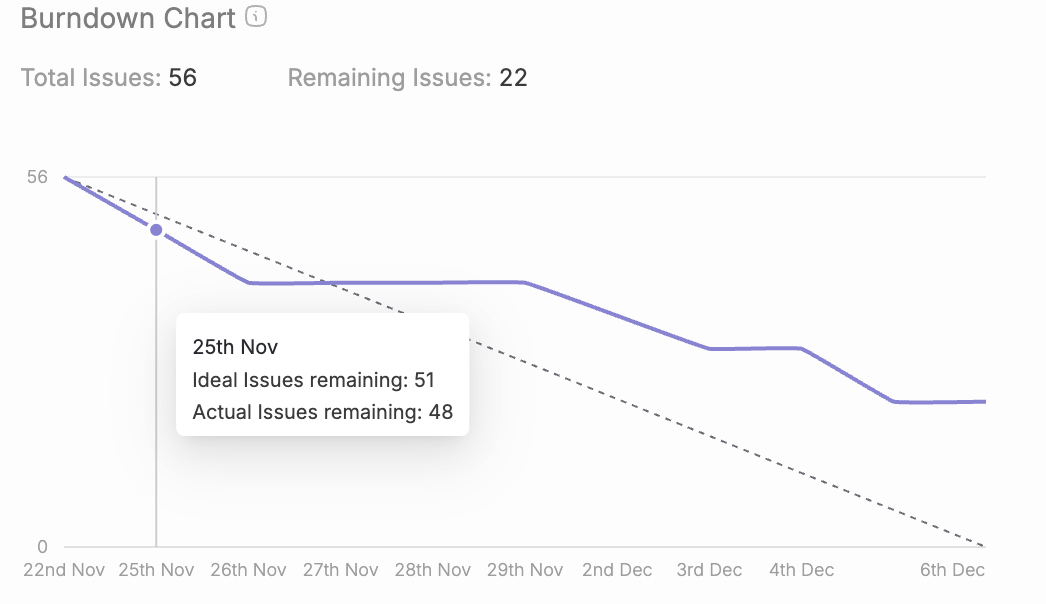
Scope creep is one of the common project management risks. It represents the new project requirements that are added to a project beyond what was originally planned.
Creating and sharing detailed agendas with all meeting participants ahead of time is essential for effective Sprint Review Meetings. To set a productive agenda, consider including the following key points:
Sharing the agenda in advance ensures everyone knows what to expect and can prepare accordingly.
Enhance sprint review meetings by enabling real-time collaboration and providing comprehensive metrics to the scrum team. Access to live data and interactive dashboards ensures the team has the most current information and can engage in dynamic discussions. Key metrics such as velocity, issue tracking, and cycle time provide valuable insights into team performance and workflow efficiency. This transparency and data-driven approach facilitate informed decision-making, improve accountability, and support continuous improvement, making sprint reviews more productive and collaborative.
Make it easy to collect, organize, and prioritize valuable feedback from stakeholders. Utilize feedback forms or surveys to gather structured input during or after the meeting. Real-time documentation of feedback ensures that no valuable insights are lost. Additionally, categorizing and tagging feedback can help with easier tracking and action planning.
Use presentation tools to enhance the demonstration of completed work. Incorporate charts, graphs, and other visual aids to make progress more understandable and engaging. Interactive elements can allow stakeholders to explore new features hands-on, increasing engagement and comprehension.
Drive continuous improvement in Sprint Review Meetings by analyzing feedback trends, identifying recurring issues or areas for improvement, encouraging team members to reflect on past meetings and suggest enhancements, and implementing data-driven insights to make each Sprint Review more effective than the last.
A well-executed Sprint Review Meeting can significantly enhance your team’s productivity and alignment with stakeholders. A successful sprint review focuses on delivering business value and ensures the team is moving in the right direction toward project goals and the overarching product goal. Celebrating achievements during sprint reviews boosts morale and motivates the team for future challenges. By focusing on preparation, effective communication, structured agendas, interactive demos, and continuous improvement, you can transform your Sprint Reviews into a powerful tool for success. Clear goals should be established at the outset of each meeting to provide direction and focus for the team.
Remember, most sprint reviews fail to deliver more value because they become ineffective sprint reviews focused only on outputs rather than outcomes. The key is to foster a collaborative environment where valuable feedback is provided and acted upon, driving your team toward continuous improvement and excellence. It is important to align each review with product goals and ensure every session has a clear point that drives improvement. Integrating tools like Typo can provide the structure and capabilities needed to elevate your Sprint Review Meetings, ensuring they are both efficient and impactful.
Additionally, Typo’s AI-generated Sprint Retrospectives offer an objective review of meetings by automatically analyzing discussion points and feedback. This feature saves teams hours of preparation by generating comprehensive retro documents that highlight key insights, action items, and areas for improvement. By leveraging AI, teams can focus more on meaningful reflection and less on administrative tasks, making retrospectives more effective and efficient.
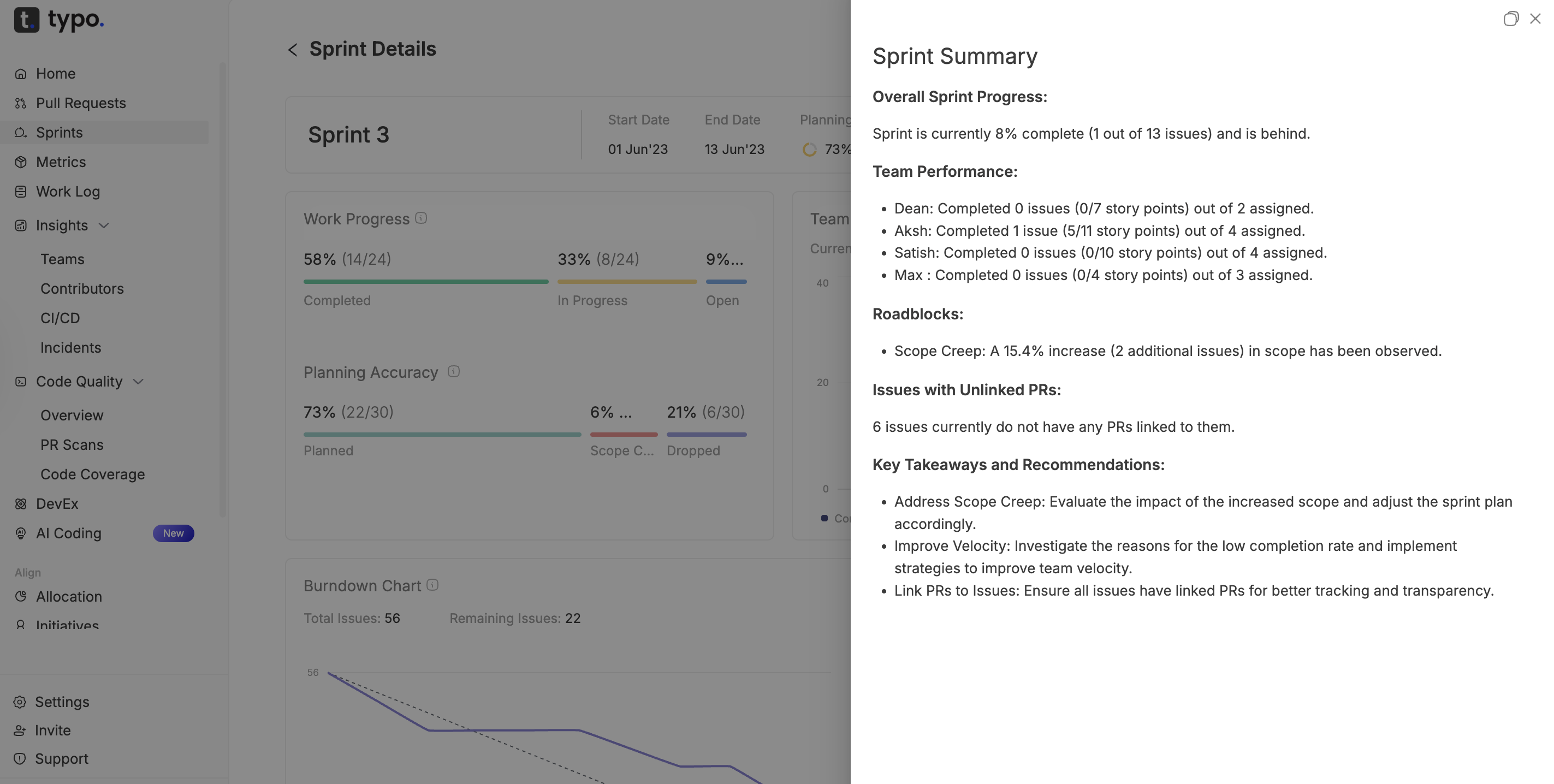
Remember, most sprint reviews fail to deliver more value because they become ineffective sprint reviews focused only on outputs rather than outcomes. The key is to foster a collaborative environment where valuable feedback is provided and acted upon, driving your team toward continuous improvement and excellence. It is important to align each review with product goals and ensure every session has a clear point that drives improvement. Integrating tools like Typo can provide the structure and capabilities needed to elevate your Sprint Review Meetings, ensuring they are both efficient and impactful.

Sprint reviews aim to foster open communication, active engagement, alignment with goals, and clear expectations. Despite these noble goals, many teams face significant hurdles in achieving them. These challenges often stem from the complexities involved in managing these elements effectively.
To overcome these challenges, teams should adopt a set of best practices designed to enhance the efficiency and productivity of sprint reviews. The following principles provide a framework for achieving this:
Continuous dialogue is the cornerstone of Agile methodology. For sprint reviews to be effective, a culture of open communication must be established and ingrained in daily interactions. Leaders play a crucial role in fostering an environment where team members feel safe to share concerns and challenges without fear of repercussions. This approach minimizes friction and ensures issues are addressed promptly before they escalate.
Case Study: Atlassian, a leading software company, introduced regular, open discussions about project hurdles. This practice fostered a culture of transparency, allowing the team to address potential issues early and leading to more efficient sprint reviews. As a result, they saw a 30% reduction in unresolved issues by the end of each sprint.
Sprint reviews should be interactive sessions with two-way communication. Instead of having a single person present, these meetings should involve contributions from all team members. Passing the keyboard around and encouraging real-time discussions can make the review more dynamic and collaborative.
Case Study: HubSpot, a marketing and sales software company, transformed their sprint reviews by making them more interactive. During brainstorming sessions for new campaigns, involving all team members led to more innovative solutions and a greater sense of ownership and engagement across the team. HubSpot reported a 25% increase in team satisfaction scores and a 20% increase in creative solutions presented during sprint reviews.
While setting clear goals is essential, the real challenge lies in revisiting and realigning them throughout the sprint. Regular check-ins with both internal teams and stakeholders help maintain focus and ensure consistency.
Case Study: Epic Systems, a healthcare software company, improved their sprint reviews by regularly revisiting their primary goal of enhancing user experience. By ensuring that all new features and changes aligned with this objective, they were able to maintain focus and deliver a more cohesive product. This led to a 15% increase in user satisfaction ratings and a 10% reduction in feature revisions post-launch.
Effective sprint reviews require clear and mutual understanding. Teams must ensure they are not just explaining but also being understood. Setting the context at the beginning of each meeting, followed by a quick recap of previous interactions, can bridge any gaps.
Case Study: FedEx, a logistics giant, faced challenges with misaligned expectations during sprint reviews. Stakeholders often expected these meetings to be approval sessions, which led to confusion and inefficiency. To address this, FedEx started each sprint review with a clear definition of expectations and a quick recap of previous interactions. This approach ensured that all team members and stakeholders were aligned on objectives and progress, making the discussions more productive. Consequently, FedEx experienced a 20% reduction in project delays and a 15% improvement in stakeholder satisfaction.
Beyond the foundational principles of open communication, engagement, goal alignment, and clear expectations, there are additional strategies that can further enhance the effectiveness of sprint reviews:
Using data and metrics to track progress can provide objective insights into the team’s performance and highlight areas for improvement. Tools like burn-down charts, velocity charts, and cumulative flow diagrams can be invaluable in providing a clear picture of the team’s progress and identifying potential bottlenecks.
Example: Capital One, a financial services company, used velocity charts to track their sprint progress. By analyzing the data, they were able to identify patterns and trends, which helped them optimize their workflow and improve overall efficiency. They reported a 22% increase in on-time project completion and a 15% decrease in sprint overruns.
Continuous improvement is a key tenet of Agile. Incorporating feedback loops within sprint reviews can help teams identify areas for improvement and implement changes more effectively. This can be achieved through regular retrospectives, where the team reflects on what went well, what didn’t, and how they can improve.
Example: Amazon, an e-commerce giant, introduced regular retrospectives at the end of each sprint review. By discussing successes and challenges, they were able to implement changes that significantly improved their workflow and product quality. This practice led to a 30% increase in overall team productivity and a 25% improvement in customer satisfaction ratings.
Involving stakeholders in sprint reviews can provide valuable insights and ensure that the team is aligned with business objectives. Stakeholders can offer feedback on the product’s direction, validate the team’s progress, and provide clarity on priorities.
Example: Google started involving stakeholders in their sprint reviews. This practice helped ensure that the team’s work was aligned with business goals and that any potential issues were addressed early. Google reported a 20% improvement in project alignment with business objectives and a 15% decrease in project scope changes.
Atlassian, a leading software company, faced significant challenges with communication during sprint reviews. Developers were hesitant to share early feedback, which led to delayed problem-solving and escalated issues. The team decided to implement daily check-in meetings where all members could discuss ongoing challenges openly. This practice fostered a culture of transparency and ensured that potential issues were addressed promptly. As a result, the team’s sprint reviews became more efficient, and their overall productivity improved. Atlassian saw a 30% reduction in unresolved issues by the end of each sprint and a 25% increase in overall team morale.
HubSpot, a marketing and sales software company, struggled with engagement during their sprint reviews. Meetings were often dominated by a single presenter, with little input from other team members. To address this, HubSpot introduced interactive brainstorming sessions during sprint reviews, where all team members were encouraged to contribute ideas. This change led to more innovative solutions and a greater sense of ownership and engagement among the team. HubSpot reported a 25% increase in team satisfaction scores, a 20% increase in creative solutions presented during sprint reviews, and a 15% decrease in time to market for new features.
Epic Systems, a healthcare software company, had difficulty maintaining focus on their primary goal of enhancing user experience. Developers frequently pursued interesting but unrelated tasks. The company decided to implement regular check-ins to revisit and realign their goals. This practice ensured that all new features and changes were in line with the overarching objective, leading to a more cohesive product and improved user satisfaction. As a result, Epic Systems experienced a 15% increase in user satisfaction ratings, a 10% reduction in feature revisions post-launch, and a 20% improvement in overall product quality.
FedEx, a logistics giant, faced challenges with misaligned expectations during sprint reviews. Stakeholders often expected these meetings to be approval sessions, which led to confusion and inefficiency. To address this, FedEx started each sprint review with a clear definition of expectations and a quick recap of previous interactions. This approach ensured that all team members and stakeholders were aligned on objectives and progress, making the discussions more productive. Consequently, FedEx experienced a 20% reduction in project delays, a 15% improvement in stakeholder satisfaction, and a 10% increase in overall team efficiency.
Data and metrics can provide valuable insights into the effectiveness of sprint reviews. For example, according to a report by VersionOne, 64% of Agile teams use burn-down charts to track their progress. These charts can highlight trends and potential bottlenecks, helping teams optimize their workflow.
Additionally, a study by the Project Management Institute (PMI) found that organizations that use Agile practices are 28% more successful in their projects compared to those that do not. This statistic underscores the importance of implementing effective Agile practices, including efficient sprint reviews.
Sprint reviews are a critical component of the Agile framework, designed to ensure that teams stay aligned on goals and progress. By addressing common challenges such as communication barriers, lack of engagement, misaligned goals, and unclear expectations, teams can significantly improve the effectiveness of their sprint reviews.
Implementing strategies such as fostering open communication, promoting active engagement, setting and reinforcing goals, ensuring clarity in expectations, leveraging data and metrics, incorporating feedback loops, and facilitating stakeholder involvement can transform sprint reviews into highly productive sessions.
By learning from real-life case studies and incorporating data-driven insights, teams can continuously improve their sprint review process, leading to better project outcomes and greater overall success.

Sprint reports are a crucial part of the software development process. They help in gaining visibility into the team’s progress, how much work is completed, and the remaining tasks.
While there are many tools available for sprint reports, the JIRA sprint report stands out to be the most reliable one. Thousands of development teams use it on a day-to-day basis. However, as the industry shifts towards continuous improvement, JIRA’s limitations may impact outcomes.
So, what can be the right alternative for sprint reports? And what factors to be weighed when choosing a sprint reports tool?
Sprints are the core of agile and scrum frameworks. It represents defined periods for completing and reviewing specific work.
Sprint allows developers to focus on pushing out small, incremental changes over large sweeping changes. Note that, they aren’t meant to address every technical issue or wishlist improvement. It lets the team members outline the most important issues and how to address them during the sprint.
Analyzing progress through sprint reports is crucial for several reasons:
Analyzing sprint reports ensures transparency among the team members. It includes an entire scrum or agile team that has a clear and shared view of work being done and pending tasks. There is no duplication of work since everything is visible to them.
Sprint reports allow software development teams to have a clear understanding and requirements about their work. This allows them to focus on prioritized tasks first, fix bottlenecks in the early stages and develop the right solutions for the problems. For engineering leaders, these reports give them valuable insights into their performance and progress.
Sprint reports eliminate unnecessary work and overcommitment for the team members. This allows them to allocate time more efficiently to the core tasks and let them discuss potential issues, risks and dependencies which further encourages continuous improvement. Hence, increasing the developers’ productivity and efficiency.
The sprint reports give team members a visual representation of how work is flowing through the system. It allows them to identify slowdowns or blockers and take corrective actions. Moreover, it allows them to make adjustments to their processes and workflow and prioritize tasks based on importance and dependencies to maximize efficiency.
JIRA sprint reports tick all of the benefits stated above. Here’s more to JIRA sprint reports:
Out of many sprint reporting software, JIRA Sprint Report stands out to be the out-of-the-box solution that is being used by many software development organizations. It is a great way to analyze team progress, keep everyone on track, and complete the projects on time.
You can easily create simple reports from the range of reports that can be generated from the scrum board:
Projects > Reports > Sprint report
There are many types of JIRA reports available for sprint analysis for agile teams. Some of them are:
JIRA sprint reports are built into JIRA software, convenient and are easy to use. It helps developers understand the sprint goals, organize and coordinate their work and retrospect their performance.
However, few major problems make it difficult for the team members to rely solely on these reports.
JIRA sprint reports measure progress predominantly via story points. For teams who are not working with story points, JIRA reports aren’t of any use. Moreover, it sidelines other potential metrics as well. This makes it challenging to understand team velocities and get the complete picture.
Another limitation is that the team has to read between the lines since it presents the raw data to team members. This doesn’t give accurate insights of what truly happening in the organization. Rather every individual can come with slightly different conclusions and can be misunderstood and misinterpreted in different ways.
JIRA add-ons need installation and have a steep learning curve which may require training or technical expertise. They are also restricted to the JIRA system making it challenging to share with external stakeholders or clients.
So, what can be done instead? Either the JIRA sprint report can be supplemented with another tool or a better alternative that considers all of its limitations. The latter option proves to be the right option since a sprint dashboard that shows all the data and reports at a single place saves time and effort.
Typo’s sprint analysis is a valuable tool for any team that is using an agile development methodology. It allows you to track and analyze your team’s progress throughout a sprint. It helps you gain visual insights into how much work has been completed, how much work is still in progress, and how much time is left in the sprint. This information can help you to identify any potential problems early on and take corrective action.

Our sprint analysis feature uses data from Git and issue management tools to provide insights into how your team is working. You can see how long tasks are taking, how often they’re being blocked, and where bottlenecks are occurring. This information can help you identify areas for improvement and make sure your team is on track to meet their goals.
It is easy to use and can be integrated with existing Git and Jira/Linear/Clickup workflows.
Work progress represents the percentage breakdown of issue tickets or story points in the selected sprint according to their current workflow status.
Typo considers all the issues in the sprint and categorizes them based on their current status category, using JIRA status category mapping. It shows three major categories by default:
These can be configured as per your custom processes. In the case of a closed sprint, Typo only shows the breakup of work on a ‘Completed’ & ‘Not Completed’ basis.
Work breakup represents the percentage breakdown of issue tickets in the current sprint according to their issue type or labels. This helps in understanding the kind of work being picked in the current sprint and plan accordingly.
Typo considers all the issue tickets in the selected sprint and sums them up based on their issue type.

Team Velocity represents the average number of completed issue tickets or story points across each sprint.
Typo calculates Team Velocity for each sprint in two ways :
To calculate the average velocity, the total number of completed issue tickets or story points are divided by the total number of allocated issue tickets or story points for each sprint.

Developer Workload represents the count of issue tickets or story points completed by each developer against the total issue tickets/story points assigned to them in the current sprint.
Once the sprint is marked as ‘Closed’, it starts reflecting the count of Issue tickets/Story points that were not completed and were moved to later sprints as ‘Carry Over’.
Typo calculates the Developer Workload by considering all the issue tickets/story points assigned to each developer in the selected sprint and identifying the ones that have been marked as ‘Done’/’Completed’. Typo categorizes these issues based on their current workflow status that can be configured as per your custom processes.
The assignee of a ticket is considered in either of the two ways as a default:
This logic is also configurable as per your custom processes.

Issue cycle time represents the average time it takes for an issue ticket to transition from the ‘In Progress’ state to the ‘Completion’ state.
For all the ‘Done’/’Completed’ tickets in a sprint, Typo measures the time spent by each ticket to transition from ‘In Progress’ state to ‘Completion’ state.
By default, Typo considers 24 hours in a day and 7 day work week. This can be configured as per your custom processes.
Scope creep is one of the common project management risks. It represents the new project requirements that are added to a project beyond what was originally planned.
Typo’s sprint analysis tool monitors it to quantify its impact on the team’s workload and deliverables.

Sprint analysis tool is important for sprint planning, optimizing team performance and project outcomes in agile environments. By offering comprehensive insights into progress and task management, it empowers teams to focus on sprint goals, make informed decisions and drive continuous improvement.
To learn more about this tool, visit our website!

The software development field is constantly evolving, with increasing demands for code quality, security, and compliance. For developers, QA professionals, and engineering managers, ensuring that software meets rigorous standards and is delivered on time is critical. Mistakes can lead to costly rework, security vulnerabilities, and compliance failures.
Static code analysis is a foundational practice that examines source code without executing it, helping teams identify syntax errors, security vulnerabilities, and deviations from coding standards early in the development lifecycle. By enforcing coding conventions and improving maintainability, static code analysis plays a vital role in modern software engineering.
This article will cover:
Whether you are a developer, QA engineer, or engineering manager, understanding static code analysis is essential for improving code quality, security, and compliance across your projects.
Static code analysis is a method of examining source code without executing it to find potential issues, vulnerabilities, and errors. It also checks whether the code follows standards such as MISRA (Motor Industry Software Reliability Association, a set of guidelines for safety-critical systems) and ISO 26262 (an international standard for functional safety in automotive software).
Used by software developers and quality assurance teams, static code analysis helps catch problems early in development, improving code quality, security, and team productivity before defects reach production. Static analysis tools help enforce coding standards and improve maintainability, making it easier for teams to collaborate and maintain readable, consistent code.
This guide explains what static code analysis is, how it differs from dynamic code analysis, how it works through techniques such as lexical analysis, control flow graphs, data flow analysis, and taint analysis, and where its benefits and limitations apply. It also looks at AI-powered static analysis tools and how Typo uses AI to strengthen code analysis workflows.
The word ‘Static’ indicates that this analysis and testing occur without executing the application or compromising production systems.
The major difference between static code analysis and dynamic code analysis is when and how issues are identified:
Static and dynamic analysis should not be used as alternatives to each other. Development teams must optimize and combine both methods to achieve comprehensive coverage and effective results.
Now that we've compared static and dynamic analysis, let's explore how static code analysis works in practice.
Static code analysis is conducted early in the development lifecycle. The process typically involves several sequential steps, each contributing to the thorough examination of code for quality and security.
Lexical analysis plays a crucial role in static code analysis by transforming the raw source code into a structured set of tokens. This process is essential for making the code manageable and ready for further analysis.
When the source code undergoes lexical analysis, it's broken down into small, manageable pieces known as tokens. These tokens represent distinct elements of the programming language, such as keywords, operators, and identifiers. The conversion of the source code into tokens simplifies the intricacies of the original code structure, making it easier to identify patterns, detect errors, and analyze the overall behavior of the code.
T_OPEN_TAG, T_VARIABLE, T_CONSTANT_ENCAPSED_STRING, ;, T_CLOSE_TAG. These tokens offer a higher level of abstraction and read like a structured language summary of the original code.Overall, lexical analysis is a fundamental step in preparing code for more detailed analysis, allowing for effective code review and quality assurance.
With a clear understanding of the static code analysis workflow, let's dive deeper into the specific techniques used to analyze code.
Taint analysis is a crucial aspect of ensuring code security, designed to identify potential vulnerabilities within a software application. This process involves tracking and managing how external, uncontrolled inputs interact with your system's code, determining if these inputs might introduce security risks.
Having explored the main techniques, let's look at the key benefits of static code analysis for development teams.
Static code analysis offers a wide range of benefits for software development teams, including:
With these benefits in mind, it's important to recognize the limitations of static code analysis as well.
While static code analysis is a powerful tool, it does have certain limitations:
To address some of these limitations and further enhance code analysis, many teams are turning to AI-powered static analysis tools.
AI-powered static application security testing uses artificial intelligence and machine learning to find issues early in the application development life cycle. These tools identify security vulnerabilities and broader code health checks with greater precision and accuracy than traditional rule-based systems.
Now, let's see how Typo leverages AI and static code analysis to streamline code review and quality assurance.
Typo's automated code review tool enables developers to merge clean, secure, high-quality code faster. It fits into both the software development lifecycle and the security development lifecycle, helping teams perform static code analysis to catch code quality and security issues before merge.
Typo detects issues related to maintainability, readability, and potential bugs, and can identify code smells across the development lifecycle to support secure software delivery. It auto-analyzes your codebase and pull requests to find issues and auto-generates fixes before you merge to master, helping teams avoid common mistakes during code reviews.
Typo's Auto-Fix feature leverages GPT 3.5 Pro to generate line-by-line code snippets where issues are detected in the codebase. This means less time reviewing and more time for important tasks, making the whole process faster and smoother.
Typo supports a variety of programming languages, including popular ones like C++, JS, Python, and Ruby, ensuring ease of use for developers working across diverse projects.
Typo understands the context of your code and quickly finds and helps fix issues uncovered by static code analysis, including logical errors and security flaws, accurately. This empowers developers to work on software projects seamlessly and efficiently.
Typo uses optimized practices and built-in methods spanning multiple languages, reducing code complexity and ensuring thorough quality assurance throughout the development process.
Typo standardizes code, improves code quality, and reduces the risk of a security breach through compliance-oriented analysis rules as part of professional coding standards, which can be reinforced with an effective code review checklist.
To wrap up, let's address some of the most common questions about static code analysis.
Static code analysis examines source code without executing it. It is used to find syntax errors, security vulnerabilities, and violations of coding standards early in the development process.
Static analysis tools help enforce coding standards and improve maintainability by:
Software Composition Analysis (SCA) is a process that identifies and manages open-source and third-party components in a codebase, helping teams detect vulnerabilities and license compliance issues in dependencies.
By understanding and implementing static code analysis, development teams can significantly improve code quality, security, and compliance, while streamlining collaboration and reducing long-term maintenance costs.

Code complexity is almost unavoidable in modern software development. High code complexity, when not tackled on time, leads to an increase in bugs, and technical debt, and negatively impacts the performance.
Let’s dive in further to explore the concept of cognitive complexity in software.
Code complexity refers to how difficult it is to understand, modify, and maintain the software codebase. It is influenced by various factors such as lines of code, code structure, number of dependencies, and algorithmic complexity.
Code complexity exists at multiple levels including the system architecture level, within individual modules or single code blocks.
The more the code complexity, the more complex a piece of code is. Hence, developers use it to make efforts to minimize it wherever possible. By managing code complexity, developers can reduce costs, improve software quality, and provide a better user experience.
In complex code, it becomes difficult to identify the root cause of bugs. Hence, making debugging a more arduous job. These changes can further have unintended consequences due to unforeseen interactions with other parts of the system. By measuring code complexity, developers can particularly complex identity areas that they can further simplify to reduce the number of bugs and improve the overall reliability of the software.
Managing code complexity increases collaboration between team members. Identifying areas of code that are particularly complex requires additional expertise. Hence, enhancing the shared understanding of code by reviewing, refactoring, or redesigning these areas to improve code maintainability and readability.
High code complexity presents various challenges for testing such as increased test case complexity and reduced test coverage. Code complexity metrics help testers assess the adequacy of test coverage. It allows them to indicate areas of the code that may require thorough testing and validation. Hence, they can focus on high code complexity areas first and then move on to lower complexity areas.
Complex code can also impact performance as complex algorithms and data structures can lead to slower execution times and excessive memory consumption. It can further hinder software performance in the long run. Managing code complexity encourages adherence to best practices for writing clean and efficient code. Hence, enhancing the performance of their software systems and delivering better-performing applications to end-users.
High code readability leads to an increase in code quality. However, when the code is complex, it lacks readability. This further increases the cognitive load of the developers and slows down the software development process.
The overly complex code is less modular and reusable which hinders the code clarity and maintenance.
The main purpose of documentation is to help engineers work together to build a product and have clear requirements of what needs to be done. The unavailability of documentation may make developers’ work difficult since they have to revisit tasks, undefined tasks, and code overlapping and duplications.
Architectural decisions dictate the way the software is written, how to improve it, tested against, and much more. When such decisions are not well documented or communicated effectively, it may lead to misunderstandings and inconsistency in implementation. Moreover, when the architectural decisions are not scalable, it may make the codebases difficult to extend and maintain as the system grows.
Coupling refers to the connection between one piece of code to another. However, it is to be noted that they shouldn’t be highly dependent on each other. Otherwise, it leads to high coupling. It increases the interdependence between modules which makes the system more complex and difficult to understand. Moreover, it also makes the code difficult to isolate and test them independently.
Cyclomatic complexity was developed by Thomas J. Mccabe in 1976. It is a crucial metric that determines the given piece of code complexity. It measures the number of linearly independent paths through a program’s source code. It is suggested cyclomatic complexity must be less than 10 for most cases. More than 10 means the need for refactoring the code.
To effectively implement this formula in software testing, it is crucial to initially represent the source code as a control flow graph (CFG). The CFG is a directed graph comprising nodes, each representing a basic block or a sequence of non-branching statements, and edges denoting the control flow between these blocks.

Once the CFG for the source code is established, cyclomatic complexity can be calculated using one of the three approaches:
In each approach, an integer value is computed, indicating the number of unique pathways through the code. This value not only signifies the difficulty for developers to understand but also affects testers’ ability to ensure optimal performance of the application or system.
Higher values suggest greater complexity and reduced comprehensibility, while lower numbers imply a more straightforward, easy-to-follow structure.
The primary components of a program’s CFG are:
For instance, let’s consider the following simple function:
def simple_function(x):
if x > 0:
print(“X is positive”)
else:
print(“X is not positive”)
In this scenario:
E = 2 (number of edges)
N = 3 (number of nodes)
P = 1 (single connected component)
Using the formula, the cyclomatic complexity is calculated as follows: CC = 2 – 3 + 2*1 = 1
Therefore, the cyclomatic complexity of this function is 1, indicating very low complexity.
This metric comes in many built-in code editors including VS code, linters (FlakeS and jslinter), and IDEs (Intellij).
Sonar developed a cognitive complexity metric that evaluates the understandability and readability of the source code. It considers the cognitive effort required by humans to understand it. It is measured by assigning weights to various program constructs and their nesting levels.
The cognitive complexity metric helps in identifying code sections and complex parts such as nested loops or if statements that might be challenging for developers to understand. It may further lead to potential maintenance issues in the future.
Low cognitive complexity means it is easier to read and change the code, leading to better-quality software.
Halstead volume metric was developed by Maurice Howard Halstead in 1977. It analyzes the code’s structure and vocabulary to gauge its complexities.
The formula of Halstead volume:
N * log 2(n)
Where, N = Program length = N1 + N2 (Total number of operators + Total number of operands)
n = Program vocabulary = n1 + n2 (Number of operators + number of operands)
The Halstead volume considers the number of operators and operands and focuses on the size of the implementation of the module or algorithm.
The rework ratio measures the amount of rework or corrective work done on a project to the total effort expended. It offers insights into the quality and efficiency of the development process.
The formula of the Rework ratio:
Total effort / Effort on rework * 100
Where, Total effort = Cumulative effort invested in the entire project
Effort on rework = Time and resources spent on fixing defects, addressing issues, or making changes after the initial dev phase
While rework is a normal process. However, a high rate of rework is considered to be a problem. It indicates that the code is complex, prone to errors, and potential for defects in the codebase.
This metric measures the score of how easy it is to maintain code. The maintainability index is a combination of 4 metrics – Cyclomatic complexity, Halstead volume, LOC, and depth of inheritance. Hence, giving an overall picture of complexity.
The formula of the maintainability index:
171 – 5.2 * ln(V) – 0.23 * (G) – 16.2 * ln(LOC)
The higher the score, the higher the level of maintainability.
0-9 = Very low level of maintainability
10-19 = Low level of maintainability
20-29 = Moderate level of maintainability
30-100 = Good level of maintainability
This metric determines the potential challenges and costs associated with maintaining and evolving a given software system.
It is the easiest way to calculate and purely look at the number of LOCs. LOC includes instructions, statements, and expressions however, typically excludes comments and blank lines.
Counting lines of executable code is a basic measure of program size and can be used to estimate developers’ effort and maintenance requirements. However, it is to be noted that it alone doesn’t provide a complete picture of code quality or complexity.
The requirements should be clearly defined and well-documented. A clear roadmap should be established to keep projects on track and prevent feature creep and unnecessary complexities.
It helps in building a solid foundation for developers and maintains the project’s focus and clarity. The requirements must ensure that the developers understand what needs to be built reducing the likelihood of misinterpretation.
Break down software into smaller, self-contained modules. Each module must have a single responsibility i.e. focus on specific functions to make it easier to understand, develop, and maintain the code.
It is a powerful technique to manage complex code as well as encourages code reusability and readability.
Refactor continuously to eliminate redundancy, improve code readability and clarity, and adhere to best practices. It also helps streamline complex code by breaking down it into smaller, more manageable components.
Through refactoring, the development team can identify and remove redundant code such as dead code, duplicate code, or unnecessary branches to reduce the code complexity and enhance overall software quality.
Code reviews help maintain code quality and avoid code complexity. It identifies areas of code that may be difficult to understand or maintain later. Moreover, peer reviews provide valuable feedback and in-depth insights regarding the same.
There are many code review tools available in the market. They include automated checks for common issues such as syntax errors, code style violations, and potential bugs and enforce coding standards and best practices. This also saves time and effort and makes the code review process smooth and easy.
Typo’s automated code review tool not only enables developers to catch issues related to maintainability, readability, and potential bugs but also can detect code smells. It identifies issues in the code and auto-fixes them before you merge to master. This means less time reviewing and more time for important tasks. It keeps the code error-free, making the whole process faster and smoother.
Key features

Understanding and addressing code complexity is key to ensuring code quality and software reliability. By recognizing its causes and adopting strategies to reduce them, development teams can mitigate code complexity and enhance code maintainability, understandability, and readability.

There is no ‘One Size approach’ in the software development industry. Combining creative ways with technical processes is the best way to solve problems.
While it seems exciting, there is one drawback as well. There are a lot of disagreements between developers due to differences in ideas and solutions. Communication is the key for most cases, but this isn’t feasible every time. There are times when developers can’t come to a general agreement.
This is when the HOOP (Having opposite opinions and picking solutions) system works best for the team.
But, before we dive deeper into this topic, let’s first know what the Mini hoop basketball game is about:
Simply put, it is a smaller version of basketball that can be played indoors. It includes a smaller ball and hoop mounted on a wall or door.
A mini basketball hoop is a fun way to practice basketball skills and is usually enjoyed by people of all ages.

Below are a few ways how this game can positively impact developers in conflict-resolving and strengthening relationships with other team members:
This game creates a casual and enjoyable environment that strengthens team bonds, improving collaboration during work hours.
When developers take short breaks for a game, it helps prevent burnout and maintains high concentration levels during work hours. It leads to more efficient problem-solving and coding.
Developers practice conflict resolution when such differences arise in the game. As a result, they can apply these skills in the workplace.
Indoor basketball hoop game contributes to a positive work environment as they instill a sense of fun and camaraderie. Hence, it positively impacts morale and motivation.
Here's a step-by-step breakdown of the official rules for dev mini-hoop basketball:
Start with Player 1, then proceed sequentially through players 2, 3, etc. Each player takes a shot from a spot of their choice.
If the player before you makes a shot, make your shot exactly from the same spot. If you miss, you receive a strike.
After a miss, the next player starts a new round from a different spot. If you make the shot, the next player replicates it from the same spot. If missed, they receive a strike.
Once a player hits the three-strike mark, they are out.
The game continues until there is a winner.
The game usually concludes in about 10 minutes, if the whole team participates.
Dev Mini Hoop Basketball game is a fun way to resolve conflicts and strengthen relationships with other team members. Try it out with your team now!

Continuous integration/Continuous delivery (CI/CD) is positively impacting software development teams. It is becoming a common agile practice that is widely been adopted by organizations around the world. The rising importance of CI/CD is evident as 50% of developers now confirm regular usage of CI/CD tools, with a significant 25% having adopted a new tool within the past year.
In today’s rapidly evolving tech landscape, the competition is fierce. The use of CI/CD tools is not just beneficial but necessary to stay ahead. These tools enhance operations by automating processes, reducing human error, and allowing developers to focus on innovative solutions rather than routine tasks.
Hence, for the same, it is advisable to have good CI/CD tools to leverage the team’s current workflow and build a reliable CI/CD pipeline. This integration accelerates the development process and significantly lowers the delivery time to end-users, increasing productivity and product reliability. CI/CD tools are especially valuable for managing and automating tasks within cloud infrastructure, enabling efficient and scalable cloud operations.
Whether you’re part of a small startup or a large enterprise, incorporating CI/CD tools into your development practices is crucial. As we progress, the role of these tools will continue to expand, deeply embedding themselves into the fabric of modern software development and integrating seamlessly with cloud services. Additionally, there is a growing trend toward embedding security scans, such as SAST and DAST, directly into the CI/CD pipeline, with tools like GitLab CI/CD offering built-in security features.
There are an overflowing number of CI/CD tools available in the market right now. Thus, we have listed the top 14 tools to know about in 2024. But, before we move forward, understand these two distinct phases: Continuous Integration and Continuous Delivery. Many CI/CD tools now offer both cloud-hosted and self-hosted options to meet specific security or data residency requirements.
CI refers to the practices that drive the software development team to automatically and frequently integrate code changes into a shared source code repository. Code integration is a key aspect of CI, enabling teams to streamline the process of merging and validating changes. It helps in speeding up the process of building, packaging, and testing the applications. Although automated testing is not strictly part of CI, it is usually implied.
With this methodology, the team members can check whether the application is broken whenever new commits are integrated into the new branch. Pull requests can also trigger automated CI workflows to ensure code quality before merging changes into the main branch. It allows them to catch and fix quality issues early and get quick feedback.
This ensures that the software products are released to the end-users as quickly as possible (Every week, every day, or multiple times a day - As per the organization) and can create more features that provide value to them.
The CD begins when the continuous integration ends in the Software Development Life Cycle (SDLC).
It is an approach that allows teams to package software and deploy it into the production environment. CD automates the release process, enabling faster and more reliable software delivery. It includes staging, testing, and deployment of CI code, often using build and deployment pipelines to automate these steps.
It assures that the application is updated continuously with the latest code changes and that new features are delivered to the end users quickly. Hence, it helps to reduce the time to market and of higher quality.
Moreover, continuous delivery minimizes downtime due to the removal of manual steps and human errors.
CI/CD pipeline helps in building and delivering software to end-users at a rapid pace. It allows the development team to launch new features faster, implement deployment strategy, and collect feedback to incorporate promptly in the upcoming update. By automating processes, automation jobs play a crucial role in accelerating the CI/CD pipeline and reducing time to market.
CI/CD pipeline offers regular updates on the products and a set of metrics that include building, testing, coverage, and more. For teams using cloud-based CI/CD tools, cloud cost management is also a valuable metric, providing visibility into the expenses associated with deployments. The release cycles are short and targeted and maintenance is done during non-business hours saving the entire team valuable time.
CI/CD pipeline gives real-time feedback on code quality, test results, and deployment status. It can also provide feedback on code changes across multiple versions of the application or environment, ensuring compatibility and reliability. It provides timely feedback to work more efficiently, identify issues earlier, gather actionable insights, and make iterative improvements.
CI/CD pipeline encourages collaboration between developers, testers, and operation teams to reduce bottlenecks and facilitate communication. CI/CD tools that support different version control systems make it easier for teams using various source code repositories to collaborate seamlessly. Through this, the team can communicate effectively about test results and take the desired action.
CI/CD pipeline enforces a rigorous testing process and conducts automated tests at every pipeline stage. The code changes are thoroughly tested and validated to reduce the bugs or regressions in software. Additionally, CI/CD tools with enhanced security features help maintain high quality and protect the software by providing advanced protection and compliance capabilities.
Why Continuous Improvement Matters in Software Development
Continuous improvement is crucial in the software development lifecycle for several compelling reasons.
In essence, continuous improvement paves the way for robust, reliable, and user-friendly software, ensuring long-term success in the fast-paced software industry.
It is a software development platform for managing different aspects of the software development lifecycle. With its cloud-based CI and deployment service, this tool allows developers to trigger builds, run, tests, and deploy code with each commit or push. GitLab also offers a free tier, which provides a limited number of build minutes and features suitable for small teams or open-source projects.
GitLab CI/CD also assures that all code deployed to production adheres to all code standards and best practices, leveraging its integrated source code management capabilities.
GitHub Actions is a comparatively new tool for performing CI/CD. It automates, customizes, and executes software development workflows right in the repository. GitHub Actions is focused on enabling developers to automate and customize their workflows, empowering them to efficiently manage CI/CD processes within GitHub. It is free for public repositories with generous usage limits.
GitHub Actions can also be paired with packages to simplify package management. It creates custom SDLC workflows in the GitHub repository directly and supports event-based triggers for automated build, test, and deployment, and integrates with third party tools to extend functionality.
Jenkins is the first CI/CD tool that provides thousands of plugins to support building and deploying projects. It is an open source as well as a self-hosted automated server, and is widely recognized as an open source automation server in which the central build and continuous integration take place. This tool can also be turned into a continuous delivery platform for any project. Open-source tools like Jenkins offer unmatched flexibility but require more maintenance compared to simpler cloud-based SaaS options. Jenkins is open-source and free to use, but users must pay for the infrastructure it runs on.
It is usually an all-rounder choice for the modern development environment.
CircleCI is a CI/CD tool that is certified with FedRAMP and SOC Type II compliant. It helps in achieving CI/CD in open-source and large-scale projects. Furthermore, CircleCI excels in continuous integration for both web applications and mobile platforms, making it a versatile choice for developers across various domains. CircleCI is also known for its strong automation capabilities and deep Docker support.
CircleCI provides two host offerings:
By integrating these capabilities, CircleCI stands out as a powerful tool for developers aiming to enhance operational efficiency and speed in both web and mobile application development.

An integrated CI/CD tool that is integrated into Bitbucket. As a version control system, Bitbucket enables seamless integration with CI/CD pipelines, allowing for efficient code collaboration, fetching, and deployment workflows. It automates code from test to production and lets developers track how pipelines are moving forward at each step.
Bitbucket pipelines ensure that code has no merge conflicts, accidental code deletions, or broken tests. Cloud containers are generated for every activity on Bitbucket that can be used to run commands with all the benefits of brand-new system configurations.
A CI/CD tool that helps in building and deploying different types of projects on GitHub and Bitbucket. It runs in a Java environment and supports .Net and open-stack projects. TeamCity is also compatible with diverse infrastructure setups, allowing seamless integration across various sources, platforms, and frameworks.
TeamCity offers flexibility for all types of development workflow and practices. It archives or backs up all modifications errors and builds for future use.
Semaphore is a CI/CD platform with a pull-request-based development workflow. Through this platform, developers can automate build, test, and deploy software projects with the continuous feedback loop. As one of the essential tools for modern CI/CD workflows, Semaphore plays a key role in efficient cloud management and deployment processes.
Semaphore is available on a wide range of platforms such as Linux, MacOS, and Android. This tool can help in everything i.e. simple sequential builds to multi-stage parallel pipelines.
Azure DevOps by Microsoft combines continuous integration and continuous delivery pipeline to Azure. It includes self-hosted and cloud-hosted CI/CD models for Windows, Linux, and MacOS. Azure DevOps is an all-in-one CI/CD platform that integrates project tracking, artifact management, and testing tools.
Azure Test Plans, a key feature of Azure DevOps, supports manual and exploratory testing. It integrates with other Azure DevOps tools to streamline test management and enhance software quality assurance processes.
It builds, tests, and deploys applications to the transferred location. The transferred locations include multiple target environments such as containers, virtual machines, or any cloud platform.
Bamboo is a CI/CD server by Atlassian that helps software development teams automate the process of building, testing, and deploying code changes. It covers building and functional testing versions, tagging releases, and deploying and activating new versions on productions. Bamboo Data Center is a comprehensive, self-hosted CI/CD platform designed for large-scale enterprises, offering high availability and seamless integration with other Atlassian tools within the Data Center ecosystem. TeamCity, developed by JetBrains, is another robust CI/CD platform that offers extensive support for various programming languages and VCS types.
This streamlines software development and includes a feedback loop to make stable releases of software applications.

An open-source CI/CD tool that is a Python-based twisted framework. It automates complex testing and deployment processes. Buildbot is also well-suited for managing complex CI/CD workflows, enabling teams to orchestrate intricate build and deployment pipelines. With its decentralized and configurable architect, it allows development teams to define and build pipelines using scripts based on Python.
Buildbot are usually for those who need deep customizability and have particular requirements in their CI/CD workflows.
Travis CI primarily focuses on GitHub users. It provides different host offerings for open-source communities and enterprises that propose to use this platform on their private cloud. Travis CI is a simple and powerful tool that lets development teams sign up, link favorite repositories, and build and test applications. As part of the CI/CD process, Travis CI can also deploy to various cloud resources, enabling teams to automate the provisioning and management of cloud infrastructure. It checks the reliability and quality of code changes before integrating them into the production codebase. Travis CI is known for its simplicity and ease of setup, particularly for projects hosted on GitHub.
Travis CI is a simple and powerful tool that lets development teams sign up, link favorite repositories, and build and test applications. As part of the CI/CD process, Travis CI can also deploy to various cloud resources, enabling teams to automate the provisioning and management of cloud infrastructure. It checks the reliability and quality of code changes before integrating them into the production codebase.
Live build views for monitoring GitHub projects can significantly assist in engineering effective developer feedback.
Codefresh is a modern CI/CD tool that is built on the foundation of GitOps and Argo. It is Kubernetes-based and comes with two host offerings: Cloud and On-premise variants.
It provides a unique, container-based pipeline for a faster and more efficient build process. Codefresh offers a secure way to trigger builds, run tests, and deploy code to targeted locations. Additionally, Codefresh supports deploying to multiple cloud providers, making it versatile for managing infrastructure across different cloud platforms.
Buddy is a CI/CD platform that builds, tests, and deploys websites and applications quickly. It includes two host offerings: On-premise and public cloud variants. It is best suited for developers, QA experts, and designers.
Buddy can not only integrate with Docker and Kubernetes, but also with blockchain technology. It gives the team direct deployment access to public repositories including GitHub. Teams that rely on Jira dashboards for project management can also benefit from seamless integration across tools.
Simple and intuitive UI is crucial for an efficient workflow, especially during code reviews.

Harness is the first CI/CD platform to leverage AI. It is a SaaS platform that builds, tests, deploys, and verifies on demand. Harness also excels at managing infrastructure by automating complex workflows and efficiently handling cloud resources through best practices in infrastructure management as code. Harness is a self-sufficient CI tool and is container-native so all extensions are standardized and builds are isolated. Moreover, it sets up only one pipeline for the entire log.
AI-driven automation is revolutionizing the CI/CD landscape by introducing several key capabilities:
By incorporating these AI-driven capabilities, Harness not only enhances individual features but also transforms the entire CI/CD pipeline into a more proactive and intelligently managed process. This leads to increased delivery cycles and improved pipeline performance.
As software development evolves, CI/CD (Continuous Integration and Continuous Deployment) tools are advancing at a remarkable pace. Staying ahead in this landscape is crucial for organizations that strive to lead in technological innovation. Configuration management is becoming increasingly important in modern CI/CD pipelines, enabling teams to automate and manage large-scale cloud infrastructure and application deployments efficiently. Modern CI/CD tools like CircleCI, GitLab CI/CD, and Azure Pipelines integrate with Infrastructure as Code (IaC) tools such as Terraform, AWS CloudFormation, and Pulumi. Defining pipelines using YAML files stored in the repository is standard practice among modern CI/CD tools, enabling version control and collaboration.
Infrastructure as Code (IaC) is transforming how teams automate the provisioning and management of resources. By using code to define infrastructure, organizations can ensure consistency, reduce manual errors, and accelerate deployment cycles. These tools also help teams manage infrastructure efficiently, allowing for scalable operations and streamlined maintenance across diverse environments.
Artificial Intelligence (AI) is increasingly being woven into the fabric of CI/CD pipelines. Here's how AI-driven automation can benefit your enterprise:
AI-driven CI/CD not only accelerates delivery cycles but also provides a smarter, more proactive management approach to pipeline operations.
Serverless computing is redefining traditional notions of infrastructure management, and its integration into CI/CD brings several advantages:
This trend is particularly beneficial for organizations aiming to trim operational expenses while enhancing efficiency.
Serverless computing is transforming continuous integration and continuous deployment (CI/CD) practices by removing the need for developers to manage underlying servers and infrastructure. This approach brings several key benefits:
With these advantages, serverless computing is particularly attractive to companies looking to optimize operational expenses and streamline their development workflows. The result is an environment where developers can concentrate on innovation, enhancing both productivity and software quality.
Infrastructure as Code (IaC) is emerging as a cornerstone of modern CI/CD pipelines, offering substantial advantages:
IaC tools can be used to manage resources on cloud platforms such as Google Cloud Platform, enabling automated provisioning and management of Google Cloud infrastructure. This approach streamlines deployment and resource management on GCP.
Integrating IaC into your CI/CD system can lead to faster, more dependable deployments, cutting down on errors from manual handling of infrastructure.
By adopting these cutting-edge trends, organizations can not only keep pace with technological advances but also capitalize on improved efficiency, reliability, and cost-effectiveness in their software development practices.
Infrastructure as Code (IaC) is revolutionizing the way organizations manage their infrastructure, making it an integral part of contemporary CI/CD (Continuous Integration and Continuous Deployment) pipelines. Here’s how it seamlessly fits into the picture:
1. Automating Infrastructure Management
With IaC, infrastructure setup becomes code-driven, allowing automated provisioning and deprovisioning of environments. This automation ensures that each stage of deployment, whether for development, testing, or production, is consistent and efficient. By scripting these processes, teams can redeploy environments swiftly, adapting to changing requirements without manual intervention. IaC tools can provision and manage various AWS services and integrate with other AWS services, enabling end-to-end automation across the AWS ecosystem.
2. Leveraging Version Control Systems
Treating infrastructure like application code opens new dimensions in version control. Using platforms like Git, teams can version their infrastructure scripts, track changes over time, and roll back configurations if needed. This versioning encourages collaboration, enabling multiple team members to work on infrastructure setups concurrently without conflict.
3. Enhancing Collaboration and Consistency
IaC scripts are stored in code repositories, fostering an environment where developers and operations teams coalesce comfortably. By documenting infrastructure as code, organizations ensure that anyone from the team can understand the setup, enhancing transparency and boosting collaboration across different stages of the CI/CD pipeline.
4. Streamlining Testing and Deployment
Integrating IaC with CI/CD pipelines enables systematic testing of infrastructure changes. Automated tests can be triggered after every change in the infrastructure code, ensuring only validated configurations proceed to deployment. This structured approach reduces the risk of errors and enhances the reliability and predictability of deployments.
5. Reducing Human Error
By minimizing manual setup and relying on automated scripts, organizations significantly reduce the potential for human error. Automated workflows ensure that infrastructure deployments align perfectly with the code specified, leading to more reliable environments.
Incorporating IaC into CI/CD processes not only accelerates deployment timelines but also enhances the overall reliability of software releases, proving to be a vital asset in modern software development practices.
Typo seamlessly integrates with your CI/CD tools and offers comprehensive insights into your deployment process through key metrics such as change failure rate, time to build, and deployment frequency.
It also delivers a detailed overview of the workflows within the CI/CD environment. Hence, enhances visibility and facilitates a thorough understanding of the entire development and deployment pipeline.

The CI/CD tool should best align with the needs and goals of the team and organization. In terms of features, understand what is important according to the specific requirements, project, and goals. When choosing a CI/CD tool, it is essential to compare functionality against your own requirements and consider how your projects are likely to evolve in the future.
The CI/CD tool should integrate smoothly into the developer workflow without requiring many customized scripts or plugins. The tool shouldn't create friction or impose constraints on the testing framework and environment.
The CI/CD tool should include access control, code analysis, vulnerability scanning, and encryption. It should adhere to industry best practices and prevent malicious software from stealing source code.
They should integrate with the existing setup and other important tools that are used daily. Also, the CI/CD tool should be integrated with the underlying language used for codebase and compiler chains.
The tool should provide comprehensive feedback on multiple levels. It includes error messages, bug fixes, and infrastructure design. Besides this, the tool should notify of build features, test failures, or any other issues that need to be addressed.
In the dynamic world of software development, scalability emerges as a pivotal factor when selecting a CI/CD tool. As your development team expands and project demands intensify, a scalable tool becomes indispensable to maintain seamless operations.
In essence, choosing a CI/CD tool with robust scalability ensures that your team can meet growing demands and perform efficiently, without inflating expenditures or compromising quality.
The CI/CD tools mentioned above are the most popular ones in the market. Make sure you do your extensive research as well before choosing any particular tool.
All the best!

This article is designed for software engineers, engineering managers, and anyone interested in code maintainability. Here, you’ll find a comprehensive overview of cognitive complexity software—what it is, why it matters in software development, and how to manage it effectively. Understanding and managing code cognitive complexity is crucial for building sustainable software projects: it directly impacts maintainability, team productivity, and the long-term cost of software.
Software developers rely on measuring code complexity to ensure code is maintainable and readable.
If you’re seeking actionable insights and best practices for handling cognitive complexity software, you’re in the right place.
Cognitive complexity is a software quality metric that measures how difficult code is to understand. In the context of software, cognitive complexity software refers to tools and practices that help assess and manage the mental effort required to comprehend code. It takes into consideration how readable and understandable code is for humans, emphasizing human readability as a crucial factor in writing code that is easy for people to understand.
A key challenge addressed by cognitive complexity is code comprehension, especially when dealing with complex business logic. Improving code comprehension and understanding code helps ensure that software can be maintained and evolved effectively. Easier-to-understand code facilitates better collaboration among team members and allows new team members to become productive more quickly.
Cognitive complexity is an important implication for code quality and maintainability. The more complex the code, the higher the chances of bugs and errors during modifications. This can lower developer productivity and slow down the development process. Traditional metrics like cyclomatic complexity may overlook crucial aspects such as nested structures and flow-breaking statements, which are essential for understanding the true complexity and maintainability of code.
Cyclomatic complexity counts the number of execution paths within a function and was conceptualized by Thomas J. McCabe in 1976. It provides a quantitative view of structural complexity and helps determine testing effort. Cognitive complexity focuses on readability and maintainability, while cyclomatic complexity focuses on testability. Unlike cyclomatic complexity, cognitive complexity is a better indicator of human readability.
Cognitive complexity is also a good indicator of future maintenance costs, as it reflects the difficulty of maintaining code. The cost of maintaining software is frequently higher than the cost of its implementation, making cognitive complexity an important metric.
Transition: Now that we’ve defined cognitive complexity and its significance in software, let’s explore its psychological roots and how it differs from traditional complexity metrics.
Cognitive complexity, while rooted in psychology, has evolved distinctly within the realm of technology and software engineering. In psychology, it describes the depth and breadth of an individual’s thought processes—how intricately people perceive and think about various issues.
In software engineering, cognitive complexity software measures not just the structure of code, but also the mental effort required for developers to understand, maintain, and interact with complex systems. This mental effort can significantly impact user engagement and the overall mental load experienced when working with intricate codebases.
In psychology, cognitive complexity refers to the richness of a person's mental framework when considering different perspectives. It's about how nuanced or straightforward a person's understanding of a subject is. A highly cognitive complex individual can appreciate multiple sides of an argument, weighing the relationships between different ideas.
In the field of technology, particularly human-computer interaction, cognitive complexity takes on a more functional role. It describes how a user engages with a system and the mental load required. In software engineering, it may pertain to how layered and interconnected a system or source code is. Complex business logic, which involves domain-specific rules and requirements, is a common source of cognitive complexity in software systems. Various factors contribute to cognitive complexity, including deeply nested structures and complex logic, which add complexity to software systems and make them harder to understand and maintain.
A key difference lies in the application:
For example, consider strategic games. When comparing Checkers to Chess, Chess is more cognitively complex. There are more potential moves and outcomes to consider, which means a player must juggle a greater number of concepts simultaneously. This kind of complexity can exist in software when users navigate complex systems with multiple interacting components, or when a developer works with a particularly intricate piece of code.
Transition: With this context, we can now examine the specific factors that influence cognitive complexity in software and how they relate to code readability and maintainability.
Cognitive complexity evaluates control flow, nesting depth, and the readability of code constructs (Fact: < fact>3< /fact>). It is calculated by assigning weights to various programming constructs and their nesting levels (Fact: < fact>2< /fact>). These factors directly impact how easily a developer can read, understand, and modify code. Measuring code complexity using metrics such as cognitive complexity, cyclomatic complexity, and the maintainability index is essential to gain a complete picture of code quality and maintainability.
Reducing complexity is a key strategy for improving code maintainability and developer productivity.
Transition: Understanding these factors sets the stage for recognizing the different levels and causes of cognitive complexity in software projects.
Transition: Recognizing these levels helps identify the root causes of cognitive complexity, which we’ll explore next.
Transition: To address these causes, it’s important to distinguish between accidental and essential complexity.
Transition: With these distinctions in mind, let’s look at how to measure cognitive complexity in practice.
Transition: After measuring cognitive complexity, the next step is to leverage tools and best practices to manage and reduce it.
Transition: With the right tools and strategies in place, let’s explore actionable steps to reduce cognitive complexity in your codebase.
Transition: By applying these strategies, teams can proactively manage cognitive complexity and ensure long-term code quality.
Managing code complexity is crucial for maintaining code quality and developer efficiency. Understanding and addressing cognitive complexity is key, as high cognitive complexity is a form of technical debt that accumulates over time, slowing down future development and increasing costs. By recognizing its causes, measuring it with the right tools, and adopting strategies to reduce it, development teams can mitigate cognitive complexity and streamline the development process for sustainable, maintainable software projects.

There are two main types of code reviews: 1. Formal code review and 2. Lightweight code review.
As the name suggests, formal code reviews are based on a structured process to find defects in code, specifications, and designs. This approach follows established guidelines and involves multiple reviewers. The most popular form of formal code review is Fagan Inspection, which consists of six steps: Planning, overview meeting, preparation, inspection meeting, casual analysis, reworking, and follow-up.
However, formal code reviews can be more time-consuming and resource-intensive than other types.
Lightweight code reviews are commonly used by development teams and not typically by testers. This approach is often followed when the code review is not life-threatening or when the impact on software quality is less critical.
There are four subtypes of lightweight code review:
Also known as pair programming, this type involves two developers working together on the same computer—one writes code while the other reviews it in real time. Such a type is highly interactive and helps in knowledge sharing and spotting bugs.
In synchronous code review, the author produces the code and asks the reviewer for feedback immediately after coding. The coder and reviewer then discuss and improve the code together, involving direct communication and real-time discussion.
Similar to synchronous code review, but the code authors and reviewers do not have to look at the code at the same moment. This approach allows flexibility and is especially beneficial for developers working across various time zones, where remote teams can especially benefit from AI-assisted code reviews.
This type is used for specific situations where different roles are assigned to reviewers. It enables more in-depth reviews and provides various perspectives. For team code reviews, tools such as code review platforms, version control systems, collaboration platforms, and AI support for remote code reviews are often used.
Choose the correct code review type based on your team's strengths, weaknesses, and the unique factors of your organization.
Now that we've covered the main types of code reviews, let's explore the best practices to make them effective.
Code review is all about improving code quality, but it can be a nightmare for engineering managers and developers when not done correctly. This article outlines the top 10 code review best practices, providing actionable guidance for developers and engineering managers who want to enhance code quality and team productivity. Following these code review best practices is crucial for promoting collaboration, improving code readability, and fostering a positive team culture. By adhering to these best practices, teams can overcome common code review challenges and streamline the entire development process.
A code review checklist provides clear expectations for reviews by listing specific criteria and questions to consider. Code review checklists help reduce conflicts by creating a shared understanding around the same review criteria.
Some necessary quality checks include:
When reviewing code, consider these questions:
This first pass allows you to know what to look for in a code review, set clear expectations, and focus on priorities. Teams should customize the checklist to their own practices and review criteria.
Transitioning from establishing clear review criteria, let's look at how to foster a positive and collaborative code review culture.
The code review process should be an opportunity for growth and knowledge sharing, not a critique of developers' abilities. Effective code reviews support knowledge sharing across the whole team.
To create a culture of collaboration and learning:
This approach helps the development team understand the purpose behind code review and view it as a way to improve their coding abilities and skills. Keeping a clear quality bar helps teams stay consistent, and great code reviews reinforce that standard over time.
With a collaborative culture in place, the next step is to ensure feedback is constructive and actionable.
One of the most important code review practices is to provide feedback that is specific, honest, and actionable. Before requesting peer input, authors should do a self-review to catch obvious mistakes. Constructive feedback is essential for building rapport within your software development team.
Feedback should:
Authors should provide clear descriptions of changes and use code comments to annotate each code change with the reasoning behind it. Comments should be written clearly and concisely.
This helps improve the skills of software developers and produces better code, resulting in a high-quality codebase—especially when reviewers avoid common mistakes during code reviews. Clear review comments and suggested changes are also easier to act on when reviewers understand the reasoning.
After establishing effective feedback, it's important to manage the size and scope of code changes for optimal review.
Instead of reviewing all changes at once, focus on small sections to examine all aspects thoroughly. Breaking changes into small, manageable chunks helps identify potential issues and offer suggestions for improvement.
Follow these steps for effective incremental reviews:
Smaller PRs allow developers to understand code changes quickly, and reviewers can provide more focused and detailed reviews. Reviewing code in smaller pull requests helps catch logic errors more reliably, and reviewing more than 400 lines of code reduces defect detection.
This approach leads to a deeper understanding of the code's impact on the overall project, which is especially important when shipping a new feature and optimizing code reviews to boost developer productivity.
With manageable changes, it's also important to measure the effectiveness of your code review process.
According to Goodhart's law, “When a measure becomes a target, it ceases to be a good measure.”
To measure the effectiveness of code review, set tangible goals to provide a quantifiable picture of how your code is improving. Use metrics to determine the efficiency of your review and analyze the impact of process changes. These metrics should support better decisions, not pressure reviewers into faster approvals at the expense of quality.
Consider tracking these key metrics:
You can use metrics-driven code review tools to decide in advance the goals and how to measure effectiveness. AI in the code review process can help identify patterns in code changes when analyzing review metrics.
Once you have metrics in place, it's important to pace your reviews to maintain quality and avoid burnout.
To ensure effective code reviews, avoid reviewing too much code at once. Keep these three key points in mind:
Code reviews should also be prompt, ideally within hours, so authors are not left waiting. Google recommends fast reviews to avoid blocking authors, and AI-powered PR summaries with estimated review time can help prioritize reviews without sacrificing quality.
Reviewing code continuously can reduce focus and attention to detail, making reviews less effective and increasing the risk of burnout. Conduct code review sessions often and in short sessions, encourage breaks, and set boundaries. If the core change is sound, minor suggestions should not block progress.
After pacing your reviews, consider how reviewer rotation can further improve your process.
Relying on the same code reviewers consistently can cause burnout and negatively impact the software development process over time.
Encourage a rotation approach:
With this approach, team members become familiar with different parts of the codebase, avoid bias in the review process, and understand each other's coding styles.
Next, let's discuss the importance of documenting code review decisions for future reference.
Documenting code review decisions is essential for understanding the overall effectiveness of the code review process. Ensure that you record and track the code review outcome for future reference. Good commit messages help future reviewers understand why a change was made, making it easier for those who may work on the codebase in the future.
Documentation provides insights into the reasoning behind certain choices, designs, and modifications. It helps keep historical records—changes made over time, reasons for those changes, and any lessons learned during the review process. Documenting decisions should also capture review outcomes after updates are made. This accelerates onboarding for new joiners and supports continuous improvement within the development team.
With documentation in place, it's important to focus on coding standards for consistency.
Emphasizing coding standards promotes consistency, readability, maintainability, and overall code quality. Automated tools should handle formatting and linting checks before human review.
Personal preferences vary widely among developers. Teams should focus standards on maintainability and readability rather than personal taste, and use automated tools to enforce code formatting and linting instead of debating them in review. This helps address potential issues early in the development process and ensures the codebase remains consistent over time.
Adhering to coding standards makes it easier to scale development efforts and add new features and components seamlessly. Minor style issues, such as whether names appear in alphabetical order, should usually be treated as low priority unless the standard explicitly requires them.
Finally, let's look at how automation can further streamline your code review process.
Code review is a vital process, yet it can be time-consuming. Automate what can be automated.
Use code review tools like Typo or other AI-powered code review tools to improve your development workflow to help improve code quality and increase speed, precision, consistency, and overall quality. Make automated checks the first layer of review automation, including static code analysis plus formatting and linting checks. Automated tests and unit tests should verify correctness, but a human reviewer is still needed to assess business logic and intent.
This allows reviewers to spend more time giving valuable feedback, tracking changes, and enabling easy collaboration. It also ensures that changes don't break existing functionality and that automation supports the code review process rather than replacing it.
With automation in place, let's explore a tool that can help streamline your code review workflow.
Typo's automated code review tool identifies issues in your code and auto-fixes them before you merge to master. This means less time reviewing and more time for important tasks. It keeps your code error-free, making the whole process faster and smoother.
Learn More About Typo's Automated Code Review
If you prioritize the code review process, do follow the above-mentioned best practices. These code review best practices maximize the quality of the code, improve the team's productivity, and streamline the development process.
Happy reviewing!

The code review process is vital to the software development life cycle. It helps improve code quality and minimizes technical debt by addressing potential issues in the early stages.
Due to its many advantages, many teams have adopted code review as an important practice. However, it can be a reason for frustration and disappointment too which can further damage the team atmosphere and slow down the entire process. Hence, the code review process should be done with the right approach and mindset.
In this blog post, we will delve into common mistakes that should be avoided while performing code reviews.
Performing code review helps in identifying areas of improvement in the initial stages. It also helps in code scalability i.e. whether the code can handle increased loads and user interactions efficiently. Besides this, it allows junior developers and interns to gain the right feedback and hone their coding skills. This, altogether, helps in code optimization.
Code reviews allow maintaining code easily even when the author is unavailable. It lets multiple people be aware of the code logic and functionality and allows them to follow consistent coding standards. The code review process also helps in identifying opportunities for refactoring and eliminating redundancy. It also acts as a quality gate to ensure that the code is consistent, clear, and well-documented.
The code review process provides mutual learning to both reviewers and developers. It not only allows them to gain insights but also to understand each other perspectives. For newbies, they get an idea of why certain things are done in a certain way. It includes the architecture of the application, naming conventions, conventions of structuring code within a class, and many more.
Performing code reviews helps in maintaining consistent coding styles and best practices across the organization. It includes formatting, code structure, naming conventions, and many more. Besides this, code review is often integrated with the dev workflow. Hence, it cannot be merged into the main code base without passing through the code review process.
While code review is a tedious task, it saves developers time in fixing bugs after the product’s release. A lack of a code review process can increase flaws and inconsistencies in code. It also increases the quality of code which are more maintainable and less prone to errors. Further, it streamlines the development process and reduces technical debt which saves significant time and effort to resolve later.
Code reviewers do provide feedback. Yet, most of the time they are neither clear nor actionable. This not only leads to delays and ambiguity but also slows down the entire development process.
For example, if the reviewer adds a comment ‘Please change it’ without giving any further guidance or suggestion. The code author may take it in many different ways. They may implement the same according to their understanding or sometimes they don’t have enough expertise to make changes.
Unfortunately, it is one of the most common mistakes made by the reviewers.
These suggestions will allow code authors to understand the reviewer’s perspective and make necessary changes.
The review contains a variety of tests such as unit tests, integration tests, end-to-end tests, and many more. It gets difficult to review all of them which lets reviewers skim through them and jump straight to implementations and conclusions.
This not only eludes the code review process but also puts the entire project at risk. The reasons behind not reviewing the tests are many including time-constraint and not understanding the signs of robust testing and not prioritizing it.
Skipping tests is a common mistake by reviewers. It is time-consuming for sure, but it comes bearing a lot of benefits too.
Another common mistake is only reviewing changed lines of code. Code review is an ever-evolving process that goes through various phases of change.
Old lines are deleted accidentally or ignored because for obvious reasons can be troublemakers. Reviewing only newly added codes overlooks the interconnected nature of a codebase and results in missing specific details that can further, jeopardize the whole project.
Always review existing and newly added codes together to evaluate how new changes might affect existing functionality.
A proper code review process needs both time and peace. The rushed review may result in poorly written code and hinder the process's efficiency. Reviewing code before the demo, release, or deadline are a few reasons behind rushed reviews.
During rush reviews, code reviewers read the code lines rather than reading the code through lines. It usually happens when reviewers are too familiar with the code. Hence, they examine by just skimming through the code.
It not only results in missing out on fine and subtle mistakes but also compromises coding standards and security vulnerabilities.
Rush reviews should be avoided at any cost. Use the suggestions to help in reviewing the code efficiently.
It is the responsibility of the reviewer to examine the entire code - From design and language to mechanism and operations. However, most of the time, reviewers focus only on the functionality and operationality of the code. They do not go much into designing and architecture part.
It could either be due to limited time or a rush to meet deadlines. However, it may demand close consideration and observation to look into the design and architecture side to understand how it ties in with what’s already there.
Focusing on design and architecture ensures a holistic assessment of the codebase, fostering long-term maintainability and alignment with overall project goals.
A code review checklist is important while doing code reviews. Without the checklist, the process is directionless. Not only this, reviewers may unintentionally overlook vital elements, lack consistency, and miss certain aspects of code. Not using the checklist may confuse whether all the aspects are covered as well and key best practices, coding standards, and security considerations may be neglected.
Behind effective code reviews is a checklist that involves every task that needs to be ticked off.
A code review should not include cosmetic concerns; it will efficiently use time. Use a tool to manage these concerns, which can be predefined with well-defined coding style guides.
For further reference, here are some cosmetic concerns:
Functional flaws of the code should not be reviewed separately as this leads to loss of time and manual repetition. The reviewer can instead trust automated testing pipelines to carry out this task.
Enforcing coding standards and generating review notifications should also be automated, as repetitive tasks enhance efficiency.
As a code reviewer, base your reviews on the established team and organizational coding standards. Imposing the coding standards that reviewers personally follow should not serve as a baseline for the reviews.
Reviewing a code can sometimes lead to the practice of striving for perfection. Overanalyzing the code can lead to this. Instead, as a code reviewer, focus on improving readability and following the best practices.
Another common mistake is that reviewers don’t follow up after reviewing. Following up is important to address feedback, implement changes, and resolve any issues identified.
The lack of follow-up actions is also because reviewers assume that identified issues will be resolved. In most cases it does, but still, they need to ensure that the issues are addressed as per the standard and in the correct way.
It leads to accountability gaps, and unclear expectations, and the problems may persist even after reviewing negatively impacting code quality.
Lack of follow-up actions may lead to no improvements or outcomes. Hence, it is an important practice that needs to be followed in every organization.
Typo’s automated code review tool identifies issues in your code and auto-fixes them before you merge to master. This means less time reviewing and more time for important tasks. It keeps your code error-free, making the whole process faster and smoother.
The code review process is an important aspect of the software development process. However, when not done correctly, it can negatively impact the project.
Follow the above-mentioned suggestions for the common mistakes to not let these few mistakes negatively impact the software quality.
Happy reviewing!

Research and Development (R&D) has become the hub of innovation and competitiveness in the dynamic world of modern business. A deliberate and perceptive strategy is required to successfully navigate the financial complexities of R&D expenses.
When done carefully, the process of capitalizing R&D expenses has the potential to produce significant benefits. In this blog, we dive into the cutting-edge R&D cost capitalization techniques that go beyond the obvious, offering practical advice to improve your financial management skills. Understanding the capitalization process and adhering to capitalization rules is essential to ensure compliance with accounting standards and to maximize the benefits for your company's financial statements.
Capitalizing R&D costs is a legitimate accounting method that involves categorizing software R&D expenses, such as FTE wages and software licenses, as investments rather than immediate expenditures. Put more straightforwardly, it means you’re not merely spending money; instead, you’re making an investment in the future of your company.
Capitalizing on R&D costs entails a smart transformation of expenditures into strategic assets, with capitalizing costs directly impacting the company's financial structure and reported assets, beyond a simple transaction. While traditional methods follow Generally Accepted Accounting Principles (GAAP), it is wise to investigate advanced strategies.
One such strategy is activity-based costing, which establishes a clear connection between costs and particular R&D stages. This fine-grained understanding of cost allocation improves capitalization accuracy while maximizing resource allocation wisdom. Additionally, more accurate appraisals of R&D investments can be produced using contemporary valuation techniques suited to your sector’s dynamics. From an economic perspective, the decision to capitalize or expense R&D costs can significantly influence a company's innovation capacity, profitability, and long-term value creation.
R&D capitalization transforms how companies handle their research and development investments, turning what could be immediate expense hits into strategic long-term assets. This financial approach spreads the recognition of development costs across the useful life of resulting innovations, rather than crushing net income in a single period. Organizations leveraging this strategy see enhanced financial metrics—boosting net income and return on invested capital—while gaining clearer visibility into how their ongoing development activities drive future growth.
Companies pouring substantial resources into research and development discover that mastering r d capitalization becomes mission-critical. This practice reshapes how costs appear on financial statements, influences stakeholder perceptions of financial health, and directly impacts investment decisions. By synchronizing the recognition of r d costs with the periods when benefits actually materialize, organizations accurately capture the value their research and development efforts generate. Technology companies and innovation-driven businesses particularly benefit from this approach, as development costs often represent massive portions of their total invested capital.
Navigating the accounting treatment of research and development costs requires mastering established frameworks like Generally Accepted Accounting Principles (GAAP) and International Financial Reporting Standards (IFRS). Under GAAP, companies typically expense most research and development costs as they occur, acknowledging the inherent uncertainty surrounding future benefits. However, certain development costs can unlock capitalization opportunities when they satisfy specific criteria—particularly when they demonstrate alternative future use by contributing to groundbreaking products, innovative processes, or cutting-edge technologies.
IFRS transforms this landscape with a more flexible approach, empowering companies to capitalize development costs when they meet stringent conditions. Organizations must demonstrate technical feasibility alongside clear intention to complete and either utilize or sell the resulting asset. Both frameworks hinge on a critical capability: proving that incurred costs will generate measurable future economic benefits. This distinction separates research activities—which typically face immediate expensing—from development activities that may qualify for capitalization treatment.
Beyond these accounting principles, the federal tax code introduces its own comprehensive ruleset governing the capitalization and amortization of research and development investments. Companies must navigate compliance with both accounting standards and tax regulations simultaneously, avoiding potential conflicts with tax authorities while optimizing their financial reporting strategies. For technology companies and organizations investing heavily in research and development initiatives, mastering these principles becomes essential for making strategic decisions about cost capitalization and accurately reflecting these investments in financial statements.
This is to be noted that only some expenditures can be converted into assets. Only capitalizable costs that meet qualifying costs and certain criteria under accounting standards, such as ASC 730 or IAS 38, are eligible for capitalization. GAAP guidelines are explicit about what qualifies for cost capitalization in software development. R&D must adhere to specific conditions to be recognized as an asset on the balance sheet. These include:
When discussing software development costs, it is important to note that internal use software is treated differently under accounting standards. Costs related to internal use software may be capitalized as intangible assets if they meet the required criteria.
In allocating costs for R&D projects, it is essential to distinguish between direct costs, which are directly related to the project, and indirect costs, such as utilities or administrative expenses. Only direct costs and certain indirect costs that are necessary for the completion of the project may be eligible for capitalization, depending on the applicable accounting standards.
The capitalizable cost should be contributing to a tangible product or process.
The firm's commitment should evolve into a well-defined plan. The half-hearted endeavors should be eliminated.
Projections for market entry and the product must yield financial returns in the future. The potential to generate future revenue is a key factor in determining whether development costs can be capitalized under IFRS.
In software development costs, GAAP’s FASB Account Standard Codification ASC Topic 350 - Intangibles focuses on internal use only software eligible for capitalization:
That being said, FASB Accounting Standards Codification (ASC) Topic 985 – Software addresses sellable software for external use. It covers:
Note that, costs related to initial planning and prototyping cannot be capitalized. Therefore, they are not exempted from tax calculations.
In R&D capitalization, tech companies typically capitalize on engineering compensation, product owners, third-party platforms, algorithms, cloud services, and development tools. Although, In some cases, an organization’s acquisition targets may also be capitalized and amortized.
Enhancing your understanding of R&D cost capitalization necessitates adopting techniques beyond quantitative data to offer a comprehensive view of your investments. These tools transform numerical data into tactical choices, emphasizing the critical importance of data-driven insights.
Adopt tools that are strengthened by advanced analytics and supported by artificial intelligence (AI) prowess to assess the prospects of each R&D project carefully. Robust internal processes for tracking and managing R&D investments are essential to ensure accurate allocation and compliance. This thorough review enables the selection of initiatives with greater capitalization potential, ultimately optimizing the investment portfolio. Additionally, these technologies act as catalysts for resource allocation consistent with overarching strategic goals.
In Typo, you can use “Investment distribution” to allocate time, money, and effort across different work categories or projects for a given period of time. Investment distribution helps you optimize your resource allocation and drive your dev efforts towards areas of maximum business impact.
These insights can be used to evaluate project feasibility, resource requirements, and potential risks. You can allocate your engineering team better to drive maximum deliveries. Following specific guidance from accounting standards also helps ensure that investment allocation and capitalization decisions are compliant and accurate.

Effective amortization is the trajectory, while capitalization serves as the launchpad, defining intelligent financial management. For amortization goals, distinguishing between the various R&D components necessitates nothing less than painstaking thought. When R&D costs are capitalized, they are recognized as amortization expense over the asset's useful life, ensuring that financial statements reflect the gradual reduction in asset value.
Advanced techniques emphasize personalization by calibrating amortization periods to correspond to the lifespan of specific R&D assets. The appropriate amortization period is determined based on the estimated economic life of the R&D asset, such as a mobile phone, to ensure costs are allocated over the period the asset generates economic benefits. Shorter amortization periods are beckoned by ventures with higher risk profiles, reflecting the uncertainty they carry. Contrarily, endeavors that have predictable results last for a longer time. This customized method aligns costs with the measurable gains realized from each R&D project, improving the effectiveness of financial management.
Expense capitalization, along with the resulting amortization expense, directly impacts financial statements and profitability metrics by spreading R&D costs over the asset's economic life, thereby enhancing reported EBITDA and net income.
R&D cost capitalization should be tailored to the specific dynamics of each industry, taking into account the specifics of each sector. Combining agile approaches with capitalization strategies yields impressive returns in industries like technology and life sciences, both known for their creativity and flexibility and both significantly affected by R&D capitalization requirements.
Capitalization strategies dynamically alter when real-time R&D progress is tracked using agile frameworks like Scrum or Kanban. This realignment makes sure that the moving projects are depicted financially accurately. New rules and regulations, such as recent changes to section 174, can significantly impact capitalization strategies in industries such as technology and life sciences. Your strategy adapts to the contextual limits of the business by using industry-specific performance measures, highlighting returns within those parameters.
Controlling the complexities of R&D financial management necessitates an ongoing voyage marked by the fusion of approaches, tools, and insights specific to the sector. Combining the methods presented here results in a solid framework that fosters creativity while maximizing financial success. Understanding tax purposes and the impact of tax cuts and the Jobs Act is essential, as these factors significantly influence R&D capitalization and related financial strategies.
It is crucial to understand that the adaptability of advanced R&D cost capitalization defines it. Changes in tax years and tax years beginning after certain dates, especially under recent legislation, directly affect the capitalization and amortization of R&D costs. Additionally, regulatory approval plays a key role in determining the recognition and classification of R&D funding arrangements, impacting whether such arrangements are treated as liabilities or contractual obligations. Your journey is shaped by adapting techniques, being open to new ideas, and being skilled at navigating industry vagaries. This path promotes innovation and prosperity in the fiercely competitive world of contemporary business and grants mastery over R&D financials. The treatment of R&D expense and capitalization decisions directly impacts the income statement and overall financial reporting.

A well-organized and systematic approach must be in place to guarantee the success of your software development initiatives. The Software Development Lifecycle (SDLC), which offers a structure for converting concepts into fully functional software, can help. SDLC is a structured process that organizes software development activities, providing a clear framework for managing each stage effectively.
By breaking down software development into distinct phases—such as planning, implementation, testing, deployment, and maintenance—the SDLC process ensures that every aspect of a project is carefully managed and executed. Considering the entire lifecycle of software development is crucial for maximizing efficiency, enhancing security, and ensuring the highest quality in the final product. Following SDLC best practices helps produce high quality software that meets customer needs and industry standards.
The Software Development Life Cycle (SDLC) transforms modern software engineering by establishing a comprehensive framework that streamlines development workflows from initial conceptualization through production deployment and ongoing maintenance activities. By systematically organizing software development into distinct operational phases—including strategic planning, implementation execution, rigorous testing protocols, deployment orchestration, and continuous maintenance cycles—the SDLC framework ensures optimal project management and execution efficiency. This structured methodology empowers development teams to deliver high-performance software solutions that consistently surpass customer expectations while maintaining scalability and reliability standards.
A strategically implemented Software Development Life Cycle revolutionizes project management effectiveness by enabling development teams to optimize resource allocation, maintain seamless stakeholder communication, and execute systematic workflow coordination throughout project lifecycles. Each SDLC phase addresses specific operational objectives, from comprehensive requirement analysis and architectural solution design to proactive security vulnerability identification and risk mitigation strategies. By adhering to structured development methodologies, software engineers consistently deliver robust, functional, and secure applications that withstand the demanding requirements of today's rapidly evolving digital ecosystem and technological landscape.
The SDLC framework ultimately enables organizations to achieve consistent high-quality software delivery, minimize operational risks, and ensure every product release aligns strategically with both organizational business objectives and end-user requirements while optimizing development efficiency and maintaining competitive advantage in the marketplace.
The SDLC is a systematic, iterative, and structured method for application development. It guides teams through the stages of planning, analysis, design, development, testing, deployment, and maintenance, ensuring a comprehensive approach to building software. Each SDLC phase is a discrete, sequential step with clearly defined objectives and requirements, helping to prevent issues such as scope creep and technical debt while ensuring quality delivery. The feasibility analysis phase evaluates whether the project is technically and financially viable, assessing technical requirements and estimating costs. Developers are the first line of defense and play the most critical, hands-on role in maintaining SDLC security.
There are various SDLC models to consider, each offering unique benefits. The waterfall model follows a linear approach, the spiral model incorporates risk analysis, and the Agile model emphasizes flexibility and rapid iteration. The waterfall model may be less suitable for complex projects that require frequent changes, so selecting the right model should take project complexity into account.
Adopting an SDLC structure allows teams to:
By providing these critical frameworks and processes, the SDLC ensures that software development projects remain on track and deliver exceptional results.
Adopting cutting-edge SDLC best practices that improve productivity, security, and overall project performance is essential in the cutthroat world of software development. The seven core best practices that are essential for achieving excellence in software development are covered in this guide. These practices ensure that your projects always receive the most optimal results. Let’s dive into the seven SDLC best practices.
This is an essential step for development teams. A thorough planning and requirement analysis phase forms the basis of any successful software project.
Start by defining the scope and objectives of the project. Keep a thorough record of your expectations, limitations, and ambitions. This guarantees everyone is on the same page and lessens the possibility of scope creep.
Engage stakeholders right away. Understanding user wants and expectations greatly benefits from their feedback. Refinement of needs is assisted by ongoing input and engagement with stakeholders. Documenting functional and non-functional requirements in a Software Requirement Specification (SRS) minimizes ambiguity and scope creep.
Conduct thorough market research to support your demand analysis. Recognize the preferences of your target market and the amount of competition in the market. This information influences the direction and feature set of your project.
Make a thorough strategy that includes due dates, milestones, and resource allocation. Your team will be more effective if you have a defined strategy that serves as a road map so that each member is aware of their duties and obligations. Also, ensure that there is effective communication within the team so that everyone is aligned with the project plan.
Enhances Reliability and Trust:
Planning accuracy is crucial because it establishes trust within an organization. When an engineering team reliably delivers on their commitments, it builds confidence among other departments, such as sales and marketing. This synchronization ensures that all branches of a company are working efficiently towards common business goals.
Improves Customer Satisfaction:
Timely delivery of new products and features is key to maintaining high customer satisfaction. When engineering teams meet deadlines consistently, customers receive updates and innovations as expected. This reliability enhances user experience and reduces the risk of customer churn.
Facilitates Cross-Departmental Alignment:
Accurate planning allows different departments to align their strategies effectively. When engineering timelines are dependable, marketing can plan campaigns, and sales can set realistic expectations. This collaboration creates a cohesive operational flow that benefits the company as a whole.
Boosts Renewal and Retention Rates:
Delivering products on schedule can lead to higher renewal rates and client retention as satisfied customers are more likely to continue their business relationship. Trust in delivery timelines reassures customers that they can rely on future commitments.
In essence, planning accuracy is not just a technical necessity; it is a strategic advantage that can propel an entire organization towards success by enhancing trust, satisfaction, and operational harmony.
Agile methodologies, which promote flexibility and teamwork, such as Scrum and Kanban, have revolutionized software development. Agile methodologies are particularly well-suited for software projects that require flexibility and rapid iteration. In the agile model, the team members are the heartbeat of this whole process. It fosters an environment that embraces collaboration and adaptability.
Apply a strategy that enables continual development. Thanks to this process, agile team members can respond to shifting requirements and incrementally add value.
Teams made up of developers, testers, designers, and stakeholders should be cross-functional. Collaboration across diverse skill sets guarantees faster progress and more thorough problem-solving.
Implement regular sprint reviews during which the team displays its finished products to the stakeholders. The project will continue to align with shifting requirements because of this feedback loop.
Use agile project management tools like Jira,Trello to aid in sprint planning, backlog management, and real-time collaboration. These tools enhance transparency and expedite agile processes.
Security is vitally important in today’s digital environment as a rise in security issues can result in negative consequences. To address these challenges, it is essential to implement robust security and security practices throughout the Software Development Lifecycle (SDLC). It is also necessary to systematically integrate security into each phase of the SDLC, ensuring that protective measures are embedded from planning through deployment and maintenance. Integrating security throughout the SDLC is the most effective way to reduce Software Supply Chain risk because the supply chain is fundamentally composed of the tools, code, and processes within the SDLC itself. Integrating security into all phases of the SDLC helps address software vulnerabilities and prevent data breaches by embedding protective measures from the outset. Adapting security measures to the evolving threat landscape is also crucial to ensure ongoing resilience against new and emerging threats. Regularly updating the SDLC to incorporate new security practices, tools, and threat intelligence is essential to ensure that it remains effective in mitigating risks. Hence, adopting security best practices ensures prioritizing security measures and mitigating risks.
Early on in the development phase, a threat modeling step should be conducted, and you should approach potential security risks and weaknesses head-on. It helps in identifying and addressing security vulnerabilities before they can be exploited.
Integrate continuous security testing into the whole SDLC. Integrated components should include both manual penetration testing and automated security scanning. Incorporating static application security testing (SAST) as part of the security testing process helps identify vulnerabilities early in the development lifecycle. Security flaws must be found and fixed as soon as possible.
Keep up with recent developments and security threats. Participate in security conferences, subscribe to security newsletters, and encourage your personnel to take security training frequently.
Analyze and protect any third-party libraries and parts used in your product. Leaving third-party code vulnerabilities unfixed can result in serious problems.
In the digital landscape, data serves as the backbone of any software infrastructure. From handling customer information to analyzing application performance, data is at the core of operations. Protecting this data isn't just a technical necessity—it's a business imperative. However, there's a critical aspect often overlooked: the cleanliness and accuracy of data associated with engineering processes.
With the rise of methodologies like DevOps, engineering teams have become more attuned to collecting and analyzing metrics to enhance productivity and efficiency. These metrics, often influenced by frameworks like the DORA principles, help teams understand their performance and identify areas for improvement. However, the usefulness of such metrics depends entirely on the quality of the data.
Here's why maintaining data hygiene matters:
In Conclusion
Ensuring your engineering data remains pristine is as vital as securing customer and application data. By focusing on data hygiene, software development teams can achieve more consistent, reliable, and efficient outcomes, driving the success of both their projects and their organizations.
For timely software delivery, an effective development and deployment process is crucial. The deployment phase involves moving software from the development environment to production and preparing it for end-user access, with careful monitoring and fine-tuning during deployment. CI/CD pipelines facilitate collaboration among multiple developers by automating code integration, testing, and deployment, making it easier for teams to work simultaneously on a project. Not only this, software testing plays a crucial role in ensuring the quality and application of the software. Testing code as part of the CI/CD workflow is essential to maintain quality and streamline deployment. Writing code efficiently is fundamental in the implementation phase, and integrating it with automated development and deployment practices helps maintain high standards throughout the software development lifecycle.
Automate code testing, integration, and deployment with Continuous Integration/Continuous Deployment (CI/CD) pipelines. As a result, the release cycle is sped up, errors are decreased, and consistent software quality is guaranteed. Application security testing can be seamlessly integrated into CI/CD pipelines to mitigate security vulnerabilities during the testing phase.
Use orchestration with Kubernetes and tools like Docker to embrace containerization. Containers isolate dependencies, guaranteeing consistency throughout the development process.
To manage and deploy infrastructure programmatically, apply Infrastructure as Code (IaC) principles. Automating server provisioning with programs like Terraform and Ansible may ensure consistency and reproducibility.
A/B testing and feature flags are important components of your software development process. These methods enable you to gather user feedback, roll out new features to a select group of users, and base feature rollout choices on data.
Beyond these best practices, optimizing developer workflows is crucial for enhancing productivity. Streamlining the day-to-day tasks developers face can significantly reduce time spent on non-essential activities and improve focus.
Incorporate tools that bring functionality directly into the developer's environment, reducing the need for constant context switching. By having capabilities like issue creation and code review embedded within platforms such as Slack or IDEs, developers can maintain their workflow without unnecessary interruptions.
Automating routine, repetitive tasks can free up developers to concentrate on more complex problem-solving and feature development. This includes automating code reviews, testing processes, and even communication with team members for status updates.
To pinpoint cycle time bottlenecks, teams need to start by monitoring their development process closely. Tools that track planning accuracy offer valuable insights. These tools can highlight the stages where delays frequently occur, enabling teams to investigate further.
Once a bottleneck is suspected, break down the development pipeline into distinct phases. By examining each step, from coding to testing, teams can identify where the process slows down. Regularly reviewing these phases helps in understanding the effect of each stage on overall delivery times.
Utilizing cycle time metrics is key. These metrics provide a window into the efficiency of your development process. A spike in cycle time often signals a bottleneck, prompting a deeper dive to diagnose the root cause.
Delve into the data to unravel specific issues causing delays. Compare the anticipated timeline against actual delivery times to spot discrepancies. This comparison often uncovers the unforeseen obstacles slowing progress.
Once the cause is identified, implement targeted solutions. This might involve redistributing resources, optimizing workflows, or introducing automation where necessary. Continuous monitoring ensures that the implemented solutions effectively address the identified bottlenecks.
Finally, it's crucial to continually refine these processes. Regular feedback loops and iterative improvements will help keep the development pipeline smooth, ensuring timely and efficient deliveries across the board.
Software must follow stringent testing requirements and approved coding standards to be trusted. Establishing a standardized code review process is essential to improve review efficiency, reduce lead times, and enhance overall code quality. Maintaining software is also critical, requiring ongoing support, updates, and security measures to ensure continued functionality, security, and compliance. Writing secure code is a key part of code quality best practices, helping to prevent vulnerabilities throughout the Software Development Lifecycle (SDLC).
Compliance with industry-specific regulations and standards is crucial, and adherence to these standards should be a priority so that the final product meets all necessary compliance criteria.
To preserve code quality and encourage knowledge sharing, regular code reviews should be mandated. Use static code analysis tools to identify potential problems early.
How Does Pull Request (PR) Size Affect Review Time?
The size of a pull request (PR) plays a critical role in determining how quickly it undergoes the review process. Research indicates that smaller PRs are typically reviewed more swiftly than larger ones. This largely stems from the fact that smaller PRs are easier for reviewers to digest and assess, leading to a more efficient review process.
Key Factors:
Strategies to Improve Review Time:
By focusing on reducing the size and complexity of pull requests, teams can enhance their efficiency and shorten development cycles, leading to faster delivery of features and fixes.
A large collection of automated tests should encompass unit, integration, and regression testing. Automating the process of making code modifications can prevent new problems from arising.
To monitor the evolution of your codebase over time, create metrics for code quality. The reliability, security, and maintainability of a piece of code can be determined using TypoSonarQube and other technologies. Certainly! When assessing code quality through the lens of DORA metrics, two key indicators come into play:
Both metrics emphasize the impact of code quality on system stability and user experience, capturing how efficiently teams can address and resolve issues when their code falls short.
Use load testing as part of your testing process to ensure your application can manage the expected user loads. The next step is performance tuning after load testing. Performance optimization must be continuous to improve your application's responsiveness and resource efficiency.
For collaboration and knowledge preservation in software teams, efficient documentation and version control are essential. Proper version control and access management help prevent code leaks and protect against unauthorized users accessing sensitive information. Proper documentation integrated with version control is essential for a reliable development process.
Use version control systems like Git to manage codebase changes methodically. Use branching approaches to create well-organized teams.
In software development, a significant challenge arises from branches that lack association with specific tasks, issues, or user stories. These unlinked branches can create confusion about their purpose and how they align with the product's overall direction.
Key Issues with Unlinked Branches:
By addressing the issue of unlinked branches, teams can improve transparency, enhance collaboration, and streamline their development processes, ensuring every piece of code has a clear purpose and destination.
Maintain up-to-date user manuals and technical documentation. These tools promote transparency while facilitating efficient maintenance and knowledge transfer.
The use of "living documentation" techniques, which automatically treat documentation like code and generate it from source code comments, is something to consider. This guarantees that the documentation is current when the code is developed.
Establish for your teams a clear Git workflow that considers code review procedures and branching models like GitFlow. Collaboration is streamlined by using consistent version control procedures.
By harmonizing these practices with tools that enhance individual developer workflows, such as integrated environments and task automation, your software development process can achieve unparalleled efficiency and innovation.
Long-term success depends on your software operating at its best and constantly improving.
Testing should be integrated into your SDLC. To improve resource utilization, locate and fix bottlenecks. Assessments of scalability, load, and stress are essential.
To acquire insights into application performance implement real-time monitoring and logging as part of your deployment process. Proactive issue detection reduces the possibility of downtime and meets user expectations. Performance monitoring and security scanning tools help proactively identify issues and track metrics post-deployment.
Identify methods for gathering user input. User insights enable incremental improvements by adapting your product to changing user preferences.
Implement error tracking and reporting technologies to get more information about program crashes and errors. Maintaining a stable and dependable software system depends on promptly resolving these problems.
Software development lifecycle methodologies are structured frameworks used by software development teams to navigate the SDLC.
There are various SDLC methodologies. Each has its own unique approach and set of principles. Check below:
According to this model, software development flows linearly through various phases: requirements, design, implementation, testing, deployment, and maintenance. There is no overlapping and any phase can only initiate when the previous one is complete.
Although, DevOps is not traditionally an SDLC methodology, but a set of practices that combines software development and IT operations. DevOps' objective is to shorten the software development lifecycle and enhance the relevance of the software based on users' feedback.
Although it has been mentioned above, Agile methodology breaks a project down into various cycles. Each of them passes through some or all SDLC phases. This methodology also incorporates users' feedback throughout the project.
It is an early precursor to Agile and emphasizes iterative and incremental action. The iterative model is beneficial for large and complex applications.
An extension of the waterfall model, this model is named after its two key concepts: Validation and Verification. It involves testing and validation in each software development phase so that it is closely aligned with testing and quality assurance activities.
How does one successfully orchestrate the development lifecycle to achieve optimal outcomes? The answer lies in leveraging a comprehensive approach that transforms collaboration between developers, project managers, and security teams across every phase. The process commences with an intensive planning phase, where development teams analyze project requirements, establish clear objectives, and proactively identify potential security risks through data-driven assessment techniques. This early emphasis on risk management establishes the foundation for a secure and streamlined development process that anticipates future challenges and optimizes resource allocation.
How do developers ensure security integration throughout implementation? During the development phase, developers implement code with rigorous adherence to secure coding practices and automated quality checks. By embedding security protocols into the development workflow from inception, teams dramatically minimize the probability of introducing security vulnerabilities that could compromise system integrity in production environments. The testing phase proves equally transformative, as it empowers teams to rigorously validate software functionality, identify and remediate bugs through intelligent analysis, and ensure the product meets deployment readiness criteria for production environment transition.
What impact do continuous integration and continuous deployment (CI/CD) have on modern development cycles? These methodologies have become fundamental practices that revolutionize the development lifecycle, enabling teams to automate testing protocols, streamline code integration processes, and deliver updates with unprecedented velocity while maintaining stringent quality and security standards. By adopting these AI-enhanced practices, organizations optimize their development lifecycle velocity while ensuring every release demonstrates robust performance, comprehensive security, and strategic alignment with business objectives.
How does effective development lifecycle management transform software delivery? Strategic management of the development lifecycle not only facilitates early bug remediation and security vulnerability mitigation but also cultivates an organizational culture centered on secure coding practices and continuous improvement methodologies. This comprehensive approach ensures software development teams consistently deliver high-quality, secure applications that adapt to the evolving requirements of users and stakeholders while optimizing performance and maintaining competitive advantage.
Technical expertise and process improvement are required on the route to mastering advanced SDLC best practices. These techniques can help firms develop secure, scalable, high-quality software solutions. Due to their originality, dependability, and efficiency, these solutions satisfy the requirements of the contemporary business environment.
If your company adopts best practices, it can position itself well for future growth and competitiveness. By taking software development processes to new heights, one can discover that superior software leads to superior business performance.
How does mastering the software development life cycle transform organizational capabilities in producing high-quality, secure, and reliable software? By leveraging comprehensive SDLC methodologies—encompassing requirement analysis, secure coding practices, automated testing frameworks, and continuous integration/continuous deployment (CI/CD) pipelines—development teams can optimize their workflows, mitigate security vulnerabilities, and consistently exceed customer expectations. AI-driven tools analyze historical data patterns to predict potential bottlenecks, while automated code analysis identifies security vulnerabilities and enforces coding standards across all development phases.
What impact does a structured approach to the software development lifecycle have on organizational agility and resilience? A methodical SDLC framework not only enhances project management through predictive analytics and code quality through automated testing but also positions organizations to respond dynamically to evolving requirements and emerging security threats. Machine learning algorithms analyze deployment data to predict potential issues, while AI-powered tools facilitate automated rollback mechanisms and optimize resource allocation. As the digital landscape continues to evolve, prioritizing robust SDLC processes—including microservices architecture, service mesh intelligence, and Infrastructure as Code (IaC) optimization—will empower teams to deliver innovative solutions, maintain competitive advantages, and drive sustainable business growth.
How can organizations ensure their software development efforts result in products that withstand today's complex security challenges? By committing to continuous improvement methodologies and integrating security-by-design principles at every SDLC stage—from requirement gathering through deployment and maintenance—organizations can ensure that their software development initiatives produce applications that are not only functionally efficient but also resilient against sophisticated security threats. AI-enhanced anomaly detection systems monitor CI/CD pipelines, while automated environment synchronization reduces configuration drift between development, staging, and production environments, creating a foundation for reliable, scalable software solutions.
The implementation phase represents a transformative gateway in the software development life cycle (SDLC), where meticulously crafted visions and comprehensive requirements established during strategic planning metamorphose into dynamic, fully-functional applications that drive business innovation. Throughout this critical stage, development teams leverage cutting-edge coding practices and advanced technological frameworks to architect robust solutions that breathe life into project specifications, ensuring that the resulting software ecosystem not only aligns with evolving customer expectations but also propels strategic business objectives forward with unprecedented efficiency and scalability. A masterfully executed implementation phase becomes the cornerstone for delivering enterprise-grade software that demonstrates remarkable resilience, seamless scalability, and optimal readiness for comprehensive testing protocols and production deployment scenarios. By strategically focusing on industry best practices and leveraging AI-driven development methodologies throughout the entire development life cycle SDLC, cross-functional teams can dramatically minimize coding errors, substantially reduce resource-intensive rework cycles, and consistently deliver transformative solutions that authentically address complex user requirements while anticipating future technological demands and market trajectories.
Throughout the implementation phase, development teams dive into comprehensive activities strategically orchestrated to guarantee that software applications achieve both optimal functionality and robust security posture. The fundamental emphasis centers on crafting clean, maintainable code that seamlessly adheres to secure coding practices—a critical foundation for preventing security vulnerabilities and delivering resilient software solutions. Development teams should leverage static application security testing (SAST) tools to swiftly identify and proactively address security risks during the early development cycle phases, significantly reducing the likelihood of resource-intensive fixes that emerge later in the process. Establishing clear coding standards ensures consistency, readability, and maintainability across the development team. Regular code reviews serve as essential checkpoints that maintain superior code quality standards, foster collaborative knowledge sharing among team members, and strategically prevent the accumulation of technical debt that can compromise long-term project sustainability. Regular training on secure coding practices is essential for developers to build resilient software against common vulnerabilities. By seamlessly integrating application security testing methodologies into their development workflows, teams can proactively tackle potential security challenges and ensure that software applications remain consistently resilient against continuously evolving cybersecurity threats and attack vectors.
Optimizing collaborative frameworks and facilitating comprehensive communication channels comprise the foundational architecture for streamlining successful implementation methodologies. Development team constituents must leverage integrated workflows, synthesizing domain insights and iterative feedback mechanisms to ensure the codebase architecture maintains structural integrity, enhanced readability protocols, and simplified maintenance paradigms. Systematically orchestrated stakeholder engagements, progressive status synchronization processes, and diversified communication pathways facilitate the mitigation of interpretative discrepancies while ensuring optimal alignment with strategic project objectives. Implementing advanced project management frameworks enables development teams to systematically monitor task trajectories, analyze progression metrics, and rapidly identify potential implementation bottlenecks that may emerge throughout the development lifecycle. This collaborative methodology not only streamlines the implementation workflow optimization but also cultivates an organizational culture emphasizing accountability frameworks and continuous process enhancement methodologies within the development team ecosystem.
Monitoring progress and achieving key milestones transform the implementation phase into a data-driven powerhouse that drives software excellence. Development teams harness powerful metrics such as cycle time, lead time, and code quality indicators to assess their performance and uncover hidden improvement opportunities that can revolutionize their delivery capabilities. Incorporating regular integration testing and comprehensive system testing empowers teams to detect bugs and security incidents early in the development lifecycle, significantly reducing the risk of issues escalating into catastrophic security breaches that could compromise entire systems. By addressing problems promptly and systematically, teams maintain unstoppable momentum while ensuring that the software meets all required standards and exceeds stakeholder expectations. The strategic adoption of continuous integration and continuous deployment (CI/CD) pipelines, powered by tools like Jenkins, GitLab CI, and Azure DevOps, fundamentally enhances the development process by enabling rapid feedback loops, automated testing frameworks, and seamless delivery of code changes that flow effortlessly from development to production. This transformative approach not only accelerates the implementation phase dramatically but also strengthens the overall security posture and reliability of the software as it progresses toward production environments, creating a robust foundation for scalable, maintainable applications.

Code reviews are the cornerstone of ensuring code quality, fostering a collaborative relationship between developers, and identifying potential code issues in the primitive stages.
To do this well and optimize the code review process, a code review checklist is essential. It can serve as an invaluable tool to streamline evaluations and guide developers.
Let’s explore what you should include in your code reviews and how to do it well.
50% of the companies spend 2-5 hours weekly on code reviews. You can streamline this process with a checklist, and developers save time. Here are eight criteria for you to check for while conducting your code reviews with a code review tool or manually. It will help to ensure effective code reviews that optimize both time and code quality.
A complicated code is not helpful to anyone. Therefore, while reviewing code, you must ensure readability and maintainability. This is the first criterion and cannot be overstated enough.
The code must be orchestrated into well-defined modules, functions, and classes. Each of them must carry a unique role in the bigger picture. You can employ naming conventions for each component to convey its purpose, ensuring code changes are easily understood and the purpose of the different components at a glance.
A code with consistent indentation, spacing, and naming convention is easy to understand. To do this well, you should enforce a standard format that minimizes friction between team members who have their own coding styles. This will ensure a consistent code across the team.
By adding in-line comments and documentation throughout the code, you will help explain the complex logic, algorithms, and business rules. Coders can use this opportunity to explain the ‘why’ behind the coding decisions and not only explain ‘how’ something is done. It adds context and makes the code-rich in information. When your codebase is understandable to the current team members and future developers who would handle it – you pave the way for effective collaboration and long-standing code. Hence, facilitating actionable feedback and smoother code change.
No building is secure without a solid foundation – the same logic applies to a codebase. The code reviewer has to check for scalability and sustainability, and a solid architectural design is imperative.
Partition of the code into logical layers encompassing presentation, business logic, and data storage. This modular structure enables easy code maintenance, updates, and debugging.
In software development, design patterns are a valuable tool for addressing recurring challenges consistently and efficiently. Developers can use established patterns to avoid unnecessary work, focus on unique aspects of a problem, and ensure reliable and maintainable solutions. A pattern-based approach is especially crucial in large-scale projects, where consistency and efficiency are critical for success.
Code reviews have to ensure meticulous testing and quality assurance processes. This is done to maintain high test coverage and quality standards.
When you test your code, it's essential to ensure that all crucial functionalities are accounted for and that your tests provide comprehensive coverage.
You should explore extreme scenarios and boundary conditions to identify hidden problems and ensure your code behaves as expected in all situations, meeting the highest quality standards.
Ensuring security and performance in your source code is crucial in the face of rising cyber threats and digital expansion, making valuable feedback a vital part of the process.
Scrutinize the user inputs that check for security vulnerabilities such as SQL injection. Check for the input of validation techniques to prevent malicious inputs that can compromise the application.
If the code performance becomes a bottleneck, your application will suffer. Code reviews should look at the possible bottlenecks and resource-intensive operations. You can utilize the profiling tools to identify them and look at the sections of the code that are possibly taking up more resources and could slow down the application.
When code reviews check security and performance well, your software becomes effective against potential threats.
OOAD principles offer the pathway for a robust and maintainable code. As a code reviewer, ensuring the code follows them is essential.
When reviewing code, aim for singular responsibilities. Look for clear and specific classes that aren't overloaded. Encourage developers to break down complex tasks into manageable chunks. This leads to code that's easy to read, debug, and maintain. Focus on guiding developers towards modular and comprehensible code to improve the quality of your reviews.
It's important to ensure that derived classes can seamlessly replace base classes without affecting consistency and adaptability. To ensure this, it's crucial to adhere to the Liskov Substitution Principle and verify that derived classes uphold the same contract as their base counterparts. This allows for greater flexibility and ease of use in your code.
Beyond mere functionality, non-functional requirements define a codebase's true mettle:
While reviewing code, you should ensure the code is self-explanatory and digestible for all fellow developers. The code must have meaningful variable and function names, abstractions applied as needed, and without any unnecessary complications.
When it comes to debugging, you should carefully ensure the right logging is inserted. Check for log messages that offer context and information that can help identify any issues that may arise.
A codebase should be adaptable to any environment as needed, and a code reviewer has to check for the same.
A code reviewer should ensure the configuration values are not included within the code but are placed externally. This allows for easy modifications and ensures that configuration values are stored in environment variables or configuration files.
A code should ideally perform well and consistently across diverse platforms. A reviewer must check if the code is compatible across operating systems, browsers, and devices.When the code can perform well under different environments, it improves its longevity and versatility.
The final part of code reviewers is to ensure the process results in better collaboration and more learning for the coder.
Good feedback helps the developer in their growth. It is filled with specific, actionable insights that empower developers to correct their coding process and enhance their work.
Code reviews should be knowledge-sharing platforms – it has to include sharing of insights, best practices, and innovative techniques for the overall developer of the team.
A code reviewer must ensure that certain best practices are followed to ensure effective code reviews and maintain clean code:
Hard coding shouldn’t be a part of any code. Instead, it should be replaced by constants and configuration values that enhance adaptability. You should verify if the configuration values are centralized for easy updates and if error-prone redundancies are reduced.
The comments shared across the codebase must focus on problem-solving and help foster understanding among teammates.
Complicated if/else blocks and switch statements should be replaced by succinct, digestible frameworks. As a code reviewer, you can check if the repetitive logic is condensed into reusable functions that improve code maintainability and reduce cognitive load.
A code review should not include cosmetic concerns; it will efficiently use your time. Use a tool to manage these concerns, which can be predefined with well-defined coding style guides.
For further reference, here are some cosmetic concerns:
Functional flaws of the code should not be reviewed separately as this leads to loss of time and manual repetition. The reviewer can instead trust automated testing pipelines to carry out this task.
Enforcing coding standards and generating review notifications should also be automated, as repetitive tasks enhance efficiency.
As a code reviewer, you should base your reviews on the established team and organizational coding standards. Imposing the coding standards that you personally follow should not serve as a baseline for the reviews.
Reviewing a code can sometimes lead to the practice of striving for perfection. Overanalyzing the code can lead to this. Instead, as a code reviewer, you can focus on improving readability and following the best practices.
The process of curating the best code review checklist lies in ensuring alignment of readability, architectural finesse, and coding best practices with quality assurance. Hence, promoting code consistency within development teams.
This enables reviewers to approve code that performs well, enhances the software, and helps the coder in their career path. This collaborative approach paves the way for learning and harmonious dynamics within the team.
Typo, an intelligent engineering platform, can help in identifying SDLC metrics. It can also help in detecting blind spots which can ensure improved code quality.

Agile practices enable businesses with adaptability and help elevate their levels of collaboration and innovation. At the beginning of any agile initiative, establishing clear collaboration guidelines is essential. Especially when changing landscapes in tech, agile working models are a cornerstone for businesses in navigating through it all.
Therefore, agile team working agreements are crucial to successfully understand what fuels this collaboration. Many teams refer to these as team contracts or team rules, and the whole team should participate in creating them. Another common term is 'ground rules,' which highlights the importance of collaboratively deciding on the guidelines that will shape team interactions. The process involves the team deciding together on the working methods and expected behaviors, rather than simply following rules imposed by a leader. They serve as the blueprint for agile team members and enable teams to function in tandem.
It is important to have these working agreements documented for easy reference and consistency.
In this blog, we discuss the importance of working agreements, best practices, how to create working agreements, and more.
Agile teams are a fundamental component of agile development methodologies. These are cross-functional teams of individuals responsible for executing agile projects. Both scrum teams and other project teams benefit from establishing a team working agreement to set clear expectations and promote effective collaboration. A Scrum team collaboratively creates, facilitates, and regularly revises its working agreement to guide team behavior and foster effective collaboration within the Agile Scrum framework.
The team size is usually ranging from 5 to 9 members. It is chosen deliberately to foster collaboration, effective communication, and flexibility. They are autonomous and self-organizing teams that prioritize customer needs and continuous improvement. Often guided by an agile coach, they can deliver incrementally and adapt to changing circumstances. Selecting a team name is an important step in developing team identity and fostering a strong team culture, and involving everyone in a collaborative process to choose a meaningful team name helps build a sense of belonging.
Agile team working agreements are guidelines that outline how an agile team should operate. These agreements are often based on Scrum values and require that the team agrees on shared expectations and behaviors. They dictate the norms of communication and decision-making processes and define quality benchmarks. Defined processes like a Definition of Done are essential in an agile working agreement to ensure quality and clarity.
This team agreement facilitates a shared understanding and manages expectations, fostering a culture aligned with Agile values and team norms. Expectation setting is a key part of the process, and each person on the team should contribute to the agreement. This further enables collaboration across teams. In the B2B landscape, such collaboration is essential as intricate projects require several experts in cross-functional teams to work harmoniously together towards a shared goal.
Agile Team Working Agreements are crucial for defining specific requirements and rules for cooperation. Let’s explore some further justifications for why they are vital:
Working agreements can aid in fostering openness and communication within the team. When everyone is on the same page on how to collaborate, productivity and efficiency rise. Working agreements also help teams communicate more effectively by clarifying communication channels, standards, and escalation processes.
Agile Team Working Agreements can encourage a culture of continuous improvement because team members can review and amend the agreement over time. Regularly reviewing agreements ensures the process works for the team and remains effective as needs evolve. This ongoing review helps the team adapt and optimize their practices for the future, preparing them to meet upcoming challenges and continuously improve.
Architecting a robust team identity framework constitutes a fundamental infrastructure component in establishing high-performance working agreements within agile development ecosystems. When cross-functional development teams converge, stakeholders must systematically engineer a shared computational model of their collective mission parameters, operational values, and preferred workflow methodologies. One scalable implementation approach involves deploying distributed brainstorming algorithms where individual team members independently generate conceptual data points regarding team positioning, subsequently aggregating these inputs through collaborative synthesis protocols. This iterative processing methodology facilitates the instantiation of a distinctive team namespace identifier, which not only serves as a symbolic unity token but also optimizes psychological ownership metrics and pride-based performance indicators across all team member nodes.
Beyond the namespace configuration, establishing deterministic operational protocols and normative behavioral patterns becomes critical for optimizing daily collaborative throughput. This encompasses defining temporal availability windows that accommodate distributed team member scheduling constraints, particularly when dealing with geographically dispersed development resources across multiple timezone parameters. The working agreement outlines working hours and availability, ensuring consistency and transparency. Implementing standardized communication channel architectures—such as Microsoft Teams integration—ensures universal connectivity protocols and streamlined interaction pathways, thereby enhancing daily communication efficiency while minimizing cognitive overhead and distraction vectors. To further minimize distractions and enhance focus and collaboration, teams can adopt strategies such as pairing and swarming, which help reduce interruptions and foster more productive teamwork. Configuring mutual expectation matrices around responsiveness thresholds, availability parameters, and participation metrics further amplifies the team’s computational collaboration capacity.
By systematically optimizing these foundational infrastructure components, development teams can architect collaborative environments that facilitate transparent communication channels, reinforce agile methodology principles, and establish scalable frameworks for high-efficiency teamwork execution. Well-architected team identity schemas and precisely-defined operational governance models enable comprehensive stakeholder integration and accountability optimization, thereby streamlining shared objective achievement protocols and enhancing adaptive capacity for emerging challenge vectors as they propagate through the development lifecycle.
Working agreements should be a collaborative process, ideally facilitated by someone who can guide the team and ensure everyone is involved to get different perspectives. Here are some steps to follow: Encourage all team members to share any idea, even if it seems unconventional, to foster creativity and inclusivity. Team members brainstorm together to propose new ideas or adjustments to the working agreement, especially when adapting to remote or hybrid work arrangements. Setting mutual agreements during workshops helps create ownership of the working agreements. When creating effective working agreements, it’s important to consider different preferences among team members to ensure everyone’s needs are addressed.
Gather all team members; the scrum master, product owner, and all other stakeholders.
Observing how other teams assemble for working agreement sessions can also provide useful insights.
Once you have the team, encourage everyone to share their thoughts and ideas about the team, the working styles, and the dynamics within the team. Ask them for areas of improvement and ensure the Scrum Master guides the conversation for a more streamlined flow in the meeting.
To help keep the discussion focused, consider using a parking lot to set aside unrelated topics or ideas for later review.
During retrospectives, identify the challenges or issues from the previous sprints. Discuss how they propose to solve such challenges from coming up again through the working agreements.
Additionally, when a new task is introduced, challenges may arise in managing and integrating it into the workflow, so the team should address how to handle these situations in the working agreement.
Once you’ve heard the challenges and suggestions, propose the potential solutions you can implement through the working agreements and ensure your team is on board with them. These agreements must support the team‘s goals and improve collaboration.
You can then test these proposed solutions in the next sprint to evaluate their effectiveness and make adjustments as needed.
Write the agreed-upon working agreements clearly in a document, and ensure these working agreements are included in the team's official documents. Make sure the document is accessible to all the team members physically or as a digital resource.
To create effective working agreements—also known as collaboration guidelines—you must also know what goes into it and the different aspects to cover. Here are five components to be included in the agreement.
Outline how you would like the decorum of the team members to be – establishing clear team rules helps define expected behaviors and ensures the culture of the team and company is consistently upheld. Nurture a culture of active listening, collaborative ideation, and commitment to their work. Ensure professionalism is mentioned.
Once you have the team, encourage everyone to share their thoughts and ideas about the team, the working styles, and the dynamics within the team. Ask them for areas of improvement and ensure the Scrum Master guides the conversation for a more streamlined flow in the meeting. Using open-ended questions can help guide teams in developing their working agreements.
A virtual whiteboard can be used to visualize, collaboratively create, and update the team's working agreements, making them easily accessible and transparent for all members.
Establish communication guidelines, including but not limited to preferred channels, frequencies, and etiquette, to ensure smooth conversations. Clear standards for how team members communicate—including which channels to use, how often to share updates, and escalation processes—are essential. The agile working agreement clarifies expectations for behavior and processes such as feedback provision and conflict handling. Clear communication is the linchpin of successful product building and thus makes it an essential component.
Set the tone for meetings with structured agendas, time management, and participation guidelines that enable productive discussions. Additionally, defining meeting times and duration helps synchronize schedules better.
Clear decision-making is crucial in B2B projects with multiple stakeholders. Transparency is critical to avoiding misunderstandings and ensuring everyone's needs and team goals are met.
To maintain a healthy work environment, encourage open communication and respectful disagreement. When conflicts arise, approach them constructively and find a solution that benefits all parties. Consider bringing in a neutral third party or establishing clear guidelines for conflict resolution. Conflict resolution is an integral part of the agile working agreement, defining processes for addressing disagreements constructively. This helps complex B2B collaborations thrive.
Leveraging streamlined communication frameworks and sophisticated collaborative infrastructures constitutes the foundational architecture of any high-performing agile development ecosystem. When architecting comprehensive working agreements, organizations must systematically define and optimize which communication channels and collaborative platforms the development teams will utilize for seamless daily interactions, stakeholder engagements, and comprehensive project orchestration.
Whether development teams gravitate toward Microsoft Teams for integrated chat functionalities and video conferencing capabilities, Slack for rapid-response communication protocols, or Google Workspace for distributed document collaboration and knowledge management, the critical success factor lies in ensuring organizational alignment across all chosen technological platforms and communication vectors.
The working agreement framework should comprehensively delineate explicit expectations and operational guidelines governing the strategic implementation and temporal utilization of these sophisticated collaborative tools. For instance, development teams might establish standardized protocols to utilize Microsoft Teams for all project-centric discussions and stakeholder communications, implement performance metrics for message response timeframes and communication latency, and specify optimal scenarios for deploying video conferencing solutions versus asynchronous written documentation and status updates. Establishing these foundational operational norms facilitates the elimination of communication ambiguities, ensures comprehensive information dissemination and knowledge transfer, and supports highly efficient daily communication workflows and team synchronization.
Additionally, the comprehensive agreement framework should systematically address organizational preferences for meeting optimization strategies—including strategic decisions regarding whether to conduct daily stand-up ceremonies through virtual platforms or traditional in-person methodologies—and establish clear expectations for meeting scheduling protocols, notification systems, and stakeholder engagement practices.
Through systematic discussion and comprehensive documentation of these operational preferences and communication protocols, agile development teams can architect highly collaborative environments where every team member possesses clear understanding of communication pathways, anticipated response timeframes, and methodologies for maintaining continuous connectivity and engagement, regardless of geographical distribution or temporal zone constraints.
Ultimately, through the strategic definition and optimization of communication channels and collaborative tool ecosystems within the working agreement framework, development teams can cultivate unprecedented transparency levels, streamline operational workflows and process automation, and ensure that every team member is systematically empowered and equipped to contribute effectively toward achieving the team's strategic objectives and deliverable milestones.
In agile environments, scrum events function as critical optimization touchpoints that drive unprecedented progress, strategic alignment, and transformative continuous improvement initiatives. When architecting a comprehensive working agreement, teams must strategically integrate these high-impact ceremonies—including sprint planning, sprint review, and sprint retrospective—into streamlined workflow processes.
The collaborative unit should leverage collective intelligence to determine optimal frequency parameters and duration specifications for each ceremonial touchpoint, while establishing robust expectations for comprehensive team member engagement. For instance, organizations may implement daily stand-up synchronization sessions to analyze progress trajectories, eliminate operational blockers, and optimize daily priority hierarchies.
The scrum master leverages facilitative leadership to orchestrate these transformative events, ensuring maximum productivity outcomes while upholding the team's strategic working agreement framework. Throughout sprint planning ceremonies, the collaborative unit harnesses collective expertise to curate user stories from the comprehensive product backlog, architect the sprint backlog infrastructure, and delineate precise accountability matrices for each team participant.
The sprint review delivers unprecedented opportunities to showcase completed deliverables, synthesize stakeholder feedback intelligence, and celebrate milestone achievements. The sprint retrospective functions as a dedicated optimization window for teams to analyze operational processes, evaluate successful methodologies, and identify enhancement opportunities—ensuring the working agreement evolves dynamically as the organizational unit matures and scales.
To architect truly effective working agreement frameworks, teams must strategically consider multifaceted variables including diverse geographical time zone distributions, virtual whiteboard collaboration technologies, and individualized communication preferences alongside distinctive work style methodologies. Systematically revisiting and optimizing the working agreement infrastructure—particularly following retrospective analysis sessions—ensures it maintains relevance as a dynamic, living document that adapts to the team's evolving operational requirements and emerging organizational challenges.
It's essential to start with core guidelines that everyone can agree upon when drafting working agreements. These agreements can be improved as a team grows older, laying a solid foundation for difficult B2B cooperation. Team members can concentrate on what's essential and prevent confusion or misunderstandings by keeping things simple.
Involving all team members in formulating the working agreements is crucial to ensuring everyone is committed to them. This strategy fosters a sense of ownership and promotes teamwork. When working on B2B initiatives, inclusivity provides a well-rounded viewpoint that can produce superior results.
To guarantee comprehension and consistency, a centralized document that is available to all team members must be maintained. This paperwork is very helpful in B2B partnerships because accountability is so important. Team members can operate more effectively and avoid misunderstandings by having a single source of truth.
Maintaining continued relevance requires routinely reviewing and revising agreements to reflect changing team dynamics. This agility is crucial in the constantly evolving B2B environment. Teams may maintain focus and ensure everyone is on the same page and working toward the same objectives by routinely reviewing agreements.
To guarantee seamless integration into the team's collaborative standards when new team members join a project, it's crucial to introduce them to the working agreements. Rapid onboarding is essential for B2B cooperation to keep the project moving forward. When new team members join, it is crucial to introduce them to the existing working agreement. Teams can prevent delays and keep the project moving ahead by swiftly bringing new members up to speed.
The following essential qualities should be taken into account to foster teamwork through working agreements:
Be careful to display the agreements in a visible location in the workplace. This makes it easier to refer to established norms and align behaviors with them. Visible agreements provide constant reminders of the team's commitments. Feedback loops such as one-on-one meetings, and regular check-ins help ensure that these agreements are actively followed and adjusted, if needed.
Create agreements that are clear-cut and simple to grasp. All team members are more likely to obey and abide by clear and simple guidelines. Simpler agreements reduce ambiguity and uncertainty, hence fostering a culture of continuous improvement.
Review and revise the agreements frequently to stay current with the changing dynamics of the team. The agreements' adaptability ensures that they will continue to be applicable and functional over time. Align it further with retrospective meetings; where teams can reflect on their processes and agreements as well as take note of blind spots.
Develop a sense of shared responsibility among team members to uphold the agreements they have made together. This shared commitment strengthens responsibility and respect for one another, ultimately encouraging collaboration.
Once you have created your working agreements, it is crucial to enforce them to see effective results.
Here are five strategies to enforce the working agreements.
Use automated tools to enforce the code-related aspects of working agreements. Automation ensures consistency reduces errors, and enhances efficiency in business-to-business projects.
Code reviews and retrospectives help reinforce the significance of teamwork agreements. These sessions support improvement. Serve as platforms for upholding established norms.
Foster a culture of peer accountability where team members engage in dialogues and provide feedback. This approach effectively integrates working agreements into day-to-day operations.
Incorporate check-ins, stand-up meetings, or retrospective meetings to discuss progress and address challenges. These interactions offer opportunities to rectify any deviations from established working agreements.
Acknowledge and reward team members who consistently uphold working agreements. Publicly recognizing their dedication fosters a sense of pride. Further promotes an environment.
Teams can greatly enhance their dedication to working agreements. Establish an atmosphere that fosters project collaboration and success by prioritizing these strategies.
Leveraging team working agreements comprises a transformative approach toward establishing high-performing agile teams, yet numerous systematic pitfalls frequently undermine their operational effectiveness. The primary obstacle involves failing to facilitate comprehensive team member participation throughout the creation process. When only a subset comprises the drafting team, this approach generates diminished ownership and reduced commitment from remaining personnel. To optimize this process, organizations must ensure team members actively participate by analyzing individual perspectives, generating innovative concepts, and contributing systematically to the final documentation.
Another prevalent deficiency involves treating team working agreements as static documentation rather than dynamic, evolving frameworks. Agile teams and project teams continuously transform over operational periods, necessitating corresponding agreement adaptations. Systematically revisiting and updating these agreements ensures they maintain relevance and continue facilitating the team's operational methodologies and strategic objectives.
Teams must exercise caution to avoid implementing overly rigid agreement structures. Flexibility comprises an essential component for fostering innovation and adapting to emerging challenges. Organizations should avoid establishing parameters that inhibit creative processes or complicate procedural adjustments as teams expand and acquire new competencies.
Additionally, neglecting to establish comprehensive expectations for communication protocols, collaborative frameworks, and conflict resolution mechanisms generates misunderstandings and operational friction. The agreement must provide systematic guidelines that define team collaboration methodologies, disagreement resolution processes, and mutual support structures.
By systematically avoiding these prevalent deficiencies, teams can develop working agreements that authentically support operational collaboration, facilitate team member contribution of innovative concepts, and adapt to the continuously evolving requirements of both team dynamics and project specifications.
A meticulously architected agile team working agreement encompasses comprehensive operational protocols that facilitate collaborative workflows, streamline communication channels, and optimize value delivery mechanisms. The following framework illustrates the essential components that such an agreement should encompass:
This comprehensive framework can be customized and adapted to align with the distinctive operational requirements and stakeholder preferences of your specific organizational unit. The most effective team working agreements are developed through collaborative stakeholder engagement, incorporating comprehensive input from all team participants, and undergo regular evaluation cycles to ensure continued relevance and strategic support for the team's evolving operational objectives.
Product Team Collaboration and Working Agreements represent critical components that fundamentally reshape how cross-functional teams operate within agile development environments. By establishing comprehensive frameworks for communication protocols, workflow optimization, and stakeholder engagement patterns, working agreements enhance operational efficiency, delivery predictability, and strategic alignment across all product development phases. Let's explore the transformative impact of structured collaboration frameworks and examine essential components for streamlining product team workflows.
A robust working agreement framework for product teams should comprehensively outline collaborative methodologies for user story development, product backlog refinement processes, and stakeholder communication protocols. This involves defining specific operational parameters and establishing clear accountability matrices that ensure seamless workflow execution.
Encouraging collaborative knowledge exchange among team members serves as a vital catalyst for continuous improvement initiatives and innovation acceleration. The agreement framework should systematically create structured environments for open discourse, whether during daily stand-up ceremonies, sprint retrospective sessions, or ad hoc ideation workshops. This involves establishing psychological safety protocols and communication guidelines that enable comprehensive idea exploration.
Additionally, comprehensive working agreements should establish precise communication expectation matrices—including stakeholder update distribution mechanisms, decision documentation protocols, and information architecture standards. This systematic approach ensures optimal alignment across all team members, from software developers to product owners, maintaining strategic objective coherence and operational transparency.
By implementing tailored working agreement frameworks, product teams can significantly enhance collaborative efficiency, streamline operational processes, and deliver sophisticated products that simultaneously address user experience requirements and business strategic objectives. Regular framework assessment and optimization cycles ensure continuous alignment with evolving team dynamics, technological advancement patterns, and organizational growth trajectories, maintaining sustained competitive advantage and delivery excellence.
Collaboration plays a role in B2B software development. Agile Team Working Agreements are instrumental in promoting collaboration. This guide highlights the significance of these agreements, explains how to create them, and offers practices for their implementation.
By crafting these agreements, teams establish an understanding and set expectations, ultimately leading to success. As teams progress, these agreements evolve through retrospectives and real-life experiences, fostering excellence, innovation, and continued collaboration.
To optimize team performance in establishing and maintaining comprehensive working agreements, organizations can leverage an extensive ecosystem of methodological resources and specialized frameworks. Agile transformation consultancies and certified coaching organizations provide sophisticated template libraries, detailed implementation blueprints, and systematic guidance protocols that enable teams to initiate robust collaborative frameworks.
Comprehensive training platforms and specialized workshops focused on team dynamics optimization, communication pattern analysis, and agile methodology integration deliver practical implementation strategies and hands-on experience with proven collaboration techniques.
Engaging with certified scrum masters or experienced agile transformation coaches provides substantial value through their specialized expertise in facilitating structured discussions, implementing conflict resolution protocols, and ensuring working agreement alignment with established agile best practices and organizational maturity models.
Knowledge acquisition from high-performing teams through industry conferences, professional meetups, and specialized webinar series offers valuable insights and validated strategies for developing and continuously evolving team collaboration agreements that drive measurable performance improvements.
Organizations must recognize that working agreements function as dynamic documentation requiring systematic review cycles and iterative updates to accommodate evolving team compositions, project requirements, and organizational transformation initiatives.
Through strategic utilization of these comprehensive resources and sustained commitment to continuous improvement methodologies, teams can establish working agreements that enable enhanced collaboration patterns, accountability frameworks, and sustainable long-term performance optimization across multiple delivery cycles.
Whether initiating the development of foundational working agreements or implementing refinement strategies for existing collaborative frameworks, these specialized resources provide essential guidance and proven methodologies necessary for establishing robust foundations that support high-performance agile teamwork and organizational transformation objectives.
.png)
For every project, whether delivering a product feature or fulfilling a customer request, you want to reach your goal efficiently. But that’s not always simple – choosing the right method can become stressful. Whether you want to track the tasks through story points or hours, you should fully understand both of them well.
Therefore in this blog, story points vs. hours, we help you decide.
When it comes to Agile Software Development, accurately estimating the effort required for each task is crucial. To accomplish this, teams use Story Points, which are abstract units of measurement assigned to each project based on factors such as complexity, amount of work, risk, and uncertainty.
These points are represented by numerical values like 1, 2, 4, 8, and 16 or by terms like X-Small, Small, Medium, Large, and Extra-Large. They do not represent actual hours but rather serve as a way for Scrum teams to think abstractly and reduce the stress of estimation. By avoiding actual hour estimates, teams can focus on delivering customer value and adapting to changes that may occur during the project.
When estimating the progress of a project, it's crucial to focus on the relative complexity of the work involved rather than just time. Story points help with this shift in perspective, providing a more accurate measure of progress.
By using this approach, collaboration and shared understanding among team members can be promoted, which allows for effective communication during estimation. Additionally, story points allow for adjustments and adaptability when dealing with changing requirements or uncertainties. By measuring historical velocity, they enable accurate planning and forecasting, encouraging velocity-based planning.
Overall, story points emphasize the team's collective effort rather than individual performance, providing feedback for continuous improvement.
Project management can involve various methodologies and estimating work in terms of hours. While this method can be effective for plan-driven projects with inflexible deadlines, it may not be suitable for projects that require adaptability and flexibility. For product companies, holding a project accountable has essential.
Hours provide stakeholders with a clear understanding of the time required to complete a project and enable them to set realistic expectations for deadlines. This encourages effective planning and coordination of resources, allocation of workloads, and creation of project schedules and timelines to ensure everyone is on the same page.
One of the most significant advantages of using hours-based estimates is that they are easy to understand and track progress. It provides stakeholders with a clear understanding of how much work has been done and how much time remains. By multiplying the estimated hours by the hourly rate of resources involved, project costs can be estimated accurately. This simplifies billing procedures when charging clients or stakeholders based on the actual hours. It also facilitates the identification of discrepancies between the estimated and actual hours, enabling the project manager to adjust the resources' allocation accordingly.
Estimating the time and effort required for a project can be daunting. The subjectivity of story points can make it challenging to compare and standardize estimates, leading to misunderstandings and misaligned expectations if not communicated clearly.
Furthermore, teams new to story points may face a learning curve in understanding the scale and aligning their estimations. The lack of a universal standard for story points can create confusion when working across different teams or organizations.Additionally, story points may be more abstract and less intuitive for stakeholders, making it difficult for them to grasp progress or make financial and timeline decisions based on points. It's important to ensure that all stakeholders understand the meaning and purpose of story points to ensure everything is understood.
Relying solely on hours may only sometimes be accurate, especially for complex or uncertain tasks where it's hard to predict the exact amount of time needed. This approach can also create a mindset of rushing through tasks, which can negatively affect quality and creativity.
Instead, promoting a collaborative team approach and avoiding emphasizing individual productivity can help teams excel better.
Additionally, hourly estimates may not account for uncertainties or changes in project scope, which can create challenges in managing unexpected events.
Lastly, sticking strictly to hours can limit flexibility and prevent the exploration of more efficient or innovative approaches, making it difficult to justify deviating from estimated hours.
It can be daunting to decide what works best for your team, and you don’t solely have to rely on one solution most of the time - use a hybrid approach instead.
When trying to figure out what tasks to tackle first, using story points can be helpful. They give you a good idea of how complex a high-level user story or feature is, which can help your team decide how to allocate resources. They are great for getting a big-picture view of the project's scope.
However, using hours might be a better bet when you're working on more detailed tasks or tasks with specific time constraints. Estimating based on hours can give you a much more precise measure of how much effort something will take, which is important for creating detailed schedules and timelines. It can also help you figure out which tasks should come first and ensure you're meeting any deadlines that are outside your team's control. By using both methods as needed, you'll be able to plan and prioritize more effectively.
Sign up now and you’ll be up and running on Typo in just minutes

We're on a mission to build engaged, productive tech teams. Try it out for free!


Follow us on:
We're on a mission to build engaged, productive tech teams. Try it out for free!
Follow us on:







